structure learning 李宏毅教授
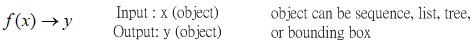
Fig.0 Schematic of structured learning: finding a function where its input and output are objects.
Fig. 1 shows the schematic of structured learning, whose goal is to find a function with its input output being objects.
SVM、Deep Learning NN模型的input和output都是vector。實際上應用情境的input 與output型式比vector更複雜。我們的output可能一個sequence,可能一個list。可能是一個tree,可能是一個bounding box,…等等。
原則上,structured learning要找一個function,這個function的input就是一個object,他的output就是另外一種object。
| x | y | |
|---|---|---|
| speech recognition | sequence (speech signal) | sequence (text) |
| translation | sequence (Mandarin sentence) | sequence (English sentence) |
| syntactic paring | sentence | parsing tree |
| object detection | image | bounding box |
| summarization | long document | short paragraph |
| retrieval | keyword | a list of webpage |
Table. 1 structured learning application example.
Table.1 lists the example for structured learning application.
structure learning有許多的應用。比如說語音辨識,如果你只知道一般的network而不知道structured learning的話,你是無法想像語音辨識怎麼做的。
考慮語音辨識與Translation兩種語音應用場景,它們的input是一個sequence,Output是另外一個sequence。
再考慮中翻英的應用場景,中文是一個sequence,英文是另外一個sequence。
再考慮syntactic parsing作文法剖析的應用場景:Input是一個sentence,output是一個文法剖析的另一個tree structure。
再考慮object detection的應用場景,input是一張image,output 是一個object的位置,再把object的位置用一個bounding box把他框起來。bounding box是output,是一個object。
再考慮summary應用模型,input是一個document,output是summarized的結果。你的input output都是sequence。
再考慮retrieval的應用場景,input是搜尋的關鍵字,output是搜尋的結果。
搜尋的結果是一個list。list是一個具有structure的object。

Fig.1 Unified framework of structured learning, and some examples applications for x and y.
Fig.1 shows the unified framework of structured learning, and some examples applications for x and y are provided.
實際上structured learning有一個unified的framework:
在training的時候,找一個function,F,其作用為衡量X與Y有多匹配。越匹配的話,F的output的值越大。
在testing的時候。給定一個X,再窮舉所有的可能的Y,其中,所求的y是使F最大值的y,output出來的y,表示為。

圖2 以bounding box的例子說明structured learning 的unified framework.
圖2考慮一個實際的例子。給定一個image,任務是找出image裡面的object的bounding box。
Input 是一張image;Output是一個bounding box。
舉例來說,現在假設我們的task呢事要做一個(Haruhi)量工春日的detection。
Input是一張image; Output的bounding box 就是Haruhi的所在位置。
此應用非常廣泛,偵測人臉阿或是無人駕駛偵測有沒有車子,都是在做bounding box的extraction。
hybrid CNN 技術被提出來找出bounding box。而這技術與structure learning很有關係。
李宏毅老師認為GAN與structure learning非常有關係。
Deep learning與structure learning並不是彼此independent的,而是即將要被merge在一起。
考慮object detection的應用,input (X)是image,output (Y)是bounding box。
F(X,Y)就是衡量這張image配上紅色的bounding box,它們有多匹配。
如果以object detection的例子來說,就是它們有多正確。

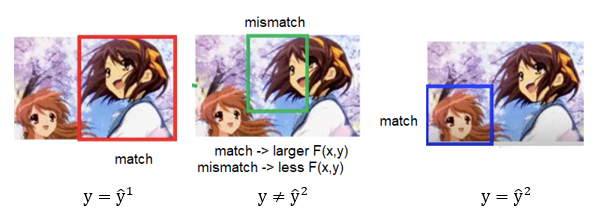
圖3. Schematic of match and mismatch for object detection, where input are image (X) and bounding box (Y).
