# CNN 1
CNN1 is the "first stage CNN" part of QACNN model.
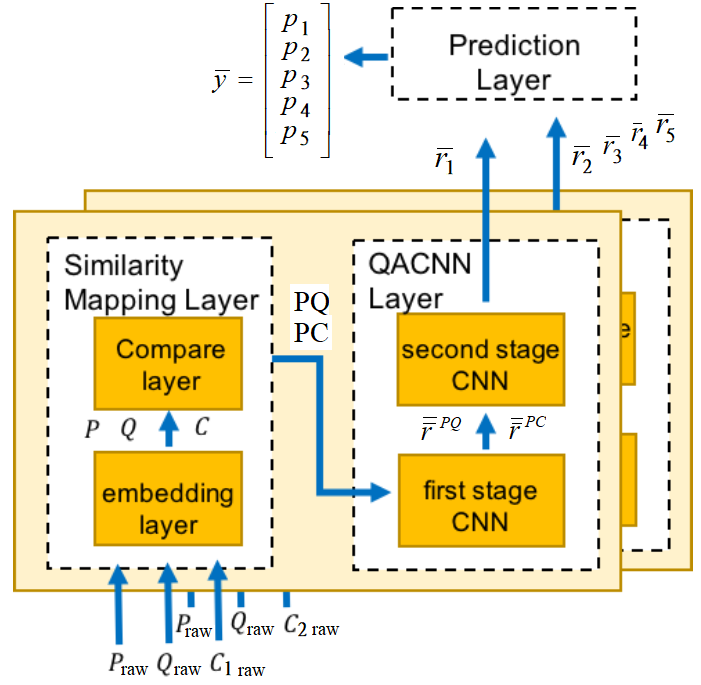
Fig.1 Overall data flow of QACNN model
CNN1 projects word level feature into sentence-level.
The output of CNN1 are and
is paragraph sentence features based on query.
is paragraph sentence features based on choice.
and
is the index for sentence, and N is the total number of sentence in paragraph.
CNN1 分成兩部分,第一部分是 generate attention map , 第二部分是 generate paragraph sentence features based on query , and generate paragraph sentence features based on choices .
#CNN1# 第一部分 Generate Attention Map
CNN1 第一部分計算 Attention Map from

Fig.2 # CNN1 # attention part, from to to word-level attention map .
Fig.2 shows the derivation of word-level attention map from
is -th sentence slice in , and CNN is applied on with convolution kernel . and represent width of kernel and number of kernel, respectively.
In convolution kernel , the superscript denotes attention map, and the subscript denotes the first stage CNN.
The generated feature is expressed as
where is the bias.
The query syntactic structure including the paragraph's location information can be learned with .
Sigmoid function is chosen as activation function in this stage.
Max pooling is performed on to find the largest elements between different kernels in the same location to generate word-level attention map for each sentence.
, note and .
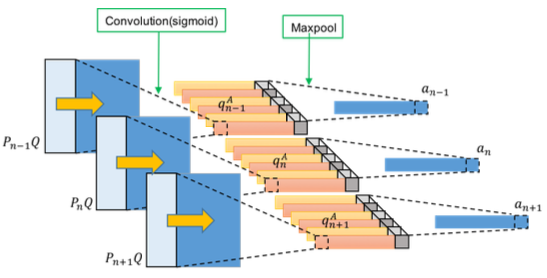
Fig.3 # CNN1 # attention part. Each paragraph sentences are used to generate its corresponding word-level attention map , .
Fig.3 shows the architecture of the attention map in first stage CNN, and all sentences in paragraph are used.
#CNN1# 第二部分 Generate paragraph sentence features based on query and choices
CNN1 第二部分計算 paragraph's sentence features based on the query and paragraph's sentence features based on the choice
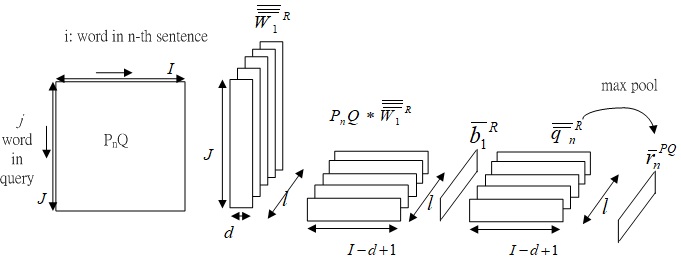
Fig.4 Derivation of paragraph feature based on query, .
Fig.4 shows the derivation of paragraph feature based on query, .
