Attention-based Multi-hop Recurrent Neural Network (AMRNN) Model
MM 03/12/2018
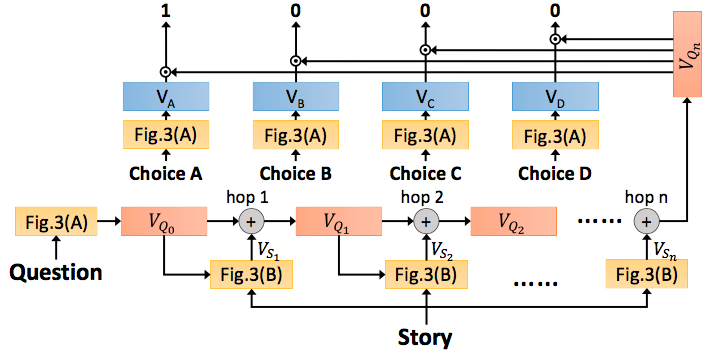
Fig. 2 The overall structure of the proposed Attention-based Multi-hop Recurrent Neural Network (AMRNN) model.
Fig.2 shows the overall structure of the AMRNN model.
The input of model includes the transcriptions of an audio story, a question and four answer choices, all represented as word sequences. The word sequence of the input question is represented as a question vector .
The attention mechanism is applied to extract the question-related information from the story.
The machine then goes through the story by the attention mechanism several times and obtain an answer selection vector . This answer selection vector is used to evaluate the confidence of each choice, and the choice with the highest score is taken as the output.
All the model parameters are jointly trained with the target where 1 for the correct choice and 0 otherwise.
Question Representation
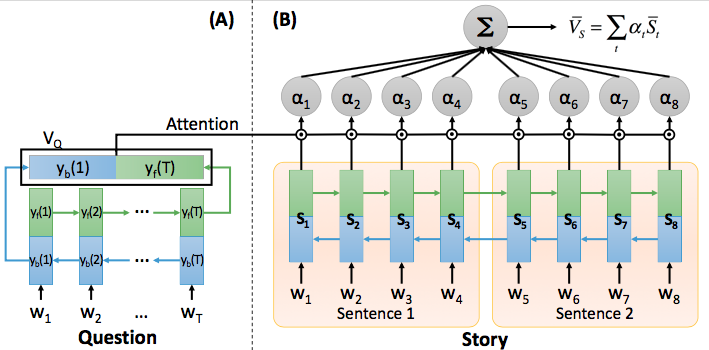
Fig. 3 (A) The Question Vector Representation and (B) The Attention Mechanism.
Fig.3 (A) shows the procedure of encoding the input question into a vector representation .
The input question is a sequence of words, , every word represented in 1-of-N encoding.
A bidirectional Gated Recurrent Unit (GRU) network [1]-[3] takes one word from the input question sequentially at a time.
In Fig.3(A), the hidden layer output of the forward GRU (green rectangle) at time index is denoted by , and that of the backward GRU (blue rectangle) is by . After looking through all the words in the question, the hidden layer output of forward GRU network at the last time index , and that of backward GRU network at the first time index , are concantenated to form the question vector representation , or .
The symbol denotes concatenation of two vectors.
Story Attention Module
Fig.3B shows the attention mechanism which takes the question vector obtained in Fig.2A and the story transcriptions as the input to encode the whole story into a story vector representations .
The story transcription is a long word sequence with many sentences, only two sentences are shown, and each sentence is with 4 words for simplicity.
There is a bidirectional GRU in Fig.3(B) encoding the whole story into a story vector representation .
The word vector representation of the -th word is constructed by a concatenating the hidden layer outputs of forward and backward GRU networks, which is .
Then the attention value for each time index is the cosine similarity between the question vector and the word vector representation of each word, .
With attention values , there can be two different attention mechanisms, word-level and sentence-level, to encode the whole story into the story vector representations .
The symbol denotes cosine similarity between two vectors.
Word-level Attention
All the attention values are normalized into such that they sum to one over the whole story. Then all the word vector from the bidirectional GRU network for every word in the story are weighted with this normalized attention value and sum to give the story vector, i.e.,
Sentence-Level Attention
Sentence-level attention means the model collects the information only att the end of each sentence. Therefore, the normalization is only performed over those words tat the end of the sentences to obtain .
The story vector representation is then , where only those words at the end of sentences (Eos) contribute to the weighted sum. So in the example of fig.2.
Hopping
The overall picture of the proposed model is shown in fig.2, in which fig.3 (A) and (B) of the complete proposed model. In the left of fig.2, the input question is first converted into a question vector by module in Fig.3(A). This is used to compute the attention values to obtain the story vector by the module in Fig.3(B). Then and are summed to form a new question vector .
This process is called the first hop (hop1) in fig.2.
The output of the first hop can be used to compute the new attention to obtain a new story vector .
This can be considered as the machine going over the story again to re-focus the story with a new question vector.
Again, and are summed to form (hop2).
After hops, the output of the last hop is used for the answer selection in Answer Selection.
Answer Selection
As in the upper part of fig.1, the same way previously used to encode the question into in fig.2(A) is used here to encode four choice into choice vector representation , , .
Then the coin similarity between the output of the last hop , and the choice vectors are computed, and the choice with highest similarity is chosen.
The symbol denotes concatenation of two vectors.
The symbol denotes cosine similarity between two vectors.
[0]
B. H. Tseng, S. S. Shen, H. Y. Lee, L. S. Lee, ``Towards machine comprehension of spoken content: Initial TOEFL listening comprehension test by machine," Towards machine comprehension of spoken content: Initial TOEFL listening comprehension test by machine, 2016.
[1] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio, “Empirical evaluation
of gated recurrent neural networks on sequence modeling,”
arXiv preprint arXiv:1412.3555, 2014.
[2] K. Cho, B. van Merrienboer, D. Bahdanau, and Y. Bengio, “On ¨
the properties of neural machine translation: Encoder-decoder approaches,”
arXiv preprint arXiv:1409.1259, 2014.
[3] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation
by jointly learning to align and translate,” arXiv preprint
arXiv:1409.0473, 2014.