Speaker Diarization
Speaker diarization is the task of answering the question "who spoke when".
pyAudioAnalysis implementation is the variant based on [1].
There are four main algorithmic steps 1. Feature extraction 2. FLsD 3. Clustering 4. Smoothing
- Feature extraction (short-term and mid-term) step For each mid-term segment, the averages and standard deviations of the MFCCs are used, along with an estimate of the probabilities that segment belongs to a male or a female speaker (model
knnSpeakerFemaleMale) - (optional) FLsD step The mid-term feature statistic vectors in original feature space are projected onto the FLsD subspace.
- Clustering A k-means clustering method on either original feature space or the FLsD subspace. If the number of speakers is unknown, clustering process is repeated for a range of number of speakers and the Silhouette width criterion is used to find the optimal number of speakers.
- Smoothing A combination of a meidan filtering step on the extracted cluster IDs and a Viterbi Smoothing step.
Function speackDiarization() in audioSegmentation.py is used to extract a sequence of audio segments and respective cluster labels, given an audio file.
Command-line example:
python audioAnalysis.py speakerDiarization -i data/diarizationExample.wav --num 4
This command takes 3 arguments
-i <fileName>, fileName is the filename of audio recording as input.--num <numOfSpeakers (0 for unknown)>, numOfSpeakers is the number of speakers in audio recordings.--flsd, flag to enable FLsD method
Function evaluateSpeakerDiarization() also compute cluster purity and speaker purity.
Function evaluateSpeakerDiarization() is used in speakerDiarization() to compare the extracted sequence of speaker label and ground-truth label.
Ground-truth file is the file with .segments extension.
Function speakerDiarizationEvaluateScript() is used to extract the overall performance measures for a set of auto recordings, and respective `.segments. files, stored in directory.
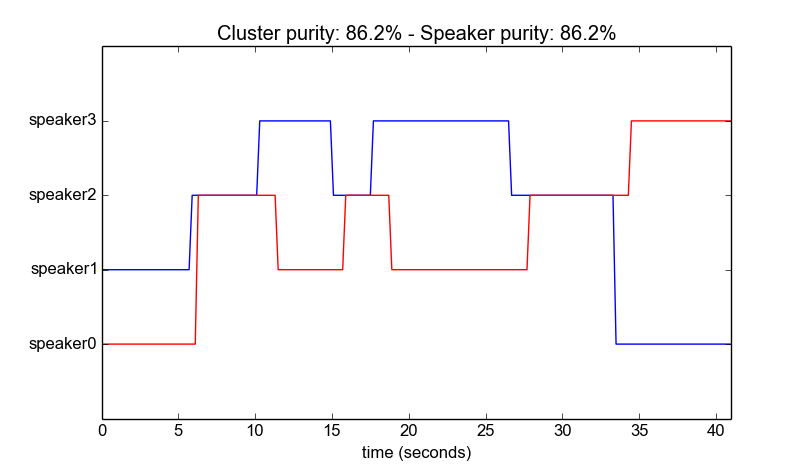 Figure 3 function
Figure 3 function speakerDiarization() result of data/diarizationExample.wav
Figure 3 is the result of typing
python audioAnalysis.py speakerDiarization -i data/diarizationExample.wav --num 4
紅色實現是ground-truth label,藍色實線是speaker diarization classification的結果,cluster purity是86.2%, speaker purity是86.2%.