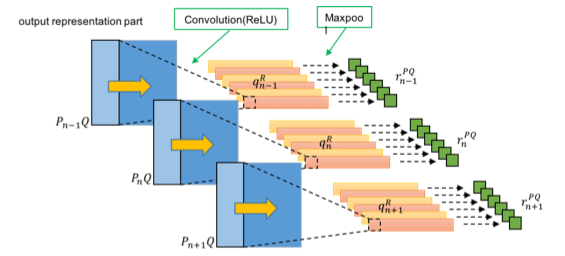
Fig.5 All paragraph's sentence feature based on query, .
Fig.5 shows all paragraph's sentence feature based on query, .
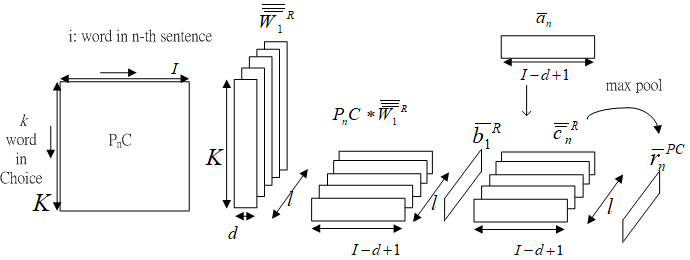
Fig.6 Derivation of paragraph's sentence feature based on choice, .
Fig.6 shows the derivation of paragraph's sentence feature based on choice, .
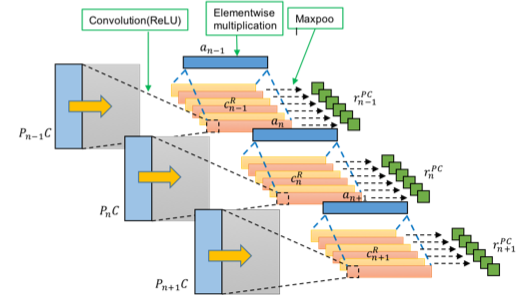
Fig.7 All paragraph's sentence feature based on choice, .
Fig.7 shows all paragraph's sentence feature based on choice, .
and are two output representation part of first-stage CNN architecture.
Kernels and bias are applied to to acquire query-based sentence features.
Identical kernels and bias are applied to to aggregate pattern of location relationship and acquire choice-based sentence features. The superscript denotes output representation
is multiplied by the word-level attention map through the first dimension.
,
The max pool operations are applied on and horizontally with kernel shape to get the query-based sentence features and choice-based sentence features .
#CNN1 overall flowchart
 Fig.1 __init__() 函數中 # CNN1 # 流程
Fig.1 __init__() 函數中 # CNN1 # 流程
Fig.1 為 __init__() 函數中 # CNN1 # 流程
WQ1 is , the convolution kernel, for attention map in CNN1
bQ1 is , the bias, for attention map in CNN1
W1 is , the convolution kernel, for the paragraph's sentence feature based on query and the paragraph's sentence feature based on choice
b1 is , the bias for paragraph's sentence features based on query and the paragraph's sentence feature based on choice
# CNN1 # 1~15 行
1 ### CNN 1 ###
2 pooled_outputs_PQ_1 = []
3 pooled_outputs_PA_1 = []
4 pooled_outputs_PB_1 = []
5 pooled_outputs_PC_1 = []
6 pooled_outputs_PD_1 = []
7 pooled_outputs_PE_1 = []
8 for i, filter_size in enumerate(self.filter_size):
9 with tf.name_scope("conv1-maxpool-%s" % (filter_size)):
10 filter_shape = [filter_size,max_len[2], 1, self.filter_num]
11 W1 = tf.get_variable(name="W1-%s"%(filter_size), shape=filter_shape,initializer=tf.contrib.layers.xavier_initializer())
12 b1 = tf.Variable(tf.constant(0.1, shape=[self.filter_num]), name="b1")
13
14 WQ1 = tf.get_variable(name="WQ1-%s"%(filter_size), shape=filter_shape,initializer=tf.contrib.layers.xavier_initializer())
15 bQ1 = tf.Variable(tf.constant(0.1, shape=[self.filter_num]), name="bQ1")
2~7行,定義變數 pooled_outputs_PQ_1, pooled_outputs_PA_1,...pooled_outputs_PE_1
2 pooled_outputs_PQ_1 = []
3 pooled_outputs_PA_1 = []
4 pooled_outputs_PB_1 = []
5 pooled_outputs_PC_1 = []
6 pooled_outputs_PD_1 = []
7 pooled_outputs_PE_1 = []
pooled_outputs_PQ_1, pooled_outputs_PA_1, ..., pooled_outputs_PE_1 為空的 list。
底線1, "_1", 指的是CNN1的意思
pooled_outputs_PQ_1 is , the paragraph's sentence features based on the query.
pooled_outputs_PA_1, ..., pooled_outputs_PE_1 are merged to , the paragraph's sentence features based on the choices.
