TensorFlow入門
Shrimp Chen 2018/10/12

Fig 1. TensorFlow流程圖(重畫)
Fig. 1說明TensorFlow為向量從圖的一端流動到另一端計算過程。Tensor(張量)代表N維陣列,Flow(流)則是資料流圖的計算,TensorFlow支援CNN, RNN, 和LSTM等的演算法,這些深度神經網路模型可用在影像、語音和自然語言處理。
Tensor是tensorflow最基礎的資料,陣列的維度稱為rank,以下是四個tensors的範例:
| 範例 | 說明 |
|---|---|
| 3 | 一個 rank 為 0 的 tensor,形狀為 [ ] 的常數 |
| [1. ,2., 3.] | 一個 rank 為 1 的 tensor,形狀為 [3] 的向量 |
| [[1., 2., 3.], [4., 5., 6.]] | 一個 rank 為 2 的 tensor,形狀為 [2, 3] 的陣列 |
| [[[1., 2., 3.]], [[7., 8., 9.]]] | 一個 rank 為 3 的 tensor,形狀為 [2, 1, 3] 的陣列 |
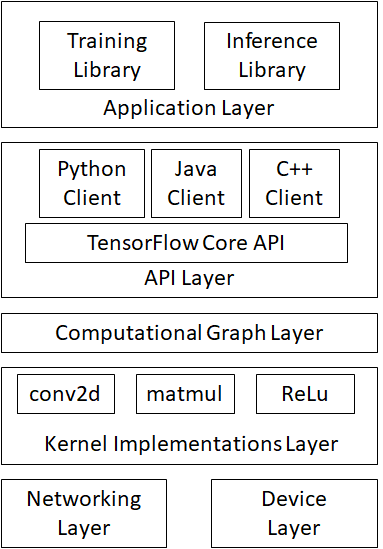
Fig. 2 TensorFlow系統架構圖
Fig. 2 說明整個TensorFlow的系統架構。從底層開始看起,由下而上來看,網路層(Networking Layer)是分散式運算時需要用到的。
裝置層(Device Layer)包含TensorFlow負責處理CPU、GPU、FPGA的運算。
資料操作層(Kernel Implementations Layer),包含建置神經網路所需的神經元函式如conv2d (Convolution Function), matmul, Relu, Activation Function、等。
圖計算層(Computational Graph Layer)處理圖的建立、編譯、最佳化和執行。其中又分本機計算圖和分散式運算圖。
TensorFlow API layer 處理模型對外的接口。
包含client session、input、output的處理。
一個clientSession物件讓呼叫者可以調用C++對tensorflow圖的運算。
(ClientSession object lets the caller drive the evaluation of the Tensorflow graph constructed with the C++)[1].
Tensorflow Application Layer 提供多種library,包含training與inference用途的library。
library的例子包含tensorflow、tensorlearn、keras、tensorlayer等。
建立與執行計算圖(Computational Graph)
計算圖是由許多Tensorflow運算節點所組成的運算圖,每個運算節點可以接受其中任意個tensors(或沒有任何的輸入)做為inputs,並且輸出一個tensor。其中包含兩個部份:建立計算圖(part 1)和執行計算圖(part 2)。以下利用一個簡單的線性回歸模型來講解。
Part 1. 建立「計算圖」就是設計向量運算流程,並且建構各種機器學習模型。
匯入TensorFlow模組
import tensorflow as tf
建立TensorFlow 變數節點
W = tf.Variable([.3], dtype = tf.float32)
b = tf.Variable([-.3]) # 預設型別亦為 tf.float32
tf.Variable建立一個變數 W,其值為0.3,另外一個變數b的值為-0.3,透過Variable節點來指定參數W和b,這樣可以讓參數進行訓練。
輸出出tensor格式
print(W, b)
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
print ( )輸出W和b的格式型態
輸入與輸出資料
x = tf.placeholder(tf.float32)
y = W * x + b
placeholder讓模型可以輸入各種資料
Part 2. 執行「計算圖」
在TensorFlow中「Session」的作用是在用戶端和執行裝置之間建立連結。
此連結可以將「計算圖」在各種不同裝置中執行。任何裝置間的資料傳遞,都必須透過Session才能進行。
執行「計算圖」後會將結果回傳。
建立session
sess = tf.Session()
使用tf.Session()建立session物件sess。
設定TensorFlow起始化變數init
init = tf.global_variables_initializer()
使用tf.global_variables_initializer()建立物件init。
使用sess.run可用來啟動init
sess.run(init)
回歸模型驗證輸出
print(sess.run(y, {x:[1,2,3,4]}))
將x=1~4分別帶入y = W * x + b中,得到結果[ 0. 0.30000001 0.60000002 0.90000004]。
評估模型好壞
y_hat = tf.placeholder(tf.float32)
y_hat是用來評估 y的好壞,y_hat儲存的是正確答案。
設定loss function
squared_deltas = tf.square(y - y_hat)
loss = tf.reduce_sum(squared_deltas)
#也可寫成下列這個式子
# loss = tf.reduce_sum(tf.square(y - y_hat))
tf.square 計算每個誤差的平方,reduce_sum 是把平方後的誤差加總,整個步驟稱做sum of squares(離均差平方和)
tf.train API
建好模型之後,要利用既有的資料對模型進行訓練。Tensorflow提供各種optimizers可對模型的variables進行微調,使得loss function最小。
