2018/6/6 created by Jeff Wei
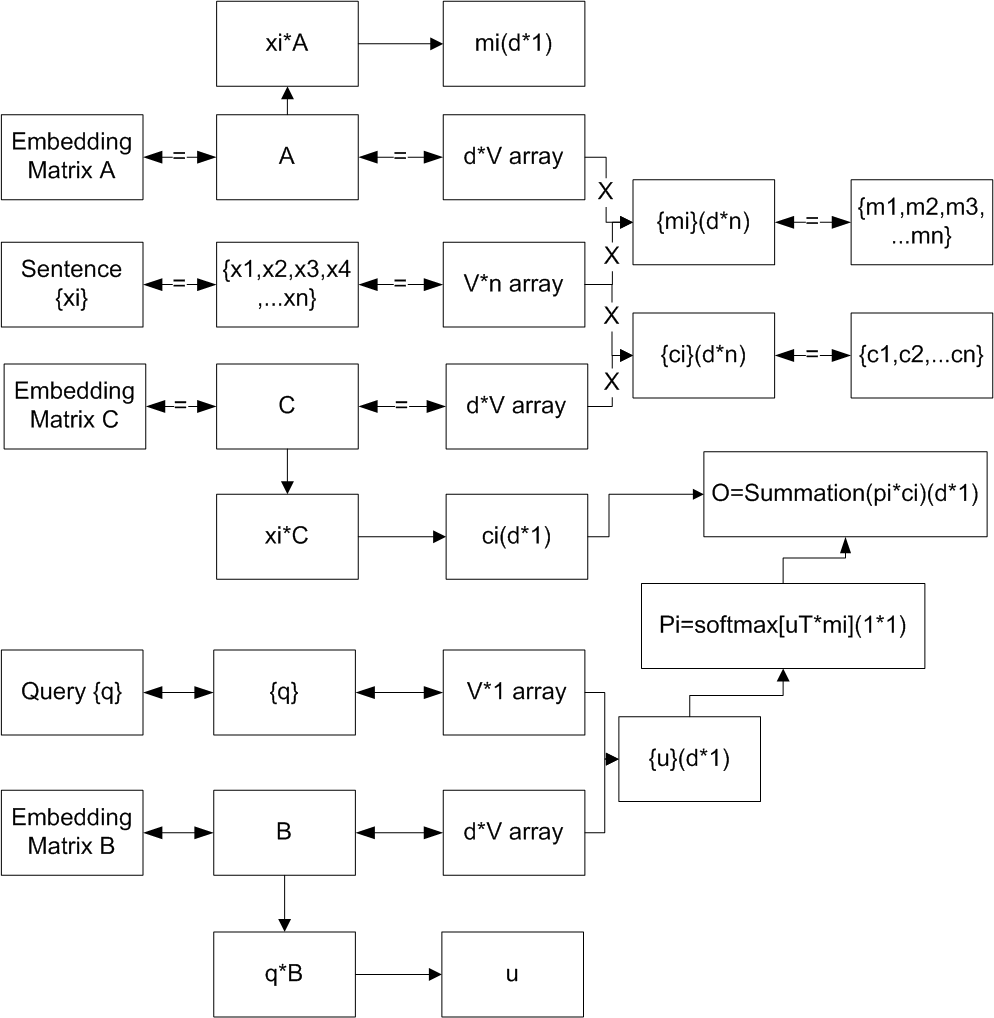
End-To-End Memory Networks
A neural network with a recurrent attention model over a possibly large external memory is introduced.
The architecture is a form of Memory Network but unlike the model in that work [Memory networks] J. Weston, S. Chopra, and A. Bordes.
The architecture is trained end-to-end, and hence requires significantly less supervision during training, making it more generally applicable in realistic settings.
The architecture can also be seen as an extension of RNNsearch [Neural machine translation by jointly learning to align and translate] to the case where multiple computational steps (hops) are performed per output symbol.
The flexibility of the model allows one to apply it to task as diverse as (synthetic) question answering [Towards AI-complete question answering:A set of prerequisite toy tasks] and to language modeling.
For the former,the approach is competitive with Memory Networks, but with less supervision.
For the later, on the Penn TreeBank and Text8 datasets the approach demonstrates slightly better performance than RNNs and LSTMs.
In both cases, the key concept of multiple computational hops yields improved results is shown.
1 Introduction
Two grand challenges in artificial intelligence research have been to build models that can make multiple computational steps in the service of answering a question or completing a task, and models that can describe long term dependencies in sequential data.
Recently there has been a resurgence in models of computation using explicit storage and a notion
of attention[Memory networks,Neural turing machines,Neural machine translation by jointly learning to align
and translate] manipulating such a storage offers an approach to both of these challenges. In [Memory networks,Neural turing machines,Neural machine translation by jointly learning to align and translate],the storage is endowed with a continuous representation;
reads from and writes to the storage, as well as other processing steps, are modeled by the actions of neural networks.
In this work, we present a novel recurrent neural network (RNN) architecture where the recurrence
reads from a possibly large external memory multiple times before outputting a symbol.Our model
can be considered a continuous form of the Memory Network implemented in [Memory networks.]
The model in
that work was not easy to train via backpropagation, and required supervision at each layer of the
network.
The continuity of the model we present here means that it can be trained end-to-end from
input-output pairs, and so is applicable to more tasks, i.e. tasks where such supervision is not available,
such as in language modeling or realistically supervised question answering tasks.
Our model
can also be seen as a version of RNNsearch [Neural machine translation by jointly learning to align
and translate] with multiple computational steps (which we term
“hops”) per output symbol.
It will be shown experimentally that the multiple hops over the long-term
memory are crucial to good performance of the model on these tasks, and that training the memory
representation can be integrated in a scalable manner into the end-to-end neural network model.