CBOW Model with Multi-word Context
The CBOW model predicts one target word by its context words [1].
Consider a vocabulary containing V words can be expressed as
V={d1,d2,⋯,dk,⋯,dV}
where dk is the k-th word in the vocabulary. The training corpus C can be constituted by Na articles as
C={article1,article2,⋯,articleNa}
.Each article is constituted by the words in the vocabulary V. For example,
article1=′d1 d5 d18 d56 d2 ⋯′
The C-word context of target word djo in an article is defined as
Cx(djo)={dcm∣dcm is the word in the context of djo,m=1,2,⋯,C}(1)
where the subscript cm can be the integers between 1 and V. For example, in article1, the first 4-word context of d18 is
Cx(d18)={dc1,dc2,dc3,dc4}={d1,d5,d56,d2}

Fig.1. Data flow of CBOW model with C-word context.x¯c1,⋯,x¯cC are the one-hot encoded vectors of words dc1,⋯,dcC and are input to the NN at the same time for CBOW model with C-word context. y¯ is the output of the NN. The input vectors v¯c1,⋯,v¯cC and output vector v¯j′ are two kinds of word vector representations.
Fig.1. shows the data flow of CBOW model with C-word context.The words in the context Cx(djo) are all one-hot encoded into x¯c1,⋯,x¯cC which are input to the neural network (NN) for the CBOW model.The output y¯=[y1,⋯,yj,⋯,yV]t has the size of V and yj is a probability that the target word is dj given the one-hot encoded vectors x¯cm, m=1,⋯,C. The input vectors v¯cm,m=1,⋯,C and output vector v¯j′ are two kinds of word vector representations and will be elaborated later.The NN is trained by inputting the articles in the training corpus C to the NN word by word.
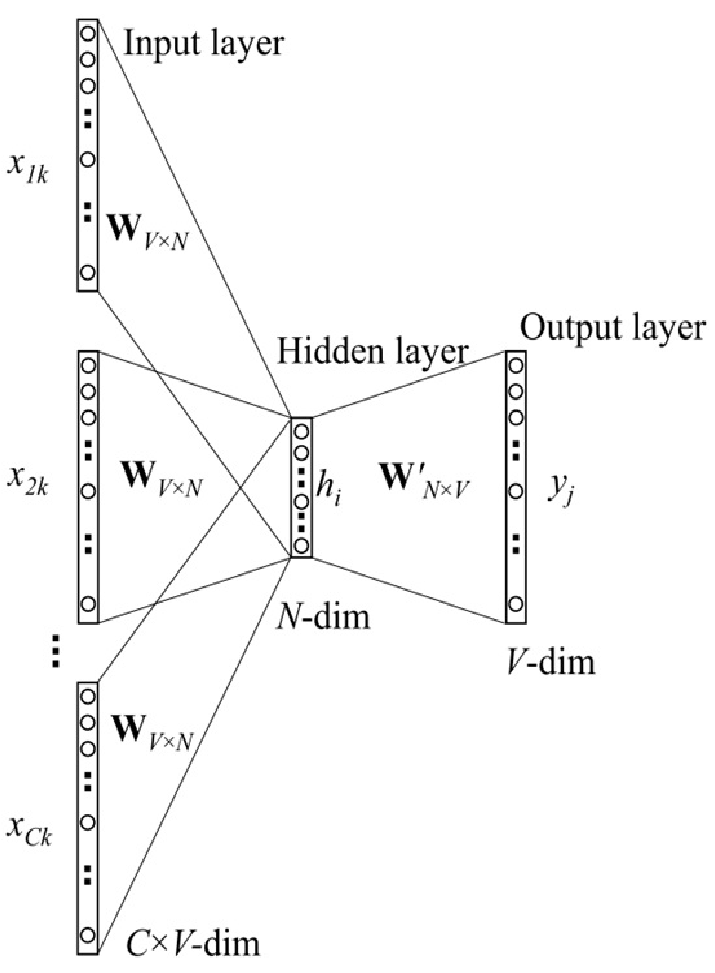
Fig.1. Architecture of the NN for CBOW model with C context words of the target word djo.
Fig.1. shows the architecture of the NN for CBOW model with C context words of the target word djo. A softmax function is still imposed at the end of the output layer.
The hidden layer output is calcuted as
h¯=C1W¯¯t⋅(x¯c1+x¯c2+⋯+x¯cC)=C1(v¯wc1+v¯wc2+⋯+v¯wcC)(2)
or represented component-wise as
hi=C1m=1∑Cwcmi, i=1,2,⋯,N(3)
The output of the neural network at j-th neuron is the probability of word wj given the context of wjo, namely,
yj=p(wj∣Cx(wjo))=j=1∑Vev¯wj′⋅h¯ev¯wj′⋅h¯(4)
The loss function is defined as
E=−lnp(wjo∣Cx(wjo))(5)
[0]
X. Rong, word2vec parameter learning explained, arXiv:1411.2738, 2014.
[1]
T. Mikolov, K. Chen, G. Corrado and J. Dean, Efficient estimation of word representations in vector space,
arXiv:1301.3781, 2013.