建立gradient descent optimizer,並指定 loss function
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
設定訓練資料
x_train = [1, 2, 3, 4]
y_train = [0, -1, -2, -3]
使用迴圈訓練模型
for i in range(1000):
sess.run(train, {x:x_train, y:y_train})
輸出最佳的模型結果
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
tf.contrib.learn API
tf.contrib.learn 是一個高階的 TensorFlow API,可以處理模型的訓練與評估等各種常用的機器學習工作。
以下是使用 tf.contrib.learn 來實作線性迴歸模型的完整程式碼:
import tensorflow as tf
# NumPy 時常用於載入與整理資料
import numpy as np
# 宣告特徵(fetures),此例中只有一個實數的特徵
features = [tf.contrib.layers.real_valued_column("x", dimension=1)]
# 定義模型,此例使用線性迴歸模型
estimator = tf.contrib.learn.LinearRegressor(feature_columns=features)
# 定義資料,並指定 batch 與 epochs 的大小
x_train = np.array([1., 2., 3., 4.])
y_train = np.array([0., -1., -2., -3.])
x_eval = np.array([2., 5., 8., 1.])
y_eval = np.array([-1.01, -4.1, -7, 0.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x_train}, y_train,
batch_size = 4,
num_epochs = 1000)
eval_input_fn = tf.contrib.learn.io.numpy_input_fn(
{"x":x_eval}, y_eval, batch_size = 4, num_epochs = 1000)
# 進行模型的訓練
estimator.fit(input_fn = input_fn, steps = 1000)
# 驗證模型
train_loss = estimator.evaluate(input_fn=input_fn)
eval_loss = estimator.evaluate(input_fn=eval_input_fn)
print("train loss: %r"% train_loss)
print("eval loss: %r"% eval_loss)
自訂模型
tf.contrib.learn也允許使用者自訂模型,以下是自訂模型的範例:
import numpy as np
import tensorflow as tf
# 自訂模型
def model(features, labels, mode):
# 建立線性迴歸模型
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W * features['x'] + b
# loss function 的 sub-graph
loss = tf.reduce_sum(tf.square(y - labels))
# 訓練的 sub-graph
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# 使用 ModelFnOps 將建立的 subgraphs 包裝好
return tf.contrib.learn.ModelFnOps(
mode=mode, predictions=y,
loss=loss,
train_op=train)
# 定義模型
estimator = tf.contrib.learn.Estimator(model_fn=model)
# 定義資料,並指定 batch 與 epochs 的大小
x_train = np.array([1., 2., 3., 4.])
y_train = np.array([0., -1., -2., -3.])
x_eval = np.array([2., 5., 8., 1.])
y_eval = np.array([-1.01, -4.1, -7, 0.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x_train}, y_train, 4, num_epochs=1000)
eval_input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x_eval}, y_eval, batch_size = 4, num_epochs = 1000)
# 進行模型的訓練
estimator.fit(input_fn=input_fn, steps=1000)
# 驗證模型
train_loss = estimator.evaluate(input_fn=input_fn)
eval_loss = estimator.evaluate(input_fn=eval_input_fn)
print("train loss: %r"% train_loss)
print("eval loss: %r"% eval_loss)
[0] https://blog.gtwang.org/statistics/tensorflow-google-machine-learning-software-library-tutorial/
[1]
https://www.tensorflow.org/api_docs/cc/group/core#summary