Language Model
語言模型(Language Model)
 圖一、語言模型架構圖 (本篇文章將分別說明 N-gram 及 Neural Network 2 種語言模型)
圖一、語言模型架構圖 (本篇文章將分別說明 N-gram 及 Neural Network 2 種語言模型)
語言模型描述一個字串 (word sequence, WS) 的機率。
考慮一個英文字庫,其中到分別為不同的字詞,例如 "dog"、"love"、"why"、"about" 等等。
一個字串由字庫的字組成,如下例子所述,其中為end-of-line之縮寫,也表示字串的總字數。字串中的字以表示,其上標為字串中字的順序編號,下標表示該字為字庫中的第幾個字。一個字串的機率表示為。
圖二、兩個發音相近意思相異之英文字串示意圖。
圖二顯示兩個發音相近,但是由不同字與不同字數構成的英文字串。
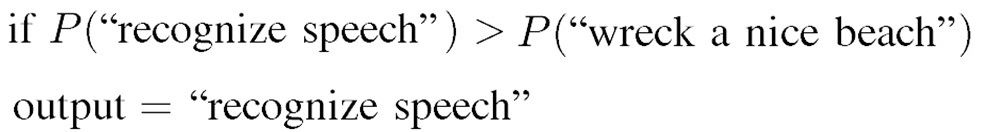 圖三、語言模型之用途 (function)。
圖三、語言模型之用途 (function)。
圖三顯示語言模型之用途 (function)。給定聲音訊號的條件下,語言模型前一級的聲學模型判斷出該聲音訊號可能為 "recognize speech" 和 "wreck a nice beach" 兩者其中一個。一個訓練好的語言模型能夠判斷 "recognize speech" 的機率較 "wreck a nice beach" 高或低,好的判斷通常和人的經驗判斷是相符合的,例如 "recognize speech" 的機率高於 "wreck a nice beach"。語言模型除了可用於上述語音辨識範例,也可用於翻譯和句子產生。當一個聊天機器人回應人類時,語言模型幫助機器人選擇較正確且符合文法的句子。
N-gram 統計語言模型
N-gram 語言模型表示語言模型預測下一個字時,將 N 個連續的字做為考量 (N為一正整數)。以 Bi-gram 語言模型為例,Bi 表示 2,即該語言模型在預測下一個字時,將考量連續的 2 個字;因此,Bi-gram 語言模型中,一字串的機率可表示為:
在此式中,字的下標省略顯示;上式的條件機率的計算來自語料庫。
條件機率 定義為 B 出現的情況下,A 出現的機率;
舉例來說,下式即是計算當出現 ”nice” 時,”beach”緊接在後的機率,將語料庫中出現 ”nice beach” 的機率 (也就是 nice ∩ beach 的機率) 除以出現 ”nice” 的機率;而實際計算上則是計算語料庫中出現 ”nice beach” 的次數除以出現 ”nice” 的次數:
這樣的語言模型稱為統計語言模型,因為條件機率來自於語料庫的統計結果。
相同的概念下,也可以從語料庫中產生 Tri-gram 或 4-gram 等語言模型。如下為 Tri-gram 語言模型的一個例子。
N-gram統計語言模型的缺點
考慮一個情境:在一個語料庫中,有 "dog"、"cat" 和 "baby" 等名詞,也有 "ran"、"jumped"、"cried"、"laughed"、"climbed" 等動詞。

圖四、語料庫中部分的字詞關係。
如圖四所示,語料庫中的字之間的箭頭表示該字串的可能性是否存在,例如字詞庫存在 "dog ran" 和 "baby cried" 字串,但不存在 "dog climbed" 和 "baby ran"。則使用該語料庫計算的 Bi-gram 統計語言模型時存在的缺點為:Bi-gram 語言模型的機率評估仰賴語料庫,但語料庫無法含蓋人類古往今來說過的話,即語料庫的資料量通常不夠,因而許多字串出現的次數為零。
以表一呈現 Bi-gram 統計語言模型: 表一、Bi-gram 統計語言模型以統計的方式條件機率呈現各個字相連機率的計算方式。
表一、Bi-gram 統計語言模型以統計的方式條件機率呈現各個字相連機率的計算方式。
表一顯示所有可能的雙字組合之條件機率。表格中每一個欄位表示第一欄 (column, ) 字緊接在第一列 (row, ) 字後的機率,此方法稱為 Matrix Factorization; 及 表示該 WS= ;而 ,可為字庫 V 中所有字詞。
表一中許多欄位的值將為零,表示現有的語料庫並沒有該字串。對於 N-gram 統計語言模型來說,因為語料庫無該字串而使許多欄位的值為零是很常見的。
Bi-gram 模型中,僅用 1 欄 () 及 1 列 () 兩個維度即能表達所有字詞組合;當 N-gram 語言模型的 N 越大時,該表格就需有 N 個維度來表達所有字詞組合;因此語料庫中字串出現的次數為零的字串將會更多,但這些字串確實在統計用的語料庫以外是有被使用過的。
一種解決的方式稱為語言模型平滑(Language Model Smoothing)技術,即更改上述條件機率,使之不為零而是一個極小的機率,例如:
然而胡亂給予機率值的方式,該語言模型很難有好的表現。
神經網絡語言模型(Neural-network-based Language Model)
若將語料庫中的字,用字嵌入 (word embedding),轉為向量,學出字之間的相似度,則可賦予 "dog climbed" 合理的機率。
If the similarity between dog and cat is learned from word embedding, dog jumped and cat run can appear with reasonable probabilities.

