示意圖
再怎麼簡單的構念,有圖比沒圖好
Machine learning approaches targeting NLP problems have been based on shallow models (e.g., SVM and logistic regression) trained on high dimensional and sparse features.
Neural networks based on dense vector representations have been producing superior results on various NLP tasks. This trend is sparked by the success of word embeddings [1] and deep learning methods [2].
Deep learning enables multi-level automatic feature representation learning.
Traditional machine learning based NLP systems relies on hand-craft features which are time-consuming and incomplete.
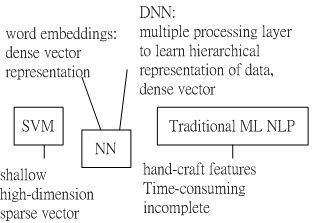
Fig.1 schematic of SVM (support vector machine), NN (neural network) and traditional machine learning based NLP system.
 Fig.1. Schematic of a word sequence and an article
Fig.1. Schematic of a word sequence and an article
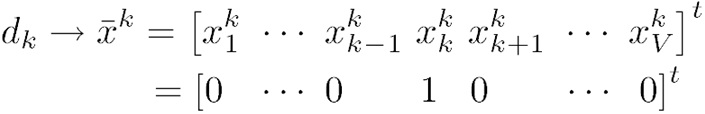 Fig.3 Schematic of one-hot encoding for -th word,
Fig.3 Schematic of one-hot encoding for -th word,
 Fig.4 Schematic of the target word under CBOW model of one-word context . (a) , . (b) , .
Fig.4 Schematic of the target word under CBOW model of one-word context . (a) , . (b) , .
 Fig.2 Schematic of module (model.py) file in pytorch chatbot example.
Fig.2 Schematic of module (model.py) file in pytorch chatbot example.
 Fig.3 Schematic of train.py file in pytorch chatbot example.
Fig.3 Schematic of train.py file in pytorch chatbot example.
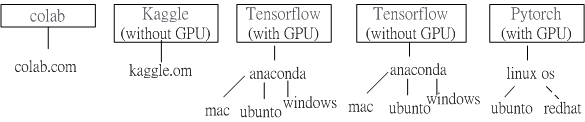 Fig.1 Schematic of machine learning framework dependency.
Fig.1 Schematic of machine learning framework dependency.
電腦畫的優於手畫的
手繪圖
對應的電腦繪圖

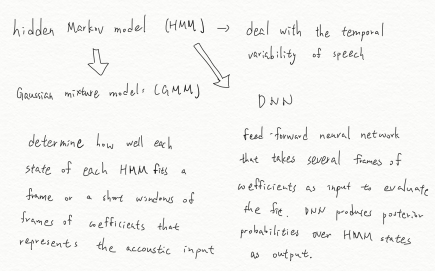
Fig. 1 Schematic for HMM (hidden Markov model), GMM (Gaussian mixture model) and DNN (Deep neural network). DNN serves an alternative way for GMM.
