Word Embedding
Distributed representations (embeddings) are mainly learnt through context. During 1990s, several research developments marked the foundataions of research in distributional semantics. Later developments were adaptions of these early works, which led to creation of topic models like language models [1]. These works laid out the foundations of representation learning.
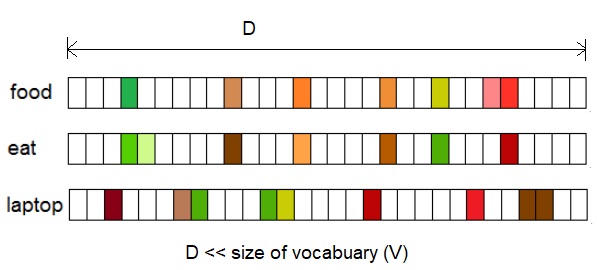
Fig.1 Distributional vectors represented by a D-dimensional vector where D << V, where V is size of Vocabulary.
Fig.1 shows that the distributed vectors or word embeddings.
Distributional vector and word embeddings.
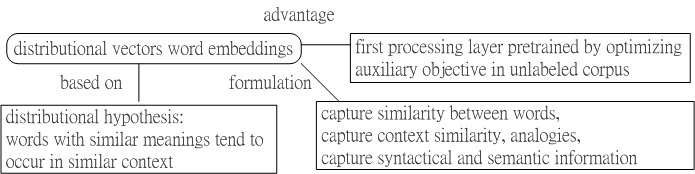
Fig.2 Schematic for distributional vector and word embeddings.
Fig.2 shows the schematic for distributional vector and word embeddings, which essentially follow the distributional hypothesis.
Distributional Hypothesis means that words are characterized by words they hang out with, and words with similar meanings tend to occur in similar context.
These vectors try to capture the characteristics of the neighbors of a word.
The main advantage of distributional vectors is that they capture similarity between words. Measuring similarity between vectors is possible, using measures such as cosine similarity.
Word embeddings are often used as the first data processing layer in a deep learning model.
Typically, word-embeddings are pre-trained by optimizing an auxiliary objective in a large unlabeled corpus, such as predicting a word based on its context, where the learnt word vectors can capture general syntactical and semantic information. Thus, these embeddings have proven to be efficient in capturing context similarity, analogies and due to its smaller dimensionality, are fast and efficient in computing core NLP tasks.
Over the years, the models that create such embeddings have been shallow neural networks and there has not been need for deep networks to create good embeddings.
However, deep learning based NLP models invariably represent their words, phrases and sentences using these embeddings.
This is in fact a major difference between traditional word-count based models and deep learning based models.
Word embeddings have been responsible for state-of-the-art results in a wide range of NLP tasks.
[0]
Young, Tom, et al. "Recent trends in deep learning based natural language processing." arXiv preprint arXiv:1708.02709 (2017).
[1]
Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin, ``A neural probablistic language model," Journal of machine learning research, vol.3, no.Feb, pp.1137-1155, 2003.
[2]
R. Collobert and J. Weston, ``A unified architecture for natural language processing: Deep neural networks with multitask learning," in Proceedings of the 25th international confer- ence on Machine learning. ACM, 2008, pp. 160-167.
[3]
T. Mikolov, K. Chen, G. Corrado, and J. Dean, ¡§Efficient estimation of word representations in vector space,¡¨ arXiv preprint arXiv:1301.3781, 2013.
[4]
J. Pennington, R. Socher, and C. D. Manning, ¡§Glove: Global vectors for word representation.¡¨ in EMNLP, vol. 14, 2014, pp. 1532-1543.