Supervised Transfer Learning
Experiment Results
Table 2 reports the result of our transfer learning on TOFEL-manual, TOFEL-ASR, MC160, and MC500, as well as the performance of the previous best models and several ablations that did not use pre-training or fine-tuning. From Table 2, We have the following observations.
![]() Table 2: Results of transfer learning on the target datasets. The number in parenthesis indicates the accuracy increased via transfer learning (compared to rows (a) and (g)). The best performance for each target dataset is marked in bold. We also include the results of the previous best performing models on the target datasets in last three rows.
Table 2: Results of transfer learning on the target datasets. The number in parenthesis indicates the accuracy increased via transfer learning (compared to rows (a) and (g)). The best performance for each target dataset is marked in bold. We also include the results of the previous best performing models on the target datasets in last three rows.
Transfer Learning helps. Rows (a) and Rows (g) show the respective results when the QACNN and MemN2N are trained directly on the target datasets without pre-training on MovieQA. Row (b) and (h) show results when the models are trained only on the MovieQA data. Rows (c) and (i) show results when model results when the models are trained on both MovieQA and each of the four target dataset, and tested on the respective target dataset. We observe that the results achieved in (a), (b), (c), (g), (h), and (i) are worse than their fine-tuned counterparts (d), (e), (f), and (j). Through transfer learning, both QAACNN and MemN2N perform better on all the target datasets. For example, QACNN only achieves 57.5% accuracy on MC160 without pre-training on MovieQA, but the accuracy increases by 18.9% with pre-training (rows (d) vs (a)). In addition, with transfer learning, QACNN outperforms the previous best models on TOFEL-manual by 7%, TOFEL-ASR (Fang et al., 2016) by 6.5%, MC160 (Wang et al., 2015) by 1.1%, and MC500 (Trishler et al., 2016) by 1.3%, and becomes the state-of-the-art on all target datasets.
Which QACNN parameters to transfer? (on QACNN) For the QACNN, the training parameters are , , , , . To better understand how transfer learning effects the performance of QACNN, we also report the results of keeping some parameters fixed and only fine-tuning other parameters. row (d) in Table 2 is result of fine-tune last fully-connected layer while keeping other parameters fixed. In row (e), it is fine-tuned the last two-fully-connected layers and . Finally, in row (f), the entire QACNN is fine-tuned. For TOFEL-manual, TOFEL-ASR, and MC500, QACNN performs the best when only last two fully-connected layer was fine-tuned; for MC160, it performs the best when only the last fully-connected layer was fine-tuned. Note that for training the QACNN, we follow the same procedure as in Liu et al. (2017), whereby pre-trained GloVe word vectors (Pennington et al., 2017) were used to initialize the embedding layer, which were not updated during training. Thus, the embedding layer does not depend on the training, and the effective vocabularies are the same.
Fine-tuning the entire model is not always best It is interesting to see that fine-tuning the entire QACNN doesn't necessarily produce the best result. For MC500, the accuracy of QACNN drops by 4.6% compared to just fine-tuning the last two fully-connected layers (rows (f) vs. (e)). We conjecture that this is due to the amount of training data of the target datasets - when the training set of the target dataset is too small, fine-tuning all the parameters of a complex model like QACNN may result in overfitting. This discovery align with other domains where transfer learning is well-studied such as object recognition (Yosinski et al., 2014)
A large quantity of mismatched training examples is better than a small training sets. We expected to see that a MemN2N, when trained directly on the target dataset without pre-training on MovieQA, would outperform a MemN2N pertain on MovieQA without fine-tuning on the target dataset (row (g) vs. (h)), since the model is evaluated on the target dataset. However, for the QACNN, this is suprisingly not the case - QACNN pre-trained on MovieQA without fine-tuning on the target dataset (rows (b) vs. (a)). We attribute this to the limited size of the target dataset and the complex structure of the QACNN (overfitting?).
Varying the fine-tuning data size We conducted experiments to study the relationship between the amount of training data from the target dataset for fine-tuning the model and performance. We first pre-train the models on MovieQA, then vary the training data size of the target used to fine-tune. Note that for QACNN, we only fine-tune the last two fully-connected layers instead of the entire model (How MemN2N be fine-tuned?), since doing so usually produces the best performance according to Table 2. The results are shown in Table [We only include the results of QACNN in Table3, but the results of MemN2N are very similar to QACNN.] As expected, the more training data is used for fine-tuning, the better the model's performance is. We also observe that the extent of improvement from using 0% to 25% of target training data is consistently larger than using from 25% to 50%, 50% to 75%, and 75% to 100%. Using the QACNN fine-tuned on TOFEL-manual as an example, the accuracy of the QACNN improves by 2.7% when varying the training size from 0% to 25%, but only improves 0.9%, 0.5%, and 0.7% when varying the training size from 25% to 50%, 50% to 75%, and 75% to 100%, respectively.
 Table 3: Results of varying sizes of the target datasets used for fine-tuning QACNN. The number in the parenthesis indicates the accuracy increases from using the previous percentage for fine-tuning to the current percentage.
Table 3: Results of varying sizes of the target datasets used for fine-tuning QACNN. The number in the parenthesis indicates the accuracy increases from using the previous percentage for fine-tuning to the current percentage.
Varying the pre-training data size We also vary the size of MovieQA for pre-training to study how large the source dataset should be to make transfer learning feasible. The results are shown in Table 4. We find that even a small amount of source data can help. For example, by using only 25% of MovieQA for pre-training, the accuracy increases 6.3% on MC160. This is because 25% of MovieQA training set (2,462 examples) is still much larger than the MC160 training set (280 examples). As the size of the source dataset increases, the performance of QACNN continues to improve.