手繪圖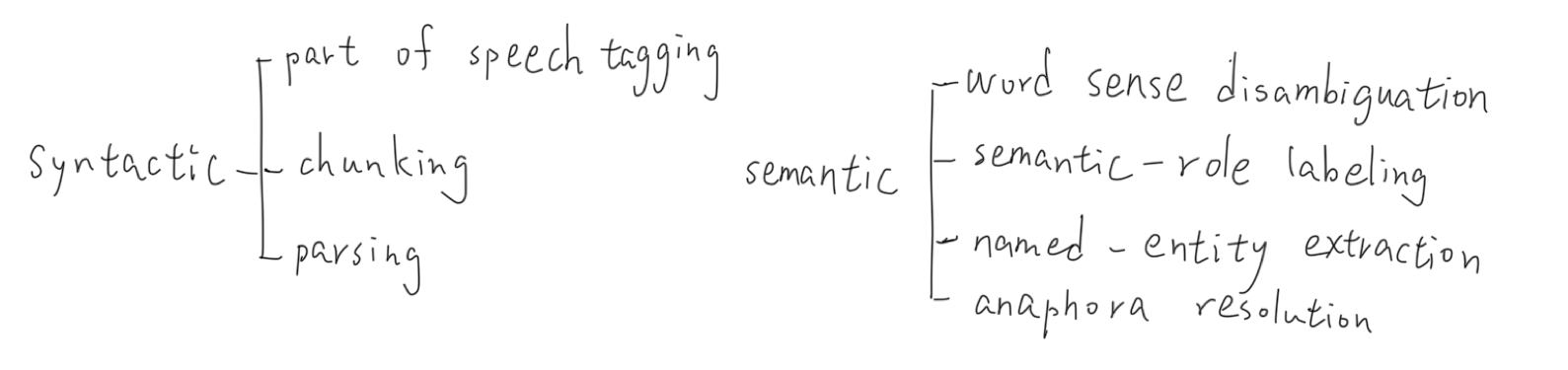 對應的電腦繪圖
對應的電腦繪圖
Fig. 1 Syntactic tasks and semantic tasks for NLP.
手繪圖
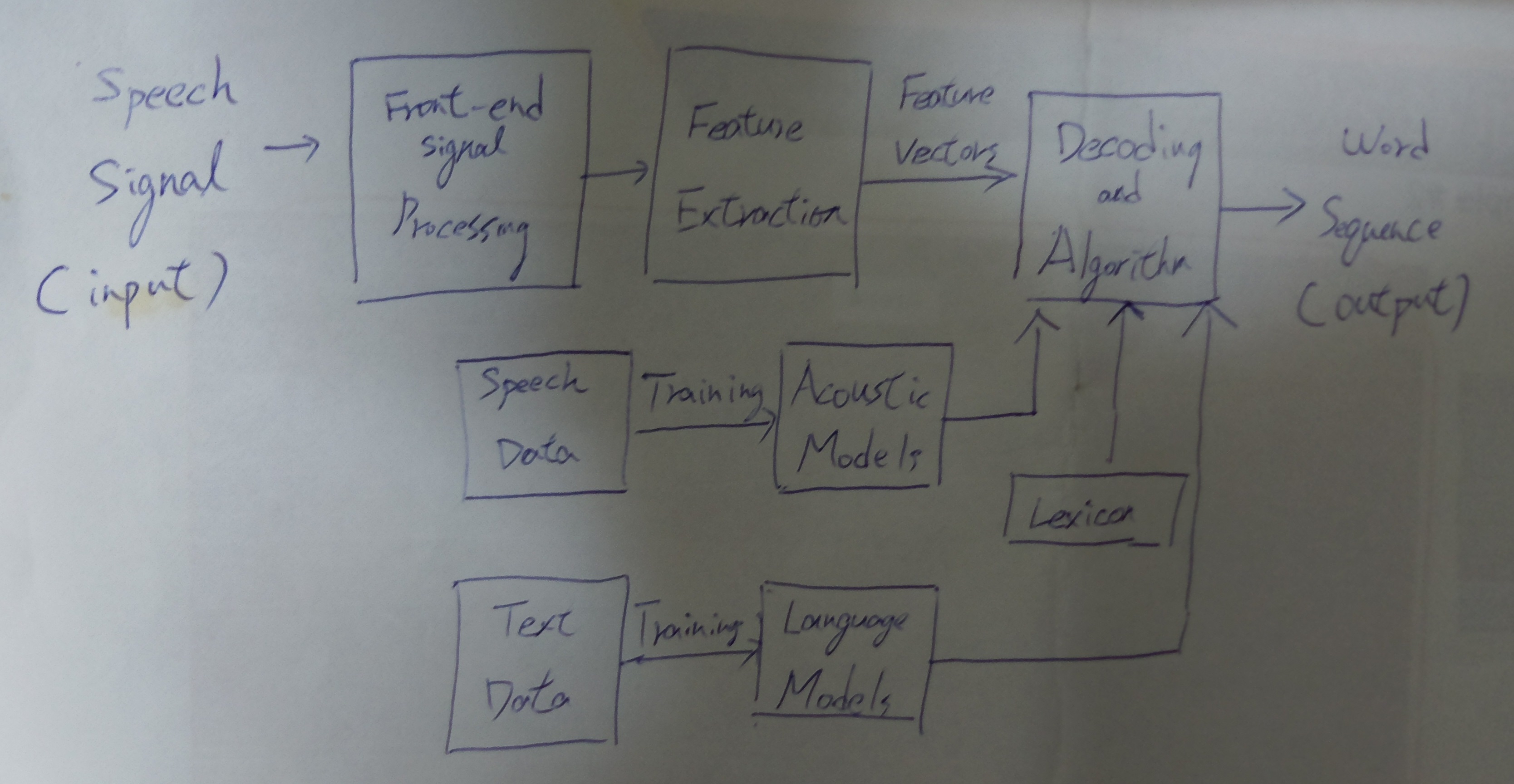
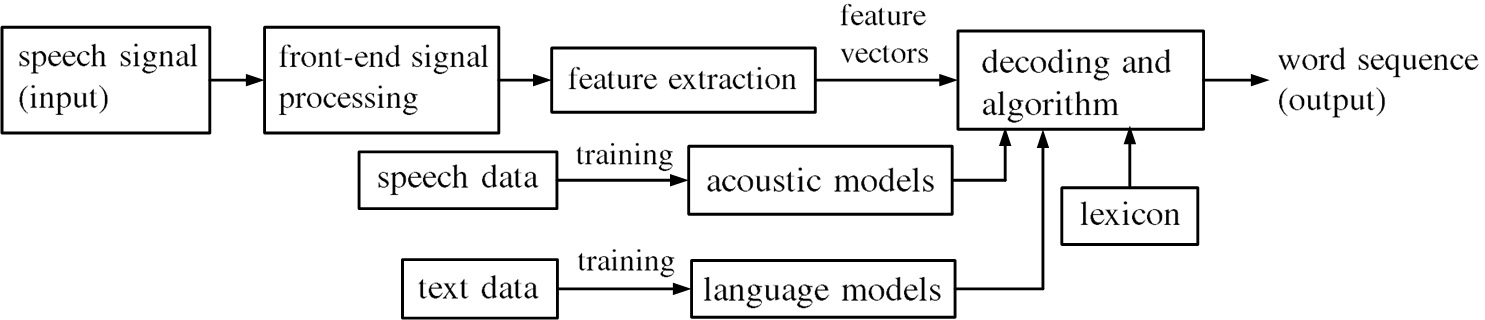 Fig.1. Schematic of Speech Recognition
Fig.1. Schematic of Speech Recognition
不同的邏輯角色賦予不同框框型式


Fig.1 statistical NLP v.s. deep learning model
真正在比的主題是statistical NLP與deep learning model, 所以應該他們兩個黑實方框。
圖上標上重要資訊
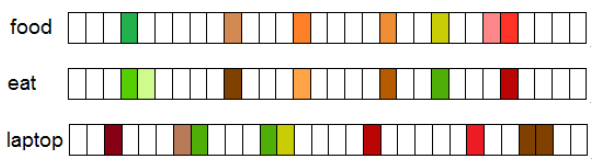
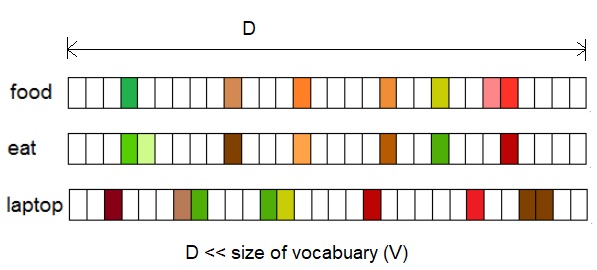
Fig.1 Distributional vectors represented by a D-dimensional vector where D << V, where V is size of Vocabulary.
