整體規劃流程圖

Figure 1 Overall Flowchart of 2018/7/21 2th Kaggle Competition
[改圖]
圖1呈現kaggle2的比賽架構。將choice檔(C00001.wav, C00002.wav,...)做 speech audio bandpass filter,各自產生對應的除去雜訊choice音檔(C00001.wav, C000002.wav檔名),存放在bp_filtered資料夾下。
將1500個choice檔分成三等份(1~500、501~1000、1001~1500 ),各自進入QA work unit。產生出每題的答案,三份答案(answerper_Q_unit1.csv, answerper_Q_unit2.csv, answerper_Q_unit3.csv)將被送到distributed master,由distribute master 統一執行merge predicted answer, 目的是將三份答案合一,稱做M.L.version答案。
Answer Manual Correction指由人工方式產生答案檔(task1.csv, task2.csv, task3.csv,...)。
Merge Manually Corrected Answer將人工方式產生答案檔整合進M.L. version答案,產生出最後的submission檔(submission.csv)
kaggle2比賽的規劃,跟kaggle1使用的方法基本相同。
差別在於使用分散式的運算,每個運算block都是一個單獨的python script,執行完python script之後會產生資料檔(answerper_Q_unitX.csv, ...等等),用分散資料來做分散式運算。另
最後加入人工校正答案的程式,進一步提供最後的正確率。
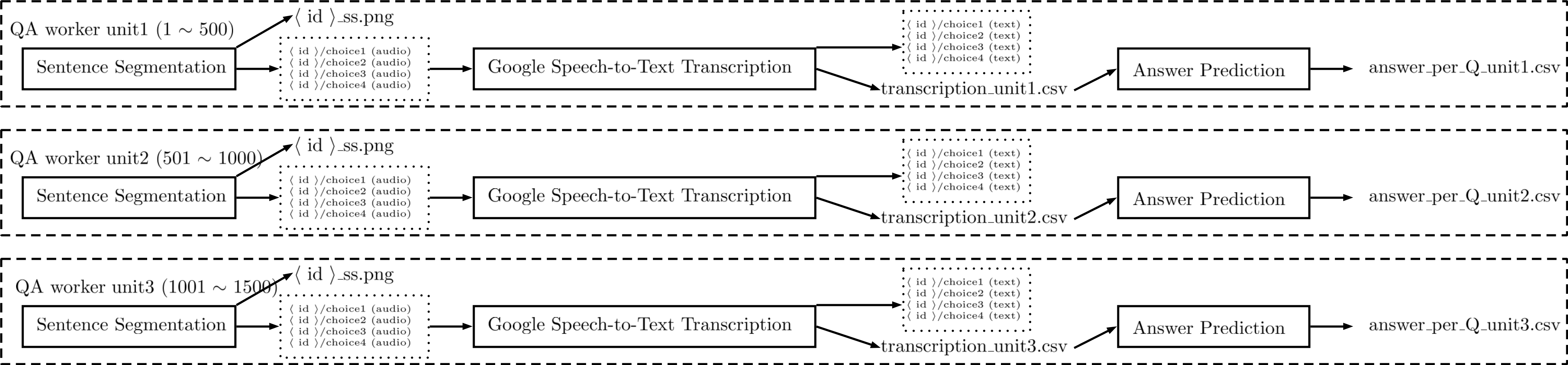
Figure 2 Inside the QA worker unit block [改圖留一個折下來]
Figure 2 是figure 1裡面QA work unit的細節。
QA worker unit是由Sentence Segmentation, Google Speech-to-Text Service, Answer Prediction組成。
sentence segmentation將音檔切成choice1, choice2, choice3, choice4個音檔(wav檔)。
sentence segmentation也將產生圖檔(<id>-ss.png),目的是做sentence segmentation的視覺呈現。
再使用google speech-to-text service,。
google speech-to-text service也會把所有的選項整合進transcription_unitX.csv檔。[transcription_unitX.csv示意圖] caption產生choice1, choice2, choice3, choice4四個文字檔(txt檔)
將transcription_unitX.csv放入answer prediction,分批產生csv檔(answer_per_Q_unit1.csv, answer_per_Q_unit2.csv, answer_per_Q_unit3.csv )。