8~15行,定義 W1, b1, WQ1, bQ1
8 for i, filter_size in enumerate(self.filter_size):
9 with tf.name_scope("conv1-maxpool-%s" % (filter_size)):
10 filter_shape = [filter_size,max_len[2], 1, self.filter_num]
11 W1 = tf.get_variable(name="W1-%s"%(filter_size), shape=filter_shape, initializer=tf.contrib.layers.xavier_initializer())
12 b1 = tf.Variable(tf.constant(0.1, shape=[self.filter_num]), name="b1")
13
14 WQ1 = tf.get_variable(name="WQ1-%s"%(filter_size), shape=filter_shape, initializer=tf.contrib.layers.xavier_initializer())
15 bQ1 = tf.Variable(tf.constant(0.1, shape=[self.filter_num]), name="bQ1")
第 8 行,self.filter_size ( ) is the width of kernel, 在程式中被設定是 [1, 3, 5],因此 for loop 會執行三次。
第一次 ,第二次 ,第三次 。
filter_shape 指的是 filter 的形狀,
,
是 total number of words in choice sentence (note 在程式中被設定是 50)
self.filter_num ( ), is number of kernel in CNN1 (note 在程式中被設定是 128)

Fig.2 W1 and WQ1 的 shape 由 filter_shape 指定。
Fig.2 呈現程式的第11、14行定義出W1、WQ1。
11 W1 = tf.get_variable(name="W1-%s"%(filter_size), shape=filter_shape, initializer=tf.contrib.layers.xavier_initializer())
11 行程式指 W1 的 shape 是 filter_shape,它的名字將是W1-d, 其中d是width of kernel。W1由tf.contrib.layers.xavier_initializer()做初始化。
WQ1 is , the convolution kernel on .
bQ1 is , the bias on .
W1 is , the convolution kernel for generating paragraph's sentence features based on query and choice.
b1 is , the bias for generating paragraph's sentence features based on query and choice.
#CNN1# 程式16-158行
16 hiddenPQ_1 = []
17 hiddenPA_1 = []
18 hiddenPB_1 = []
19 hiddenPC_1 = []
20 hiddenPD_1 = []
21 hiddenPE_1 = []
22 for sentence_ind in range(len(PQAttention)):
23 convPQ_attention = tf.nn.conv2d(
24 PQAttention[sentence_ind],
25 WQ1,
26 strides=[1, 1, 1, 1],
27 padding="VALID",
28 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
29 convPQ_1 = tf.nn.conv2d(
30 PQAttention[sentence_ind],
31 W1,
32 strides=[1, 1, 1, 1],
33 padding="VALID",
34 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
35 convPA_1 = tf.nn.conv2d(
36 PAAttention[sentence_ind],
37 W1,
38 strides=[1, 1, 1, 1],
39 padding="VALID",
40 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
41 convPB_1 = tf.nn.conv2d(
42 PBAttention[sentence_ind],
43 W1,
44 strides=[1, 1, 1, 1],
45 padding="VALID",
46 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
47 convPC_1 = tf.nn.conv2d(
48 PCAttention[sentence_ind],
49 W1,
50 strides=[1, 1, 1, 1],
51 padding="VALID",
52 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
53 convPD_1 = tf.nn.conv2d(
54 PDAttention[sentence_ind],
55 W1,
56 strides=[1, 1, 1, 1],
57 padding="VALID",
58 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
59 convPE_1 = tf.nn.conv2d(
60 PEAttention[sentence_ind],
61 W1,
62 strides=[1, 1, 1, 1],
63 padding="VALID",
64 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
65
66 wPQ_1 = tf.transpose(tf.sigmoid(tf.nn.bias_add(convPQ_attention,bQ1)),[0,3,2,1])
67 wPQ_1 = tf.nn.dropout(wPQ_1,self.dropoutRate)
68 wPQ_1 = tf.nn.max_pool(
69 wPQ_1,
70 ksize=[1,self.filter_num, 1,1],
71 strides=[1, 1, 1, 1],
72 padding='VALID',
73 name="pool_pq") ## [batch_size,1,1,wordNumberP- filter_size
74 wPQ_1 = tf.transpose(tf.tile(wPQ_1,[1,self.filter_num,1,1]),[0,3,2,1])
75 onesentence_hiddenPQ_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPQ_1, b1), name="relu"),self.dropoutRate)
76 hiddenPQ_1.append(onesentence_hiddenPQ_1)
77 onesentence_hiddenPA_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPA_1, b1), name="relu"),self.dropoutRate)*wPQ_1
78 hiddenPA_1.append(onesentence_hiddenPA_1)
79 onesentence_hiddenPB_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPB_1, b1), name="relu"),self.dropoutRate)*wPQ_1