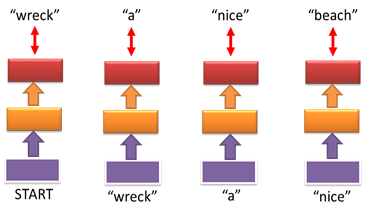
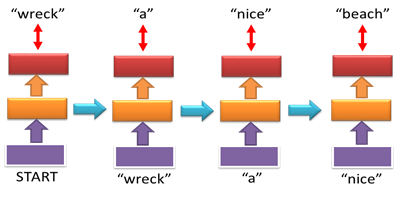
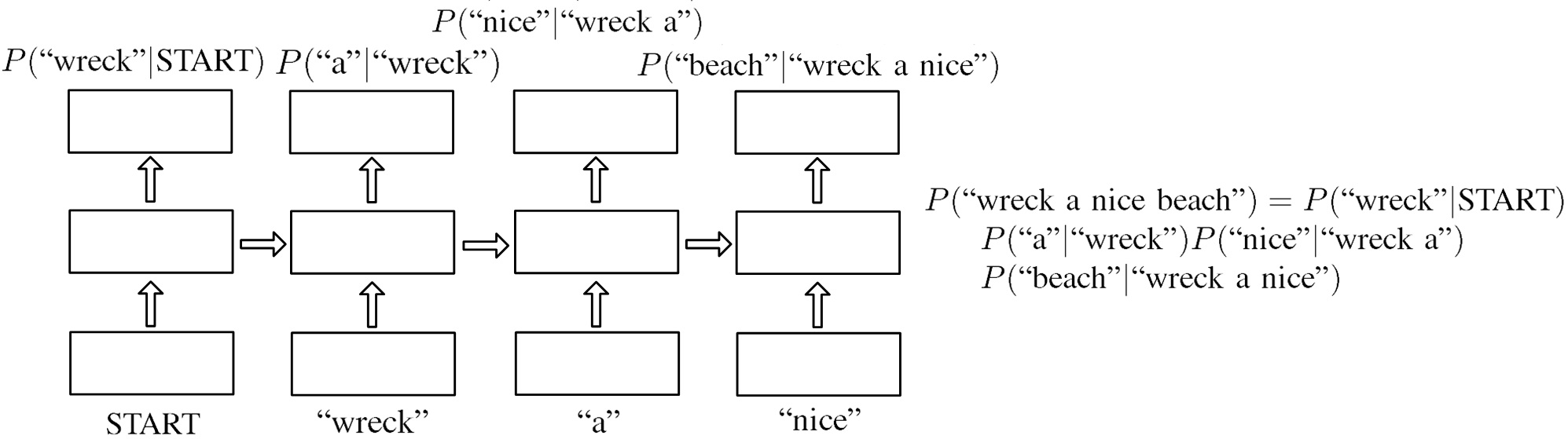
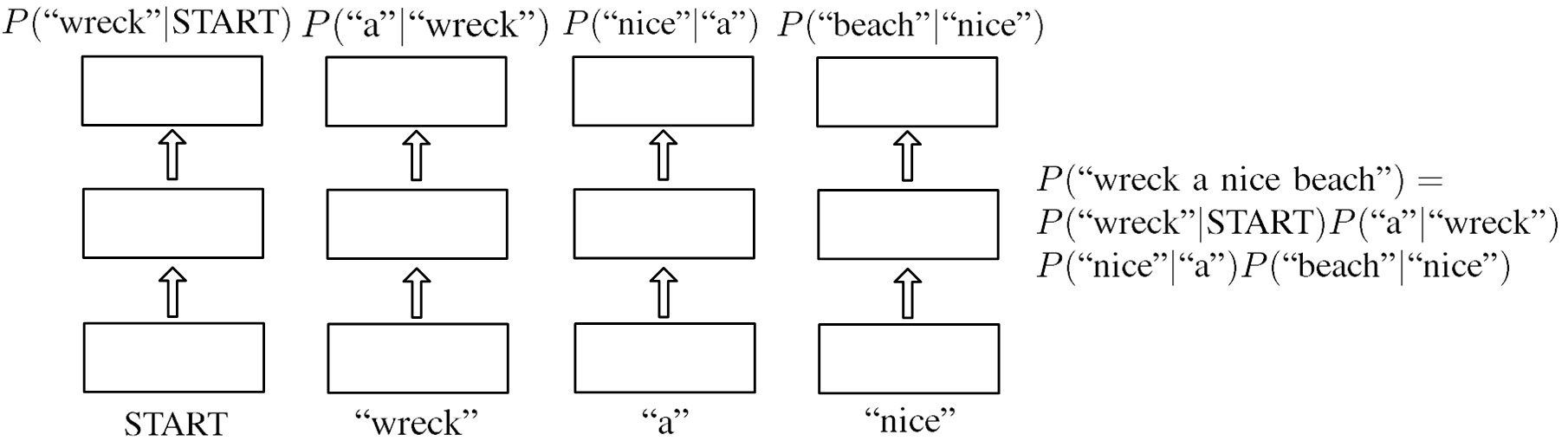 圖五、Bi-gram NNLM之範例示意圖。輸入字串為"wreck a nice beach"。
圖五、Bi-gram NNLM之範例示意圖。輸入字串為"wreck a nice beach"。
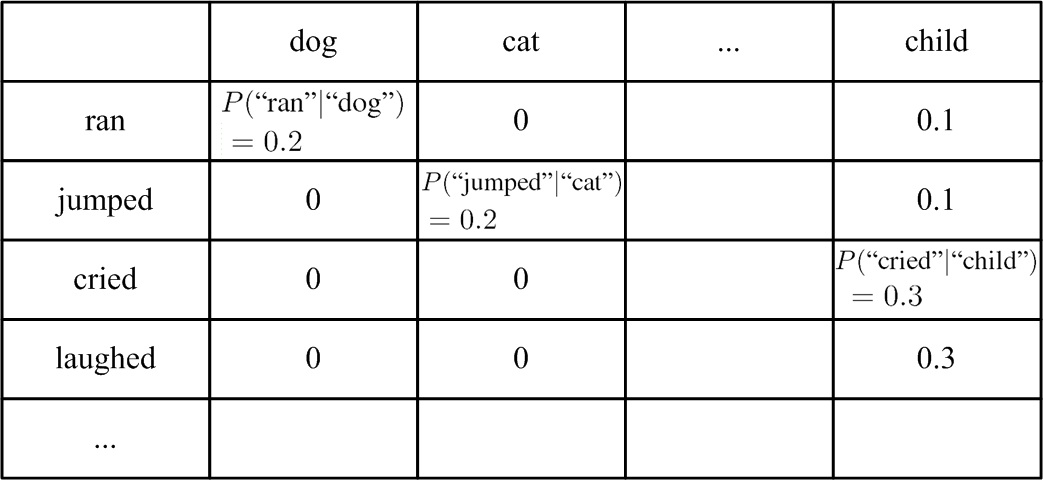 表一、Bigram 語言模型:統計語料庫中,所有可能的雙字組合之條件機率。
表一、Bigram 語言模型:統計語料庫中,所有可能的雙字組合之條件機率。
破解一些知識後,要為重要結論畫示意圖
 Fig.2. Data flow of CBOW model with one-word context. is the one-hot encoded vector of word and is input to the NN for CBOW model with one-word context. is the output of the NN. The input word vector representation and output word vector representation are two kinds of word vector representations.
Fig.2. Data flow of CBOW model with one-word context. is the one-hot encoded vector of word and is input to the NN for CBOW model with one-word context. is the output of the NN. The input word vector representation and output word vector representation are two kinds of word vector representations.
