Acoustic model
Basic Approach to Speech Recognition
A speech recognition system transforms a piece of speech into a sentence. The input is the speech signal and the output is a sequence of words.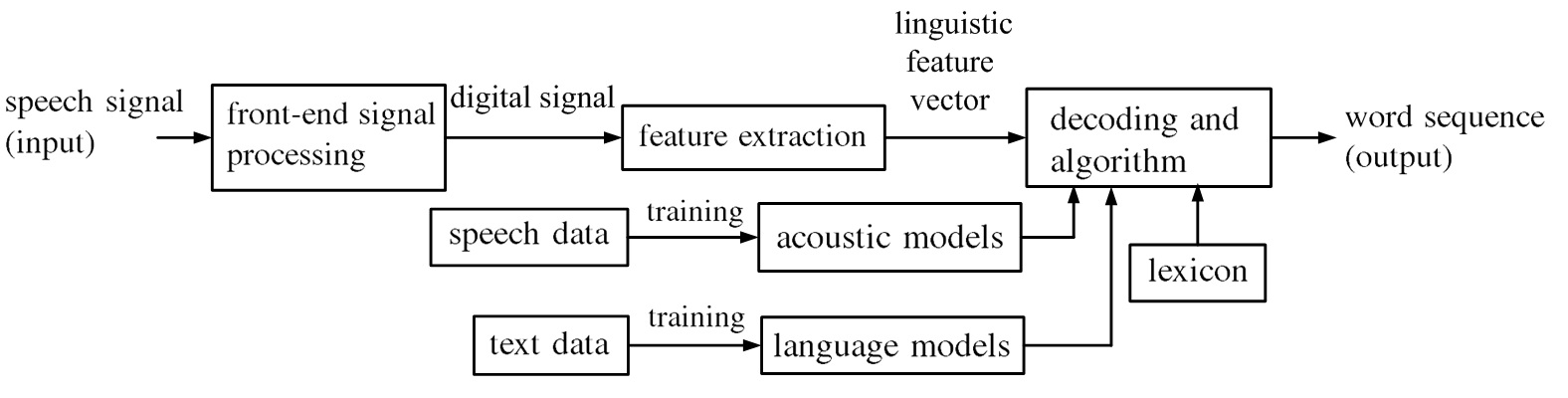
Fig.1. Schematic of speech recognition
Fig.1. shows the schematic to implement a speech recognition process. A front-end signal processing transform the signal from the real world into the digital signals. The feature extraction process extracts the linguistic features from the digital signals. These linguistic features are represented by vectors. Computers output the most appropriate word sequence from features vectors by the trained acoustic models, the lexicon, and the trained language models.
The acoustic models predict the phonemes or syllables from the feature vectors.
The lexicon is a database to form basic phonetic unit into words.
The language models are to predict the appropriate sentence from the possible word sequences. Both the acoustic models and language models can be trained by machine learning, and the lexicon has done by linguists.
Acoustic Model
An acoustic model can be implemented by an Hidden Markov Model (HMM)[1], which is shown by the figure below.
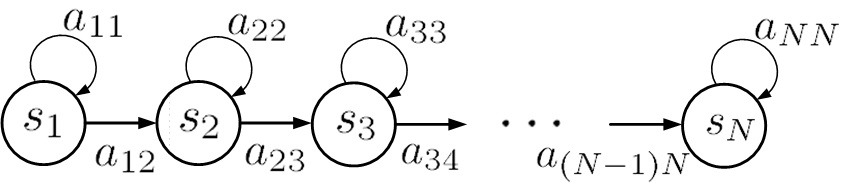
Fig.2. State diagram of HMM for acoustic model.
An HMM is a statistical model in which the modeled system is assumed to be a sequence with unobserved (i.e. hidden) states. The states can represent a piece of speech. The number of the states is proportional to the sound changes of the speech.
(AnAn: the HMM is a big topic that I have not understand it.)
Unit Selection Principles of Sound
Speech signal is complicated. The units of sound can be word, syllable, phoneme.

Fig.3. Schematic of words, syllables and phonemes.
Fig.3 shows schematic of words, syllables and phonemes, which are the three typical units of sounds defined by linguists. A syllable includes 1 vowel and zero or more consonants, and a phoneme stands for 1 vowel or 1 consonant.
For example, the word 媽媽 has two syllables, and has four phonemes。
For another example, the word ‘student’ has 2 syllables, ‘stu’ and ‘dent’, and has 8 phonemes, that is [s], [t], [j],[ ʊ],[d],[ ə],[n],[t].
The units of sounds selection consider as follow.
Accuracy: the selected unit can descript the phone accurately.
Trainability: the data is enough for model training.
Generalizability: the selected unit can form into most of the words.

Fig.4. Example of different unit selection of sound for "cat". (a) "cat" as a syllable, (b) "cat" as 3 phonemes.
Words and phonemes are the extreme cases among these units of sounds. A word usually consists of many phonemes that can carry a lot of information for high accuracy. However, collecting words for training is difficult and the trained words cannot form other new words resulting in poor generalizability. Phonemes are most basic units of sounds and are easy to be collected. The trained phonemes can form most of words or syllables result in good generalizability. However, the pronunciation of a phoneme varies by its adjacent phonemes, both front and back, which result in poor accuracy.
[0] 數位語音處理概論 第五章 Acoustic Model, 李琳山 https://www.youtube.com/watch?time_continue=226&v=j0gQ8K3QjWU
[1] Phonemes are the minimum units of speech sound in a language which can serve to distinguish one word from the other. For example, the phonetic alphabets [p] and [b] are the pronunciation of the first phoneme of the words “pat” and “bat”.