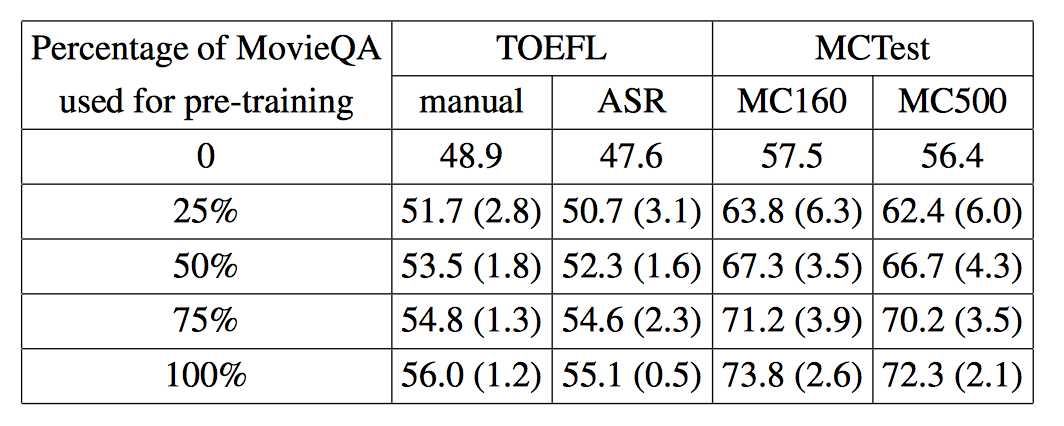 Table 4: Results of varying size of the MovieQA used for pre-training QACNN. The number in parenthesis indicates the accuracy increases from using the previous percentage for pre-training to the current percentage.
Table 4: Results of varying size of the MovieQA used for pre-training QACNN. The number in parenthesis indicates the accuracy increases from using the previous percentage for pre-training to the current percentage.
Analysis of the Questions Types
We are interested in understanding what types of questions benefit the most from transfer learning. According to the official guide to the TOFEL test, the question in TOFEL can be divided into 3 types. Type 1 question are for basic comprehension of the story. Type 2 questions go beyond basic comprehension, but test the understanding of the functions of utterances or the attitude the speaker expresses. Type 3 questions further require the ability of making connections between different parts of the story, making inferences, drawing conclusions, or forming generalizations. We used the split provided by Fang et al. (2016), which contains 70/18/34 Type 1/2/3 questions. We compare the performance of the QACNN and MemN@N on different types of questions in TOFEL-manual with and without pre-training on MovieQA, and show the results in Figure 2. From Figure 2we can observe that for both the QACNN and MemN2N, their performance on all three types of questions improves after pre-training, showing that the effectiveness of transfer learning is not limited to specific types of questions.
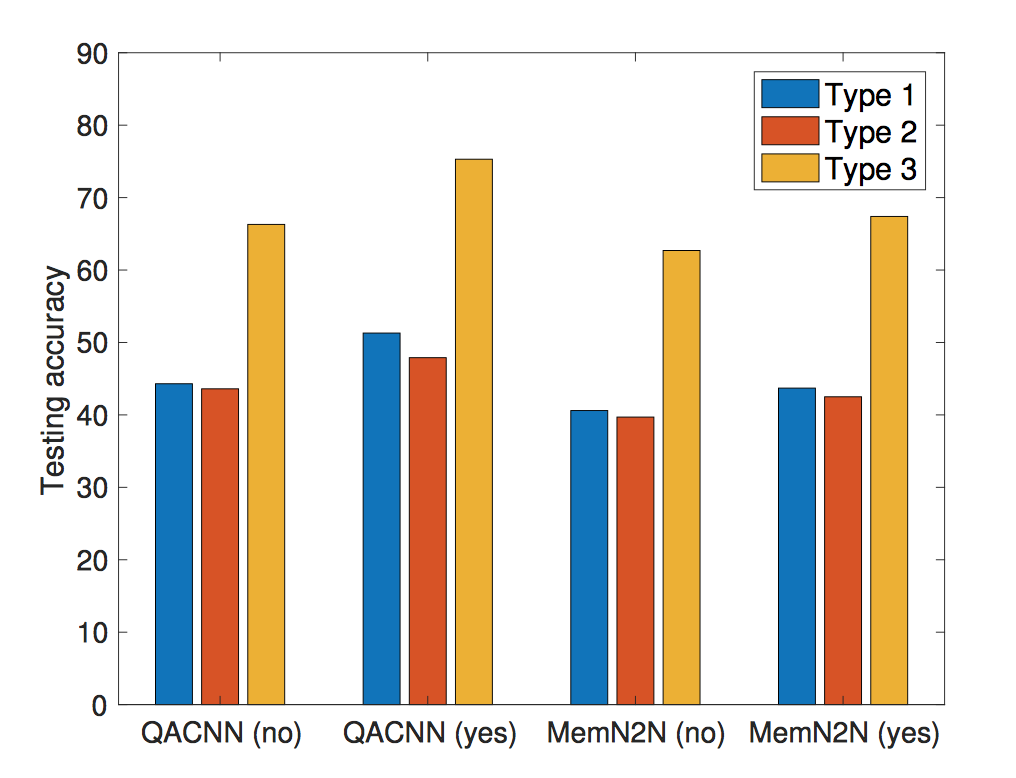 Figure 2: The performance of QACNN and MemN2N on different types of questions in TOFEL-manual with and without pre-training on MovieQA. 'No' in the parenthesis indicates the model are not pre-trained, while 'Yes' indicates the models are pre-trained on MovieQA.
Figure 2: The performance of QACNN and MemN2N on different types of questions in TOFEL-manual with and without pre-training on MovieQA. 'No' in the parenthesis indicates the model are not pre-trained, while 'Yes' indicates the models are pre-trained on MovieQA.