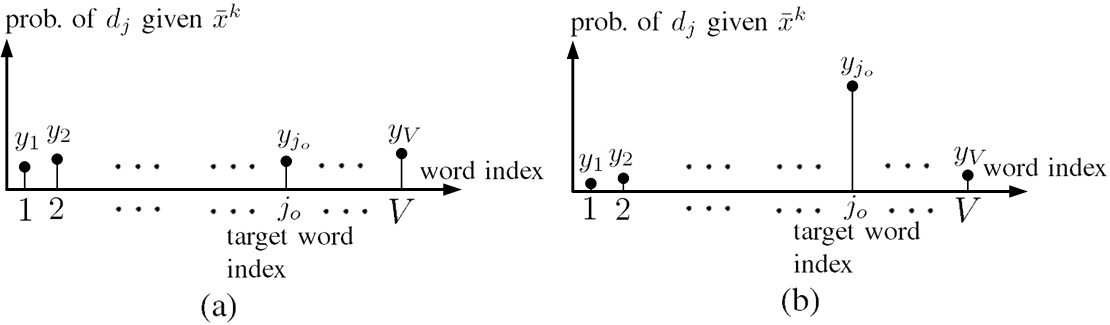 Fig.5. Schematic of NN output given a specific with the target word . (a) non-trained NN, (b) well-trained NN.
Fig.5. Schematic of NN output given a specific with the target word . (a) non-trained NN, (b) well-trained NN.
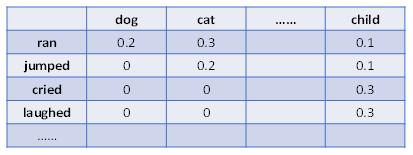
 圖七、N-gram語言模型的缺點。語料庫中存在"dog ran"與"cat jumped",但不存在"dog jumped"與"cat ran"。
圖七、N-gram語言模型的缺點。語料庫中存在"dog ran"與"cat jumped",但不存在"dog jumped"與"cat ran"。
圖七顯示N-gram語言模型的缺點。語料庫中存在"dog ran"與"cat jumped",但不存在"dog jumped"與"cat ran"。N-gram語言模型的機率評估仰賴語料庫,N越大時,語料庫的資料量越是顯得不夠。語料庫無法含蓋人類古往今來說過的話,因此許多存在的詞語之模型預測機率為零,亦即
然而這些字串確實在統計用的語料庫以外是有被使用過的。一種解決的方式稱為語言模型平滑(Language Model Smoothing)技術,即更改上述條件機率,使之不為零而是一個極小的機率,例如:
然而胡亂給予機率值的方式,該語言模型很難有好的表現。若將語料庫中的字,用字嵌入(word embedding),轉為向量,學出字之間的相似度,則可賦予"dog jumped"與"cat ran"合理的機率。
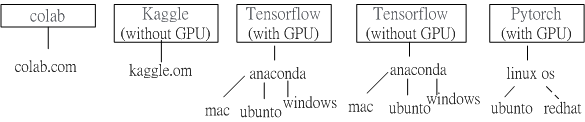 Fig.1 Schematic of machine learning framework dependency.
Fig.1 Schematic of machine learning framework dependency.
