Back propagation
Back propagation是一種有效率算出∂W¯¯∂L 來讓訓練Neural Network變得更有效率。
一個Neural Network裡可能有上百萬的參數(weights W¯¯, biases b¯),在使用Gradient Descent作訓練時就會產生上百萬維的矩陣 ∂W¯¯∂L 和 ∂b¯¯∂L,其中L 是loss function,如下圖一所示:

圖一 Overview of Gradient Descent.

圖二.機器學習的Forward propagation and backward propagation 的示意圖。
圖二呈現機器學習的Forward propagation and backward propagation 示意圖,forward propagation指的是順向運算,意義上是機器
做出推論。backward propagation指的是逆向運算,意義上是學習,本質是調整機器的參數(w¯¯,b¯)。其實,當Forward propagation 清楚定義後,Back propagation 也已經被決定。 Tensorflow會幫忙計算 Back propogation 中複雜的∂w¯∂L
Back propagation立基於微積分的Chain rule,如下圖三所示:
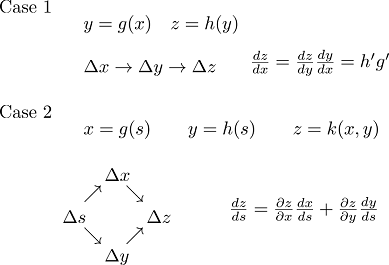
圖三 Schematic of Chain Rule
考慮 y 是 x的函數,而 z 是y 的函數,當x有Δx 變化時,z將有Δz的變化。將z對x微分的定義是:
∂x∂z=Δx→0limΔxΔz=∂y∂z∂x∂y=h′g′
先看下圖四的一個Neural Network,輸入K筆input data: x,
會得到K筆output data: y,而Lk是每一筆輸出output data與label data的距離。
Lk(w¯¯,b¯)=distance(y¯,y^)
定義Loss function為每筆data 的L值總合。
L=∑k=1KLk
計算Loss function對其中一變數w偏微分時即是L值總合對變數w偏微分。
∂w∂L=∑k=1k∂w∂Lk

圖四 Neural Network, loss function, and weight gradient of loss function
以圖四中Loss 對w作偏微分為範例,其等於z對w作偏微分乘上Loss對z偏微分。其中z對w作偏微分稱作forward pass,Loss對z偏微分稱作backward pass。z 為activation function 的input。

圖五 Forward pass and backward pass of weight gradient ∂w¯¯∂L computation
Forward Pass
先看forward pass: z對w作偏微分 如下圖五 z對w作偏微分即為input x