圖3示意物件偵測的匹配程度。最左邊的紅框是匹配的,中間的綠框是不匹配的,右邊的藍框是匹配的。
如果是匹配的,F(X,Y)的值就應該高;如果是不匹配的,F(X,Y)的值就應該低
 圖4 窮舉可能的Y,所求的y會使F(x,y)最大。
圖4 窮舉可能的Y,所求的y會使F(x,y)最大。
testing的時候,提供model 的input x是一張從來沒有看過的圖。

窮舉所有可能的bounding box,這個bounding box可以畫在紅黃綠藍框上。各別有不同的分數,看說那個得到的分數最高,紅色的得到十分,綠色的得兩分,藍色的三分,綠色的一分。紅色的最高,紅色就是model的output。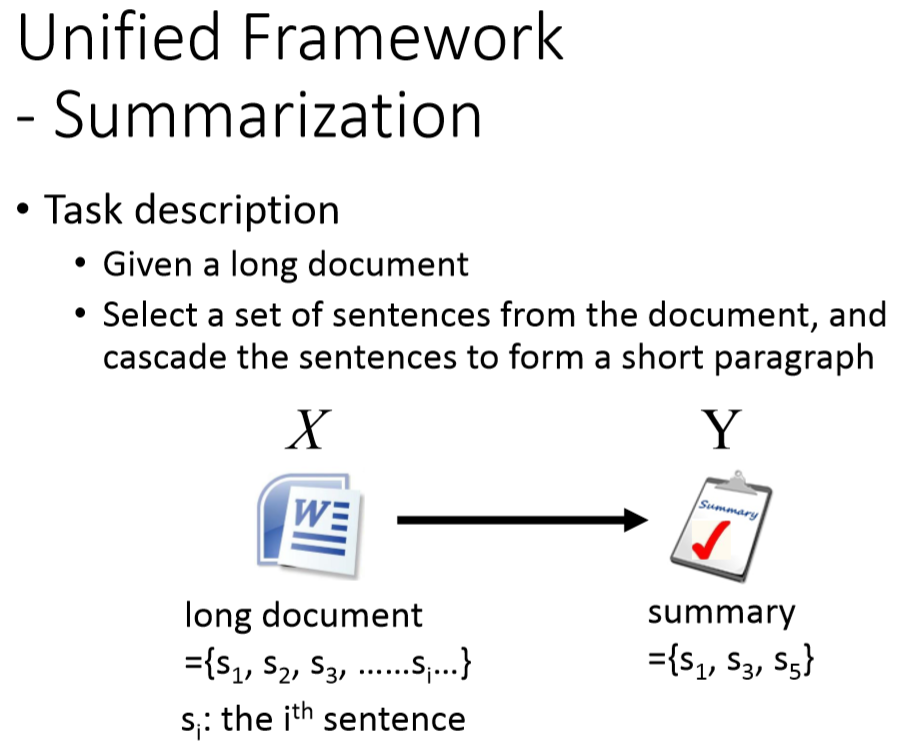 圖5 以summarization 應用說明unified structured learning framework.
圖5 以summarization 應用說明unified structured learning framework.
考慮summarizton的task應用,model 的input一個document很長的文章,裡頭有很多句子; model 的output是一個summary。
summary是從input document取幾個句子(subset)出來。
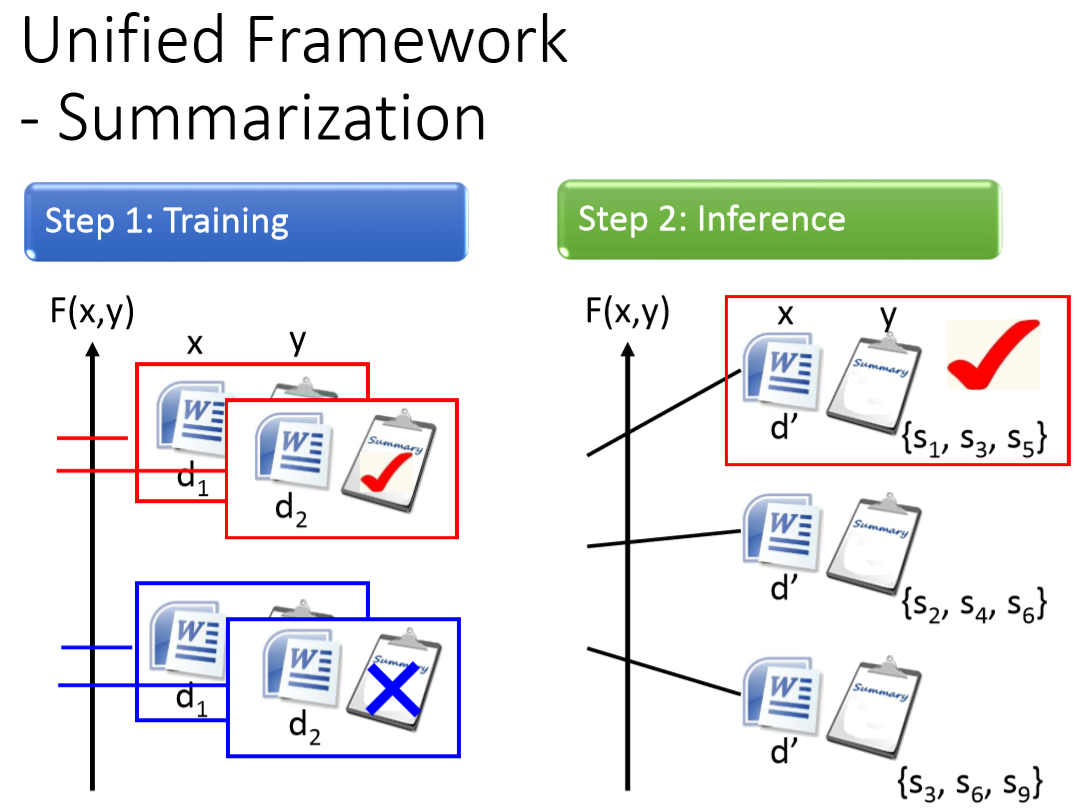
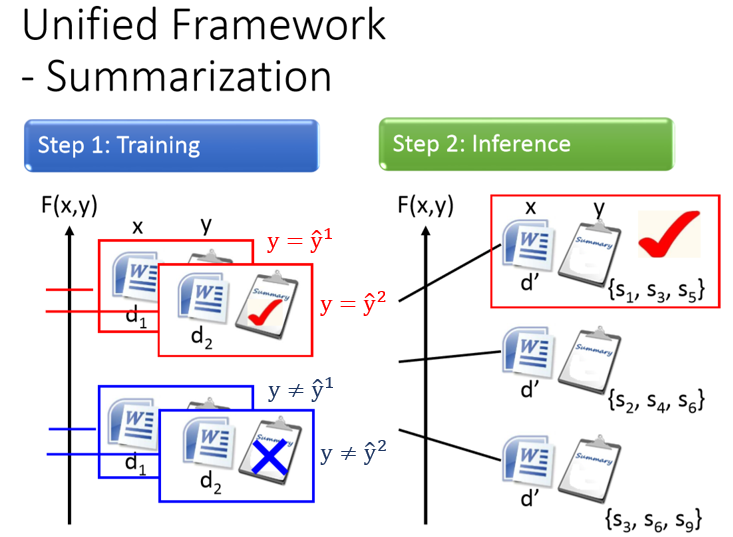
圖6 summarization應用下的training 與inference。
