Signal-Domain Sentence Segmentation

圖0 Sentence Segmentation 方法分類示意圖
圖0呈現有兩類signal-domain的方法來做setence segmentation。
第一類是Match audio signal,意思是匹配音頻跟關鍵字的相似度,找出關鍵字在音頻裡的時間點,藉此把句子。(只對選項choice audio適用,因為paragragh audio並不存在特定的起始字元,所以不適用。)
Dynamic Time Warping (DTW) is applied to match audio signal.
第二類是Silence Removal,意思是偵測句子跟句子的安靜片段來分割句子。
Silence Removal又可以細分為using fixed sound threshold level跟using adaptive sound threshold level。
Adaptive sound threshold level又可以在細分為fixed level difference to maximum sound level跟 learning sound level using SVM。
Silence removal using fixed sound threshold level 的implementation是用librosa.effect.split() function實現。
Silence removal using fixed level difference to maximum sound level 是用pydub.split_on_silence() function實現。
Silence removal by learning sound level using SVM 是用pyAudioAnalysis.audioSegmentation.silenceRemoval()function實現。
示意圖
第一類:Match audio signal
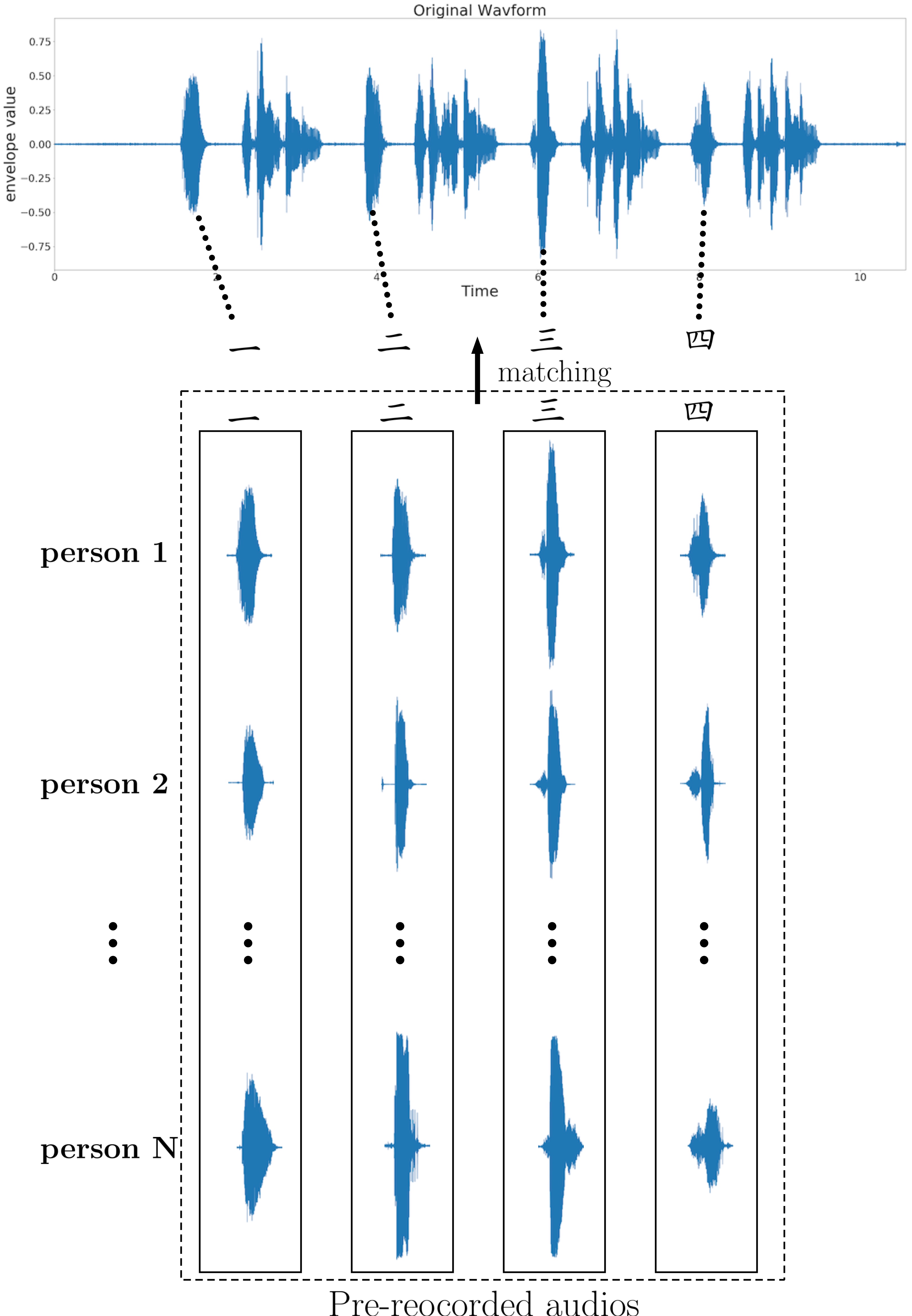
圖一 Match Audio Signal based Method 示意圖
圖一呈現match audio signal method 如何運作。
基於圖一,我們可以把sentence segmentation問題變成找選項編號的問題。
match audio method基於Choice Audio的特殊結構,每個選項前面都有選項的編號,透過匹配找尋這些編號所在的時間點,我們可以清楚分割sentence,也可以知道每個句子代表的選項編號。在一些特殊的情況 講者只有說部份選項或完全沒有說選項,系統還是可以正確辨識運作。
我們的作法是預先取得N個person說"一"、"二"、"三"、"四"的音頻。當一個新的選項音頻輸入時,用DTW計算音頻跟我們預錄"一"、"二"、"三"、"四"的相似度,選擇最相似的person。DTW除了計算相似度之外,也會計算音頻裡面最相似的片段。在圖一的範例音頻裡,經過匹配之後,得出最有可能是person1。
