Fixed sound threshold level (librosa.effects.split)
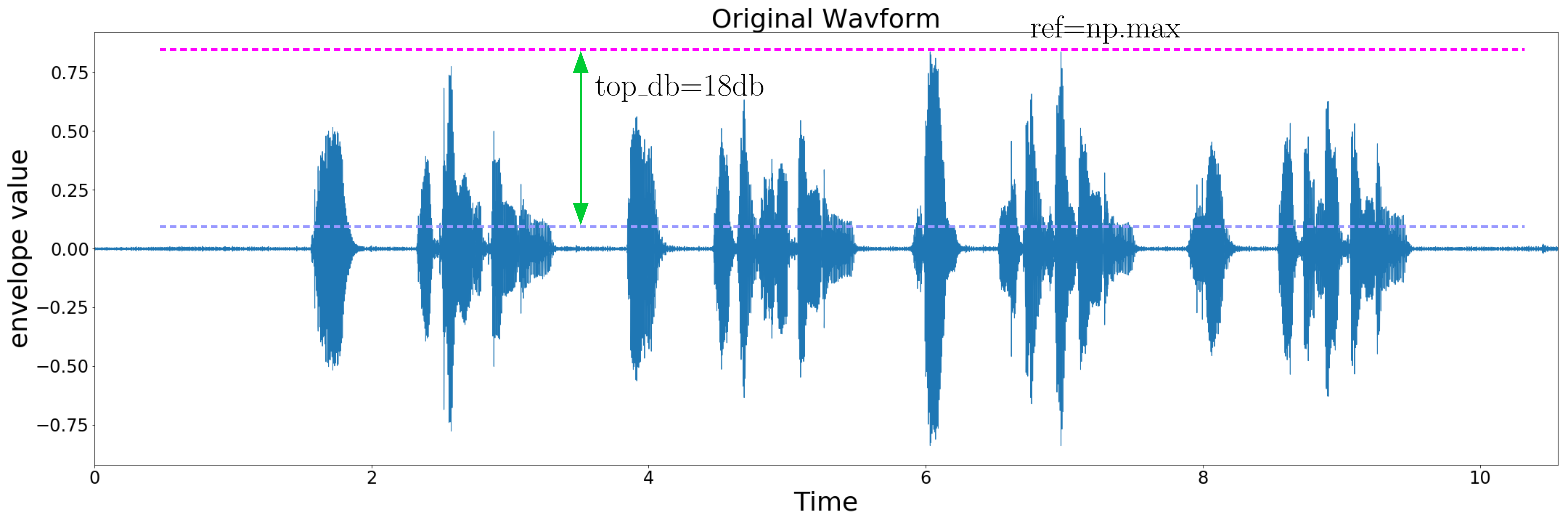 圖四 Silence Removal using librosa
圖四 Silence Removal using librosa effect.split function
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
import os
import glob
import re
speechFileList = sorted(glob.glob('./C/*.wav'))
for speechFile in speechFileList:
y, sr = librosa.load(speechFile,sr=None)
m = re.match(r'\./C/(.+)\.wav', speechFile)
filename = m.group(1)
print(filename)
#file.write(filename + '\n')
path = 'segment/{}'.format(filename)
print(path)
if not os.path.isdir(path):
os.makedirs(path)
librosa.display.waveplot(y,sr)
plt.savefig('{}/waveform_origin.png'.format(path))
plt.clf()
m = re.match(r'\./C/(.+)\.wav', speechFile)
ts = librosa.effects.split(y,top_db=18, ref=np.max)
i = 1
log_file = '{}/log.txt'.format(path)
with open(log_file,'w') as file:
for start_i, end_i in ts:
print('chunk {} in file {}'.format(i, filename))
file.write('chunk {} in file {}\n'.format(i, filename))
#print('time: {}s'.format(float(end_i-start_i+1)/sr))
file.write('time: {}s\n'.format(float(end_i-start_i+1)/sr))
plt.subplot(len(ts),1,i)
librosa.display.waveplot(y[start_i:end_i],sr)
librosa.output.write_wav('{}/segment{}.wav'.format(path,i),y[start_i:end_i],sr)
i = i+1
plt.autoscale()
plt.savefig('{}/waveform.png'.format(path))
plt.clf()