55 def ptb_raw_data(data_path=None):
56 """Load PTB raw data from data directory "data_path".
57
58 Reads PTB text files, converts strings to integer ids,
59 and performs mini-batching of the inputs.
60
61 The PTB dataset comes from Tomas Mikolov's webpage:
62
63 http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
64
65 Args:
66 data_path: string path to the directory where simple-examples.tgz has
67 been extracted.
68
69 Returns:
70 tuple (train_data, valid_data, test_data, vocabulary)
71 where each of the data objects can be passed to PTBIterator.
72 """
73
74 train_path = os.path.join(data_path, "ptb.train.txt")
75 valid_path = os.path.join(data_path, "ptb.valid.txt")
76 test_path = os.path.join(data_path, "ptb.test.txt")
77
78 word_to_id = _build_vocab(train_path)
79 train_data = _file_to_word_ids(train_path, word_to_id)
80 valid_data = _file_to_word_ids(valid_path, word_to_id)
81 test_data = _file_to_word_ids(test_path, word_to_id)
82 vocabulary = len(word_to_id)
83 return train_data, valid_data, test_data, vocabulary
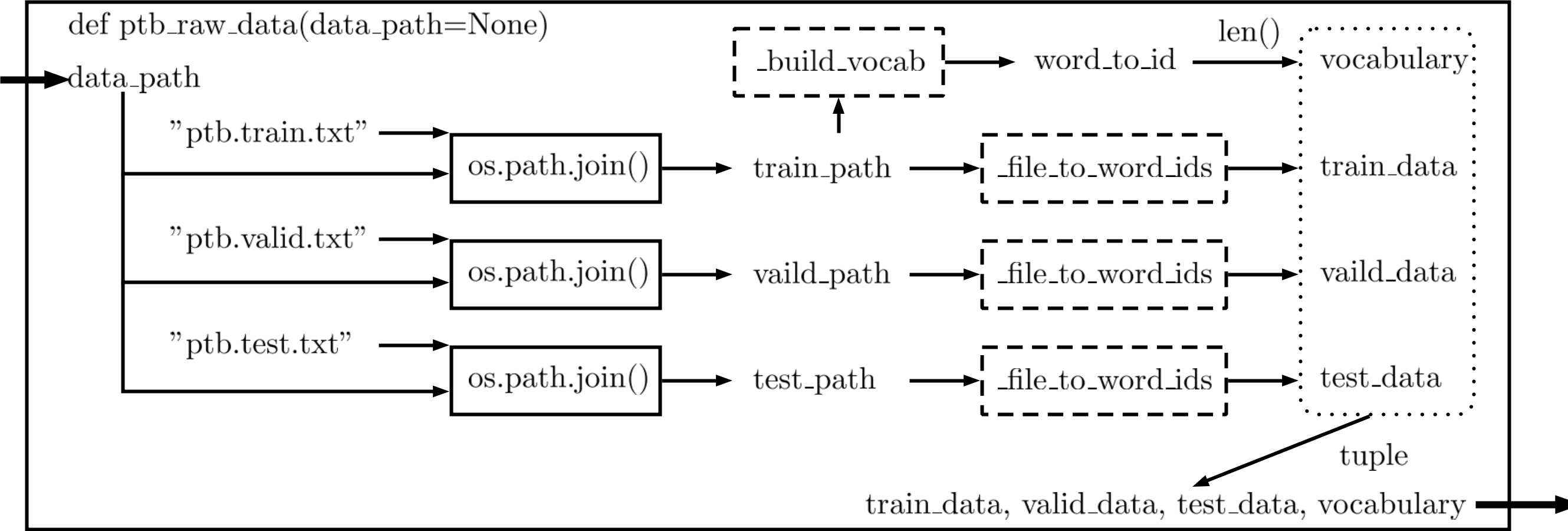 Figure 1: Flow chart of ptb_raw_data.py file
Figure 1: Flow chart of ptb_raw_data.py file
讀入資料夾路徑,資料夾應該會有ptb.train.txt, ptb.valid.txt, ptb.test.txt三個檔案,接下來透過_build_vocab建立train.txt的word_to_id,把train.txt, valid.txt, test.txt的文字轉換成id,train_data,valid_data,test_data是一個array of word id。最後一個vocabulary是word_to_id的數量,也代表字彙的數量,最後把train_data,valid_data,test_data,vocabulary變成一個4-element tuple輸出。