影片中的圖,不比我們親自畫的好
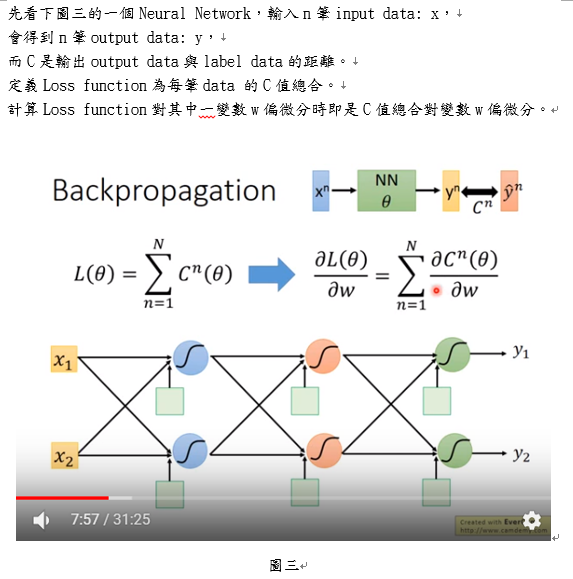
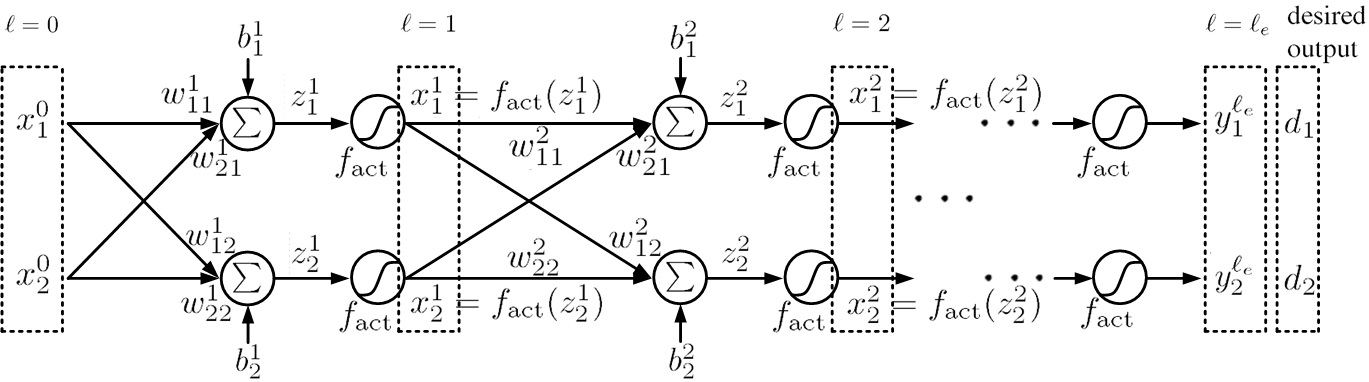 圖七. 深層神經網絡架構之訓練(deep neural network, DNN)。網絡層數為, 第層之神經元數為,其神經元表示為,激活函數為,渴望輸出(desired output)為。
圖七. 深層神經網絡架構之訓練(deep neural network, DNN)。網絡層數為, 第層之神經元數為,其神經元表示為,激活函數為,渴望輸出(desired output)為。
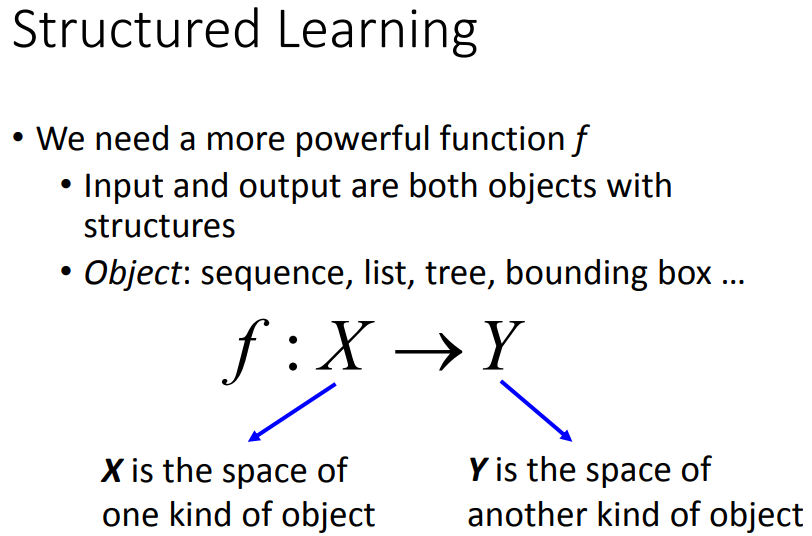
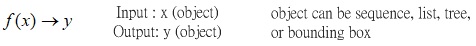
Fig.1 Schematic of structured learning: finding a function where its input and output are objects.
橫圖(banner)比直圖好
thiner one:

a banner one:
