Train in utility.py file
def train(train_q,val_q,plotFilePath,ACMNet_object,epoch,lr,batchSize,dropoutRate,choice,max_len) :
""" train for one epoch
Parameters
----------
train_q, val_q : list of dictionary
list of training data, each of which has structure of :
{
'imdb_key' : string
'question' : 2d numpy array (sentence, word_vec)
'answers' : 3d numpy array (5, sentence, word_vec)
'correct_index' : int
}
plotFilePath : string
path of plot files in word vector form
ACMNet_object : object instance
from class "MODEL" built up by tensorflow
epoch : int
lr : float
learning rate
batchSize : int
dropoutRate : float
choice : int
number of given choices (default 5)
max_len : list
only 3 elements are in the list,
["max length of sentence in plot", "max length of question", "max length of choice"]
"""
accuracy_list = {'train':[],'val':[]}
global_step = 0
filler = [0]*300
for i in range(epoch):
batchP = []
batchQ = []
batchAnsVec = []
batchAnsOpt = []
batchcount_epoch = 0
totalcost_epoch = 0
for question in train_q:
imdb_key = plotFilePath+question["imdb_key"]+".split.wiki.json"
with open(imdb_key) as data_file:
P = json.load(data_file)
batchP.append(P) #need check
batchQ.append(question["question"])
AnsOption = []
for j in range(choice):
if question["answers"][j]:
pass
else:
question["answers"][j] = [filler]
batchAnsVec.append(question["answers"][j])
AnsOption.append(0)
AnsOption[question["correct_index"]] = 1
batchAnsOpt.append(AnsOption)
cost = 0
if len(batchP) == batchSize:
batchcount_epoch+=1
global_step+=1
batchP = varSentencePadding(batchP,max_len[0])
batchQ = batchPadding(batchQ,max_len[1])
batchAnsVec = batchPadding(batchAnsVec,max_len[2])
cost = ACMNet_object.train(batchP,batchQ,batchAnsVec,batchAnsOpt,dropoutRate)
totalcost_epoch+=cost
print ('global_step '+str(global_step)+' ,Cost of Epoch ' + str(i) + ' batch ' + str(batchcount_epoch) + ": "+str(cost))
batchP = []
batchQ = []
batchAnsVec = []
batchAnsOpt = []
if global_step%200 == 0:
accuracy_list['val'].append(test(ACMNet_object,plotFilePath,val_q,batchSize,max_len,choice,True))
print('Val Accuracy: ',accuracy_list['val'])
if np.argmax(np.asarray(accuracy_list['val'])) == len(accuracy_list['val'])-1:
ACMNet_object.save(global_step)
if i > 30 and global_step%400 == 0:
accuracy_list['train'].append(test(ACMNet_object,plotFilePath,train_q,batchSize,max_len,choice,False))
print('Train Accuracy: ',accuracy_list['train'])
return accuracy_list
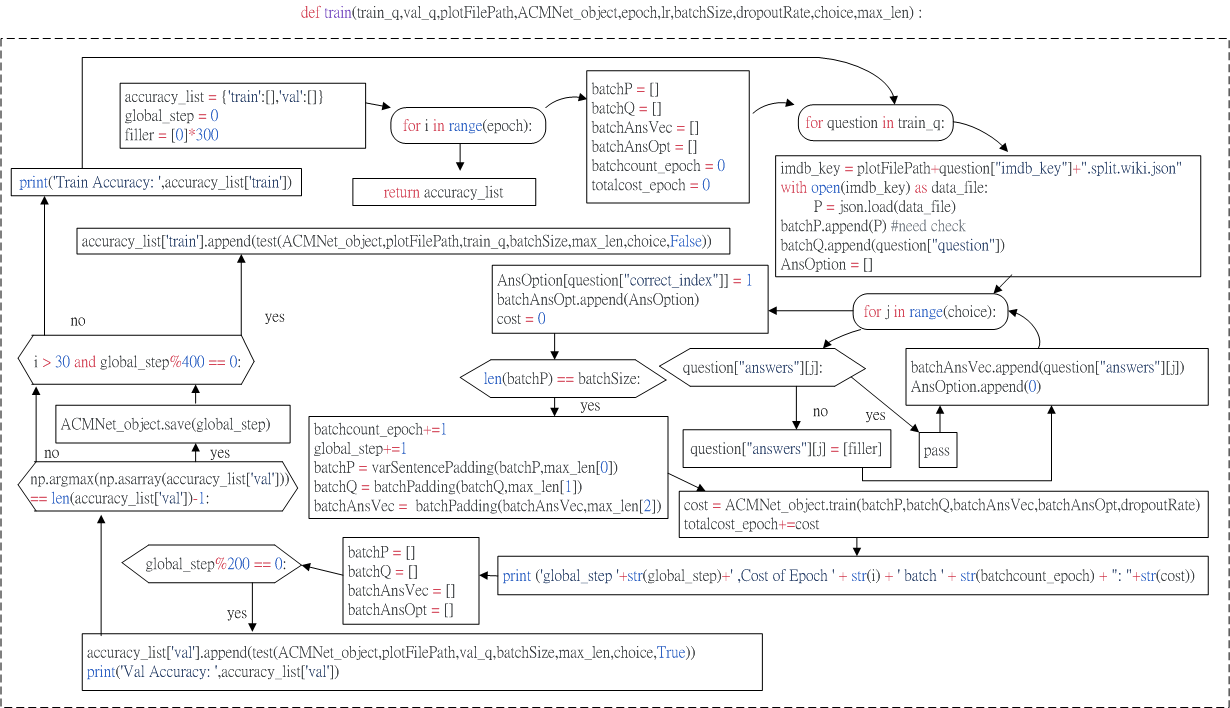 fig.1 def train in utility.py file.
fig.1 def train in utility.py file.
Fig.1 shows the flowchart of train function in utility.py file.