summarization應用下training的時候,我們要找F(x,y),F(x,y)的值在input document與對應的summary配成一對時,F的值很大。
Document跟非對應的summary配成一對時,F的值就很小。對每一筆training data都這麼做。
summarization應用下Testing的時候,給定一個model沒有看過的document ,窮舉所有可能的sumdmary ,那一個summary 可以讓的 最大,它就是model的output。
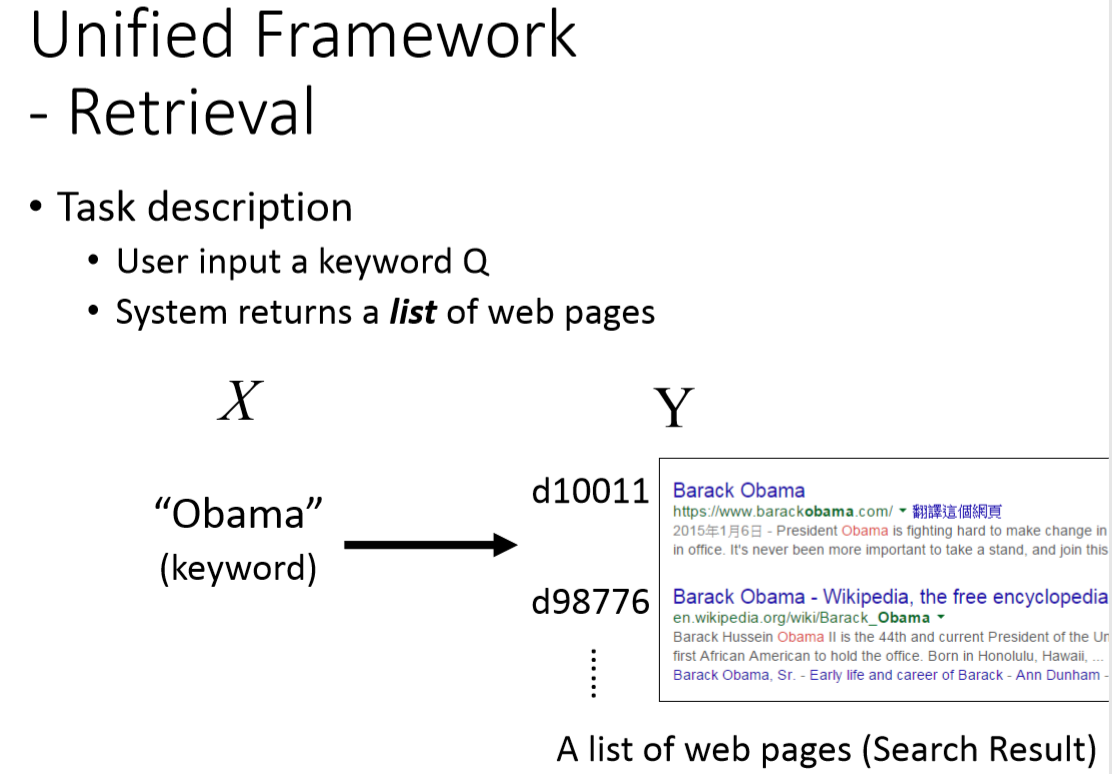
圖7 以retrieval 應用說明unified structured learning framework.
考慮retrival作的task,Input是一個查詢詞 (query, ); output是一個搜尋的Webpage list 結果 (query response, )。
training的時候,我們要找F(x,y),F(x,y)的值在input 查詢詞與對應的response 配成一對時,F的值很大。
假定Input 為Obama的時候,output為圖七右方的list response 是最好的,F(x,y) 分數最高;
Output不是這個list response是不對的,F(x,y) 的分數比較低。
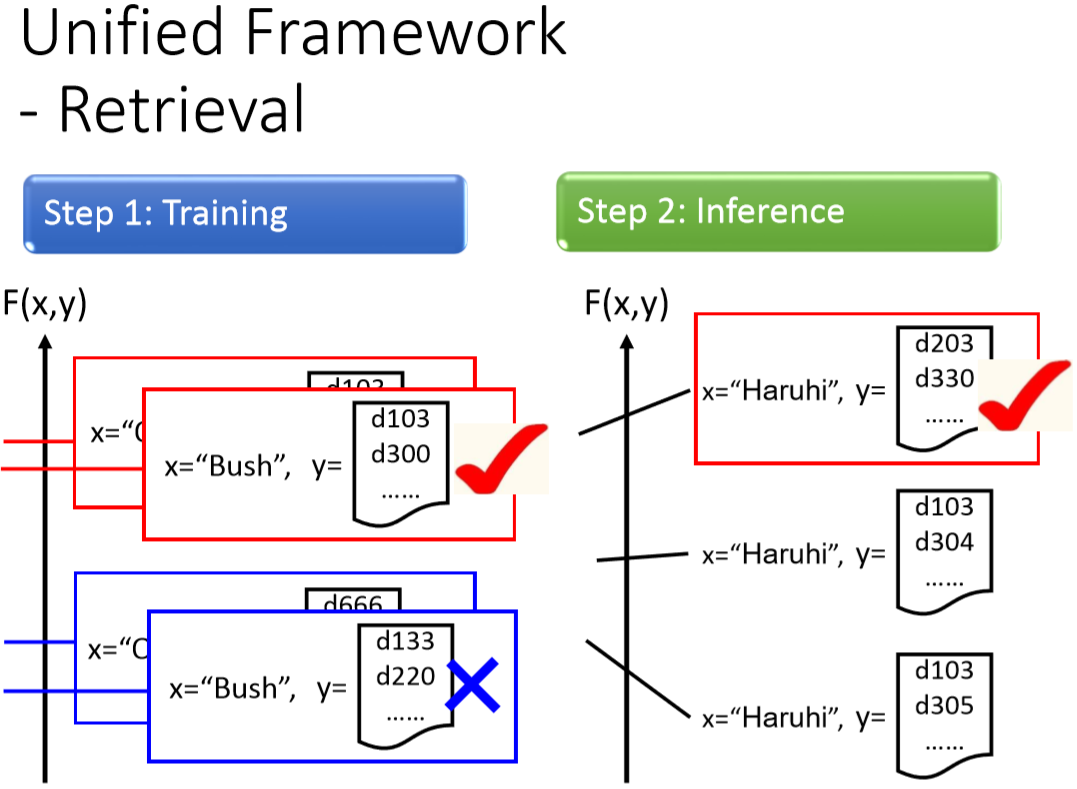
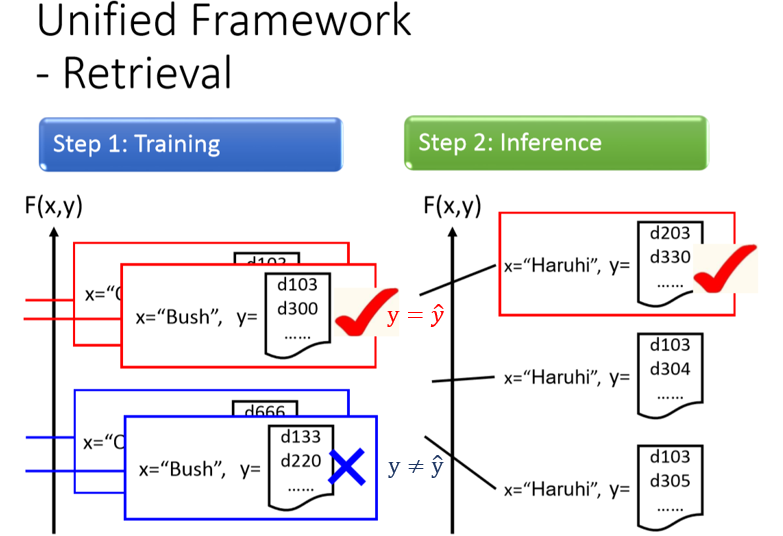
圖8 retrieval應用下的training 與inference。
training的時候, (Bush) 配上 (d103, d300) list response 是對的,所以 分數比較高
list response (d133,d220) 是不對的,所以 分數比較低。
(Haruhi) 配上 (d103, d300) list response 是對的,所以 分數比較高
list response (d103,d304) 是不對的,所以 分數比較低。
作搜尋(inference) 的時候,輸入一個量工春日(Haruhi),就全窮舉所有可能的list response ,那一個list response 的分數最高。
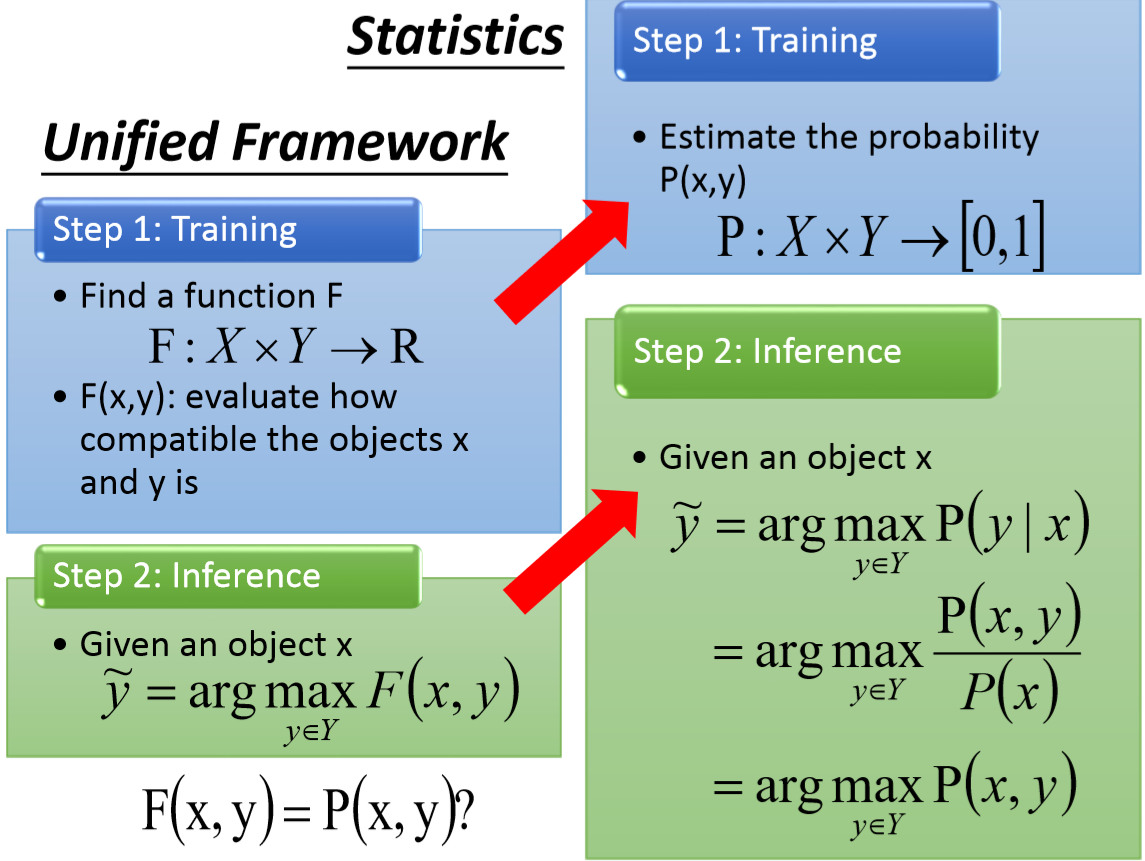
圖9 從joint probability的角度看structured learning的unified framework。
可以從joint probability的角度重新查看structured learning 的unified framework:

圖10 從joint probability的角度看structured learning 的training。
在training的時候,要找出一個函數,意義上是X與Y一起出現的機率 (joint probability),其中。
圖11 從joint probability的角度看structured learning 的inference。
在作testing的時候,就是給model一個object X,並計算P(y|x)的機率。
哪一個y機率使最高,便是答案。
p(y|x)的機率可以寫成P(x,y)/P(x),由於P(x)與無關,使最高就是找最高。
使 最高的那個y就是model的output。

圖12 從joint probability的角度看structured learning 的training 與inference。
按joint probability的觀點,training時要找X跟Y的joint Probability (X與Y一起出現的機率) , 。在testing的時候,根據這個機率,要找最有可能的Y。
joint probability的觀點與一開始說的 觀點都是可以的。
文獻有一個技術是grafical model。其實,graphical model就是structure learning的其中一種。
只是在graphical model的時候,換成是機率。
還有believed network Michel random field。他們講的其實是一樣的事情。
李宏毅老我個人覺得,我比較喜歡用F(X,Y)勝過機率。
機率的壞處是範圍較狹隘,比如做搜尋應用,input (X)是ㄧ個查詢詞,Y是ㄧ個搜尋的結果。
那個要衡量這個查詢詞跟這個搜尋結果共同出現的機率的說法比較不夠好。
另外機率會有constraint就是機率的所有總合為1。
使用機率的觀點的好處是你比較容易了解想像。
其實還有另外一個東西叫做energy model,這是Yan Lecunn提出來的。其實,energy model講的也是structure learning,有很多人在差不多的時間點都提出的很多類似的framework,那麼合起來就是我們這邊這個unified的structure learning的framework
他們講的其實是一樣的東西,graphical model,structured learning,energy model,他們的framework都是一樣。就好像同樣的東西,在獵人裡面叫作獵人在海賊王裡面叫做霸氣,在火影裡面叫做查克拉,他們其實都像是一樣的東西。

圖13 structure learning unified framework的三個重要問題。
關於structured learning 的unified framework,需要解決三個問題。
第一個是 應該長怎麼樣子? 第二個是 inference時,如何窮舉所有的Y ( problem)?
第三個是如何train model,找到?
圖14 structure learning unified framework的第一個重要問題: 如何評量與的匹配度
第一個問題是長什麼樣子。

圖15 以object detection應用思考 如何評量與的匹配度
以object detection應用為例,model的input是ㄧ個image,加上一個bounding box,這個F(X,Y)應該是長什麼樣子?
y = y hat

圖16 以summarization, retrieval應用思考 如何評量與的匹配度
以summarization應用為例,model的input是ㄧ個long document,加上short paragraph,這個F(X,Y)應該是長什麼樣子?
以retrieval應用為例,model的input是ㄧ個keyword,加上list,這個F(X,Y)應該是長什麼樣子?
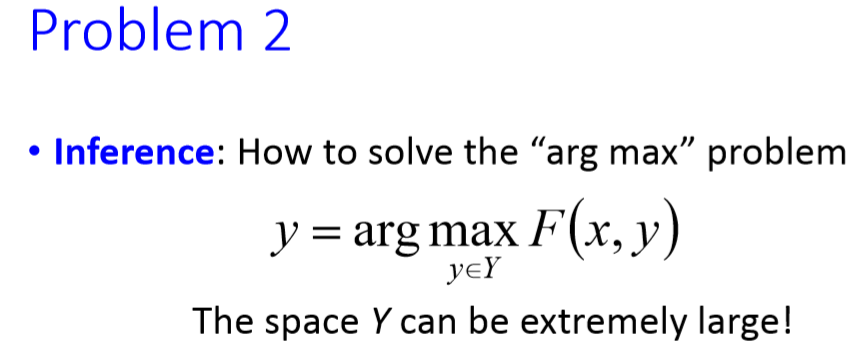
圖17 structure learning unified framework的第二個重要問題:如何解 的問題。
第二個問題是如何解 的問題,因為所有的可是很大的集合。

圖18 以object detection, summarization and retrieval應用思考如何解的問題。
以object detection應用來說,所有的Y,是all possible bounding box.
以summarization 應用來說, 所有的Y,是all combination of sentence set in a document.
以retrieval應用,所有的Y,是all possible webpage ranking。
 圖19 structure learning unified framework的第三個重要問題:如何訓練模型得出 ?
圖19 structure learning unified framework的第三個重要問題:如何訓練模型得出 ?
第三個問題是如何train model,其中training的priciple是正確的X與Y的pair可以大過其他的pair。
若能解出這三個問題,就可以解出structure learning的problem,就像是擁有三張神之卡便可以成為法老王。
李宏毅老師覺得GAN就是解出這三個問題的solution。GAN就是解這三個問題的曙光。

圖20 數位語音處理領域與structured learning對應的三個重要問題。
數位影音處理課堂中,李琳山老師曾經說過HMM有三個問題,這三個問題與structure learning的三個問題相對應。

圖21 structured learning 與DNN的關連。
structured learning 可以與DNN Link在一起。feedforward network的應用其實就是structure learning的一個special case。
比如考慮一個手寫數值辨識的應用,model Input是一個image,output是分成十類(0,1,2,...,9)。
在training的時候 為
是 經過DNN的output。 是ㄧ個十維的vector,他分別代表十個不同的數字,其中只有一個element是1其他是0。
指的是 與 的距離。可以以cross entropy定義其距離的算式。
換句話說,F(X,Y) 就是 negtive的cross entropy。
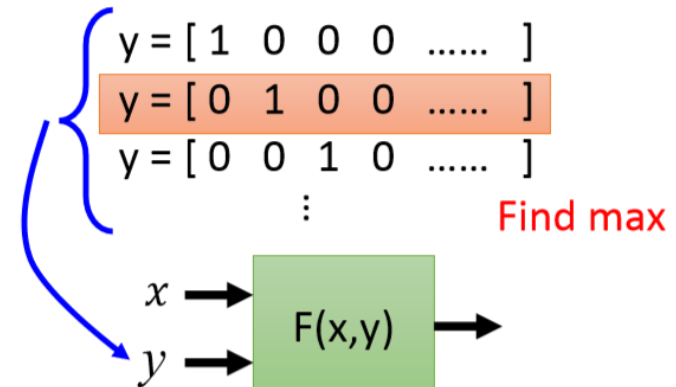
圖22 testing 時,DNN 與structured learning unified framework的關連。
在testing (inference)的時候,窮舉十個所有可能辨識的結果,
每一個都帶進去這個function裡面,看那一個辨識結果可以讓F(X,Y)最大。那個y就是的辨識結果。
因此,DNN的運作可以看成是structured learning的一個special case。
你可以定出事實上我們做的是f(x) output Y其實那個問題我們也可以想成我們找一個大F,input X Y output一個number去evaluate X Y有多compatible。
有多相容,這個arg max這個問題,因為在trasfication裡面我們的y太少了,才看了幾個case就有幾個Y有可能窮舉的
那找max其實就是那個窮舉的那個行,可你輕易做到。
Input is a vector
Output is a vector
Deep Learning,
Output: List, tree, bonding box
Structure learning:
Speech recognition input sequence output sequence
Translation:
Unified Framework- Object Detection
figure, ...
Enumerate all possible bounding box y
Unified framework
Training is to estimate the joint probability of X and Y
Find the y that makes the joint probability of X and Y be maximum