圖六 Elaboration on forward pass of ∂w∂L computation
Backward pass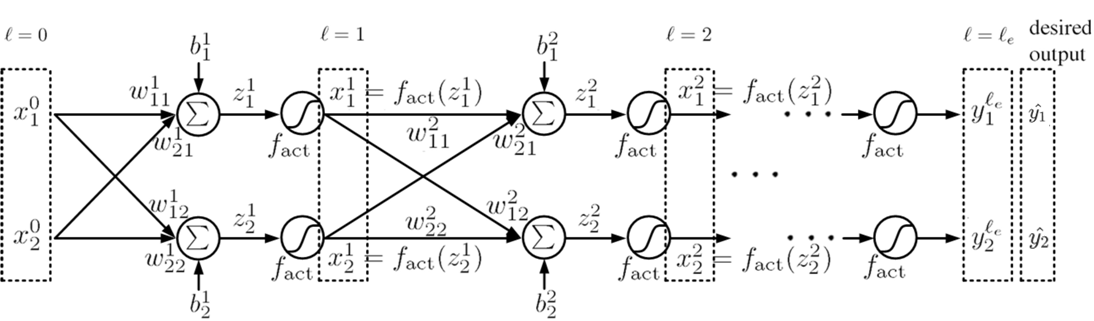
圖七. 深層神經網絡架構之訓練(deep neural network, DNN)。網絡層數為ℓe, 第ℓ層之神經元數為Dℓ=2,其神經元表示為x¯ℓ,激活函數為fact,渴望輸出(desired output)為y¯=[y1,y2]t。
圖七顯示深層神經網絡架構之訓練。網絡層數為ℓe, 第ℓ層神經元數為Dℓ=2,其神經元表示為x¯ℓ,激活函數為fact,渴望輸出(desired output)為y¯=[y1,y2]t,t為轉置操作。
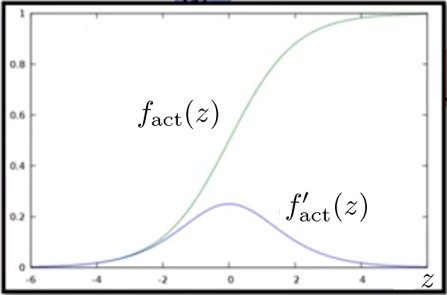
圖八. 激活函數fact與其導函數fact′。此處激活函數選為sigmoid function。
圖八顯示激活函數fact與其導函數fact′。此處激活函數選為sigmoid function。
考慮第ℓ層,此層輸入x¯ℓ−1(為前一層神經元)與此層神經元x¯ℓ間之權重矩陣以及偏差表示為
W¯¯ℓ=[w11ℓw21ℓw12ℓw22ℓ], b¯ℓ=[b1ℓb2ℓ](1)
激活函數輸入值z¯ℓ為第ℓ−1層神經元乘以權重矩陣之轉置加上偏差而得,即
z¯ℓ=W¯¯ℓtx¯ℓ−1+b¯ℓ=[z1ℓz2ℓ]=[w11ℓw12ℓw21ℓw22ℓ][x1ℓ−1x2ℓ−1]+[b1ℓb2ℓ](2)
Backward pass所要求的目標是損耗函數L對激活函數輸入值znℓ(n=1,2)的偏導數,此項目稱為error sensitivity,即
∂znℓ∂L=∂xnℓ∂L∂znℓ∂xnℓ=∂xnℓ∂Lfact′(znℓ)(3)
其中,由圖七可看出xnℓ=fact(znℓ)。而L對神經元xnℓ的偏導數可再由ℓ+1層的error sensitivity表達,即
∂xnℓ∂L=m=1∑Dℓ+1=2∂zmℓ+1∂L∂xnℓ∂zmℓ+1=m=1∑Dℓ+1=2∂zmℓ+1∂Lwnmℓ+1(4)
以第一層ℓ=1為例,網絡輸入x¯0(可視為第零層神經元)與第一層神經元x¯1間之權重矩陣以及偏差表示為
W¯¯1=[w111w211w121w221], b¯1=[b11b21](5)
激活函數輸入z¯1為第零層神經元乘以權重矩陣之轉置加上偏差而得,即
z¯1=W¯¯1tx¯0+b¯1=[z11z21]=[w111w121w211w221][x10x20]+[b11b21](6)
損耗函數L對激活函數輸入值z11的偏導數為
∂z11∂L=∂x11∂L∂z11∂x11=∂x11∂Lfact′(z11)(7)
其中
∂x11∂L=∂x11∂z12∂z12∂L+∂x11∂z22∂z22∂L
∂x11∂L=w112∂z12∂L+w122∂z22∂L(8)

圖九. 第一層神經元x11與第二層神經元之連結。
圖九顯示第一層神經元x11與第二層神經元之連結。當L要對x11做偏微分時,依chain rule會先微至zn2(n=1,2),得出error sensitivity,再參考圖九,得出(8)。

圖十.反向網絡。輸入為error sensitivity。網絡結構與圖九網絡相同,權重亦相同。
圖十顯示一反向網絡。輸入為error sensitivity。網絡結構與圖九網絡相同,權重亦相同。式(8)可看成一個反向網絡如圖十,結構與權重均與原網絡相同,唯傳播方向相反。
最後,backpropagation的目標,L對權重的偏導數,即為forward pass與backward pass兩者所得結果之乘積,
∂wnmℓ∂L=∂znℓ∂L∂wnmℓ∂znℓ(9)