Optimization
Machine Learning Model

Fig.1 Schematic of Machine learning model, label data and loss function L.
Fig.1 shows the schematic of machine learning model, label data y^ and loss function L.
The machine learning model are characterized by the weight w¯¯ and bias b¯.
x¯ is the input data, and y¯ is the output data. y¯ can be also seen as the model prediction.
y^ is the label data. Loss function measure the distance between model prediction y¯ and label data y^.
The target of machine learning is to find the model (usually characterized with w¯¯ and b¯) with the model prediction y¯ close to y^.
In other words to minimize the loss function value L.
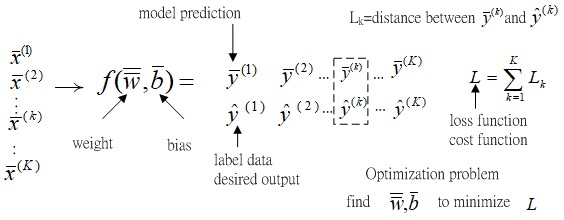
Fig.2 schematic of Machine learning frame work as an optimization problem.
Fig.2 shows the schematic of machine learning frame work as an optimization problem.
x¯(1),x¯(2),⋯,x¯(k),⋯,x¯(K)are K dataset, and y¯(1),y¯(2),⋯,y¯(k),⋯,y¯(K)are its corresponding model predictions.
y^(1),y^(2),⋯,y^(k),⋯,y^(K)are the corresponding label datum.
Lk refers to the distance between the kth model prediction y¯(k) and label data y^(k).
The loss function L is defined as the over all K data, L=k=1∑KLk.
The machine learning can be seen as the optimization problem:
Find w¯¯ s and b¯ to minimize the loss function value L.
w¯¯,b¯=w¯¯,b¯minL
The gradient descent is applied to solve this optimization problem.
Gradient descent
The update rule based on gradient descent can be expressed as
w(t)=w(t−1)−η∂w∂L.
where η is the learning rate.
One dimension example
Assuming the loss function is obtained as L(w)=w2, we can derive ∂w∂L=2w.
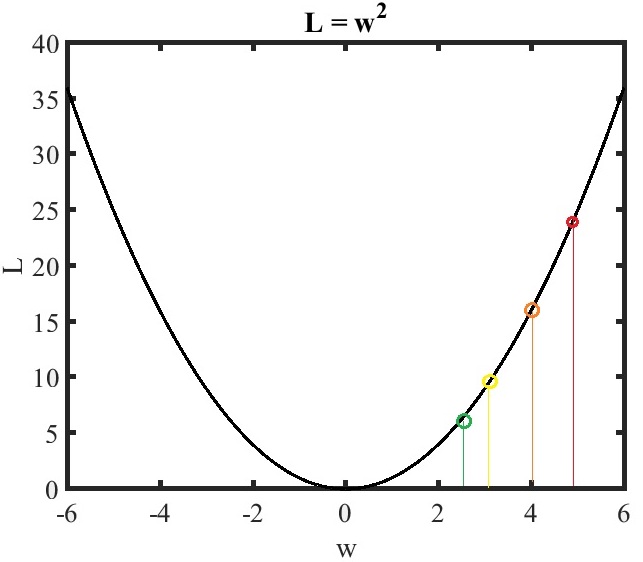
Fig.3 Gradient decent example 1 with η=0.1.
If w is initialized as 5, w(t=0)=5, we derive ∂w∂L=2w(0)=2×5=10.
Assuming the learning rate η=0.1, the w at time 1,t=1, is updated as
w(1)=w(0)−0.1×2×5=5−1=4
the w at time 2,t=2, is updated as
w(2)=w(1)−0.1×2×4=4−0.8=3.2
the w at time 3,t=3, is updated as
w(3)=w(2)−0.1×2×3.2=3.2−0.64=2.56
As time goes infinity, the w(t→∞)=0.
considering larger learning rate
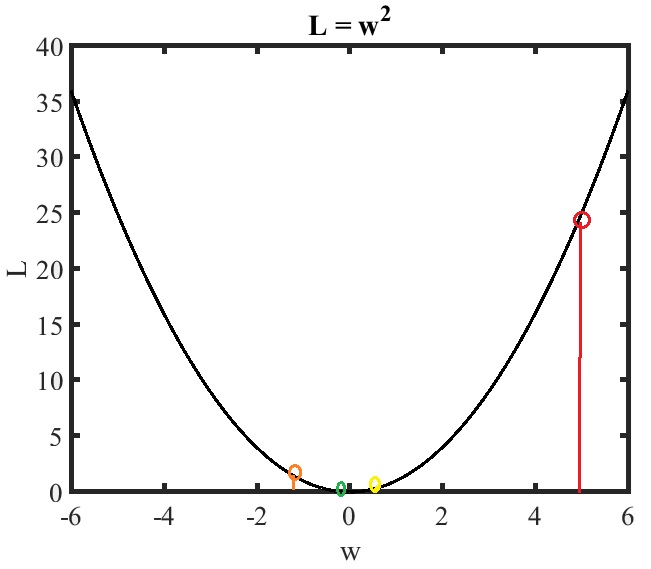
Fig.4 Gradient decent example 1 with η=0.6.
Considering a larger learning rate η=0.6,
the w at time 1,t=1, is updated as
w(1)=w(0)−0.6×2×5=5−6=−1
the w at time 2,t=2, is updated as
w(2)=w(1)−0.6×2×(−1)=(−1)−(−1.2)=0.2
the w at time 3,t=3, is updated as
w(3)=w(2)−0.6×2×(0.2)=0.2−0.24=−0.04
As time goes infinity, the w(t→∞)=0.
The convergence rate with η=0.6 is larger than that with η=0.1 in this illustrative example.
considering a even larger learning rate
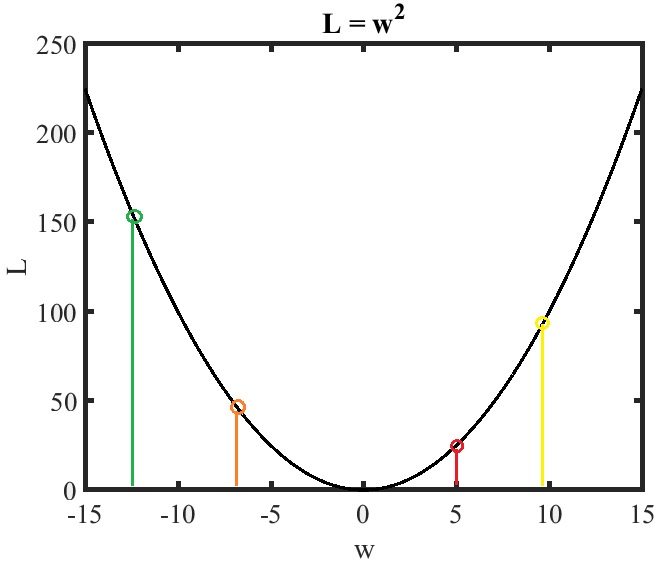
Fig.5 Gradient decent example 1 with η=1.2.
Considering a even larger learning rate η=1.2,
the w at time 1,t=1, is updated as
w(1)=w(0)−1.2×2×5=5−12=−7
the w at time 2,t=2, is updated as
w(2)=w(1)−1.2×2×(−7)=(−7)−(−16.8)=9.8
the w at time 3,t=3, is updated as
w(3)=w(2)−1.2×2×(9.8)=9.8−23.52=−13.72
As time goes infinity, the w(t→∞).will diverge.