第二種:Silence removal
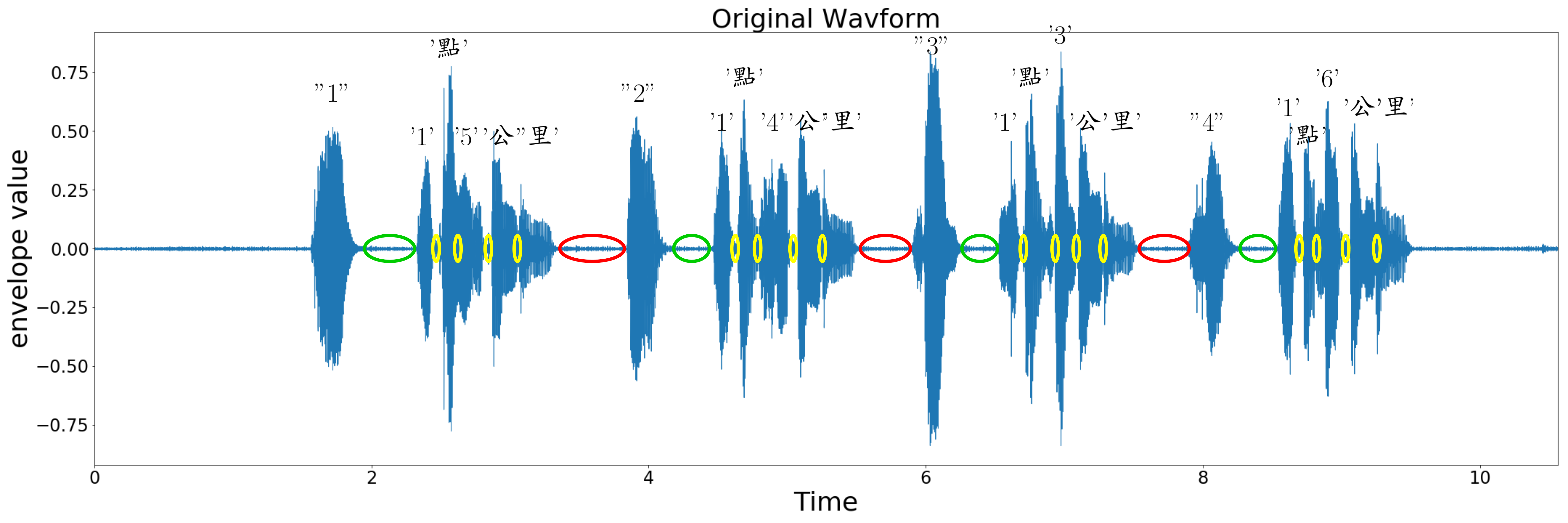
圖二 Choice Audio Silence interval 種類示意圖
圖二呈現choice audio 結構的示意圖,在波形震幅大的部分是語音訊號區域。震幅小的地方則是安靜(silence)區域。
基於圖二,我們可以把sentence segmentation問題變成silence removal問題。
圖二(紅)圈是inter-choice silence interval(選項間的安靜區域),在這個例子裡有4個選項,所以有3個inter-choice silence。inter-choice silence interval也是我們silence detection的目標。
圖二(綠)圈是keyword-content silence(編號跟選項間的安靜區域),這些安靜區域如果沒有被正確偵測出來,會造成兩個情況 1.被偵測為inter-choice silence interval 2. 被偵測為non-silence。
情況1會造成系統對sentence segmentation的誤判,一種是把多切出來的編號當作一個新的句子,所以雖然inter-choice有分割出來,但是系統因為句子比4句多,所以以為分割錯誤。
情況2理論上不會對sentence segmentation的結果產生影響,但是在後續語意辨識上會變成輸入的多餘雜訊。
kaggle資料庫裡面因為不是請專業的口語配音,所以inter-choice silence跟keyword-content silence的長短常常不固定,所以沒有辦法直接用silence interval的長度把兩者分開。[理想上inter-choice silence長於一個長度,google cloud speech的設定的閥值是1秒;keyword-content silence應該是小於800ms]
圖二(黃)圈inter-syllable(word) silence(字元間的安靜區域),inter-syllable silence通常都是一個很小的值(<100ms)。
inter-syllable silence的存在讓系統不能設定過小的min_silence_interval。
kaggle資料庫有極少的音頻講者會因為短暫遲疑讓字元間的安靜區域大於100ms。
kaggle資料庫有極少的音頻講者在唸編號跟內容沒有留短暫的間隔,而是快速講過,結果讓inter-syllable silence interval 跟 keyword-content silence interval的長度差不多,而難以用時間正確區分兩者。
理想的silence interval的大小
inter-choice silence interval > 1s
keyword-content silence interval 500~800ms
inter-syllable < 100ms