圖五、神經網絡語言模型示意圖。
圖五為一個神經網絡語言模型 (Neural-network-based language model, NNLM)。該神經網絡輸入一個字後,能夠輸出字庫中各個字為字串下一個字的機率。不同於 N-gram 統計語言模型從語料庫統計以換算機率,一個神經網絡預測下一個字的機率,是利用訓練的方式得到。

圖 六、NNLM 之範例示意圖。輸入字串為 "wreck a nice beach"。
圖六顯示 Bi-gram NNLM 之範例示意圖。輸入字串依序為 "wreck a nice beach" 的字。在第一個字 "wreck" 之前,會先輸入一個START,在此也可視為一個字,表示一個字串將要開始。此 Bi-gram NNLM 根據當前輸入的字預測下一個字的機率,而整個字串的機率即如下條件機率相乘。

圖七、循環神經網絡語言模型之範例示意圖。輸入字串為 "wreck a nice beach"。
圖七顯示循環神經網絡 (Recurrent-neural-network-based, RNN-based) 語言模型 (RNNLM)。輸入字串與圖六的 NNLM 相同,依序為 "wreck a nice beach" 的字。循環神經網絡語言模型根據所有已經出現過的字預測下一個字的機率。圖七所預測之字串機率會是如下。
神經網絡語言模型的優點 表二、Bi-gram NNLM以字向量計算雙字組合之條件機率。
表二、Bi-gram NNLM以字向量計算雙字組合之條件機率。
Bi-gram NNLM:以字向量計算雙字組合之條件機率。將表一各字以向量 (Vector) 的形式表示:第一列以 表示,其中表示 history (context word);第一欄以,其中 表示 vocabulary。history 與 vocabulary 之間的機率值則以 表示。和藉由訓練神經網絡獲得,盡可能使損耗函數最小化。損耗函數在此處定義為
在表二中,所有的機率值都由向量的內積 (inner product) 取代。其優點為,若兩個向量相似度高,例如 dog 和 cat 作為動物名詞都有類似的特性,兩者緊接 ran 和 jumped 的機率都高,儘管在統計數據上,字串 ”dog climbed” 出現的次數為零,但是對一個訊練好的神經網絡,由於代表 “cat jumped” 的值高,代表 “dog jumped” 的 也因而遠高於零。因為 dog 和 cat 兩者後緊接 cried 和 laughed 的機率原先就為零,而在訓練的過程中,產生的 baby 向量特性 (人類名詞) 有別於 dog 和 cat 兩者 (動物名詞) 的向量特性,儘管 baby 緊接 cried 的機率高,但不至於使 dog 和 ca t兩者緊接 cried 的機率遠高於零;反之,baby 緊接 climbed 的機率並沒有提高。這方法亦可達到語言模型平滑技術,並且是較有根據的。圖四的字因特性相似而能夠如圖八表示分為兩個集群。

圖八、圖七的相似向量的集群。

圖九、CBOW模型的神經網絡訓練示意圖。
圖九顯示 CBOW 模型的神經網絡訓練示意圖,用以得出及。輸入為一個one-hot encoding向量,此例中向量中dog的值為1,其餘的值為0。輸入(input)與隱層(hidden layer)之間的權重(weights)即是,此例中由於輸入向量只有dog的值為1,則隱層的輸出為,在此先忽略活化函數 (activation function)。獲得之後,於下一個隱層再乘上向量,此例中為和,再經過softmax函數,得到各字串的條件機率,例如此例的和。最後,利用機器學習降低輸出與目標之間的交叉熵,即完成神經網絡的訓練。神經網絡語言模型使用較少的參數,因而比較不容易發生統計上的過適(overfitting)現象。越長字串出現在語料庫的次數會越低,通常導致無法在統計數據上形成有意義的機率分布。神經網絡語言模型可以避免此問題,獲得一個長字串之後緊接的字的機率分布。