80 hiddenPB_1.append(onesentence_hiddenPB_1)
81 onesentence_hiddenPC_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPC_1, b1), name="relu"),self.dropoutRate)*wPQ_1
82 hiddenPC_1.append(onesentence_hiddenPC_1)
83 onesentence_hiddenPD_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPD_1, b1), name="relu"),self.dropoutRate)*wPQ_1
84 hiddenPD_1.append(onesentence_hiddenPD_1)
85 onesentence_hiddenPE_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPE_1, b1), name="relu"),self.dropoutRate)*wPQ_1
86 hiddenPE_1.append(onesentence_hiddenPE_1)
87 hiddenPQ_1 = tf.concat(hiddenPQ_1, 1) ## [batch,max_plot_len*(wordNumberP- filter_size + 1), 1,self.filter_num]
88 hiddenPA_1 = tf.concat(hiddenPA_1, 1)
89 hiddenPB_1 = tf.concat(hiddenPB_1, 1)
90 hiddenPC_1 = tf.concat(hiddenPC_1, 1)
91 hiddenPD_1 = tf.concat(hiddenPD_1, 1)
92 hiddenPE_1 = tf.concat(hiddenPE_1, 1)
93
94 hiddenPQ_1 = tf.reshape(tf.squeeze(hiddenPQ_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num]) ## [batch,max_plot_len,(wordNumberP- filter_size + 1),self.filter_num]
95 hiddenPA_1 = tf.reshape(tf.squeeze(hiddenPA_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
96 hiddenPB_1 = tf.reshape(tf.squeeze(hiddenPB_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
97 hiddenPC_1 = tf.reshape(tf.squeeze(hiddenPC_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
98 hiddenPD_1 = tf.reshape(tf.squeeze(hiddenPD_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
99 hiddenPE_1 = tf.reshape(tf.squeeze(hiddenPE_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
100
101 pooledPQ_1 = tf.nn.max_pool(
102 hiddenPQ_1,
103 ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
104 strides=[1, 1, 1, 1],
105 padding='VALID',
106 name="pool") ## [batch_size, max_plot_len, 1, self.filter_num]
107 pooled_outputs_PQ_1.append(pooledPQ_1)
108
109 pooledPA_1 = tf.nn.max_pool(
110 hiddenPA_1,
111 ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
112 strides=[1, 1, 1, 1],
113 padding='VALID',
114 name="pool") ## [batch_size, max_plot_len, 1, self.filter_num]
115 pooled_outputs_PA_1.append(pooledPA_1)
116
117 pooledPB_1 = tf.nn.max_pool(
118 hiddenPB_1,
119 ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
120 strides=[1, 1, 1, 1],
121 padding='VALID',
122 name="pool") ##[batch_size, max_plot_len, 1, self.filter_num]
123
124 pooled_outputs_PB_1.append(pooledPB_1)
125
126 pooledPC_1 = tf.nn.max_pool(
127 hiddenPC_1,
128 ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
129 strides=[1, 1, 1, 1],
130 padding='VALID',
131 name="pool") ##[batch_size, max_plot_len, 1, self.filter_num]
132
133 pooled_outputs_PC_1.append(pooledPC_1)
134
135 pooledPD_1 = tf.nn.max_pool(
136 hiddenPD_1,
137 ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
138 strides=[1, 1, 1, 1],
139 padding='VALID',
140 name="pool") ##[batch_size, max_plot_len, 1, self.filter_num
141
142 pooled_outputs_PD_1.append(pooledPD_1)
143
144 pooledPE_1 = tf.nn.max_pool(
145 hiddenPE_1,
146 ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
147 strides=[1, 1, 1, 1],
148 padding='VALID',
149 name="pool") ##[batch_size, max_plot_len, 1, self.filter_num]
150
151 pooled_outputs_PE_1.append(pooledPE_1)
152
153 h_pool_PQ_1 = tf.transpose(tf.concat(pooled_outputs_PQ_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
154 h_pool_PA_1 = tf.transpose(tf.concat(pooled_outputs_PA_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
155 h_pool_PB_1 = tf.transpose(tf.concat(pooled_outputs_PB_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
156 h_pool_PC_1 = tf.transpose(tf.concat(pooled_outputs_PC_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
157 h_pool_PD_1 = tf.transpose(tf.concat(pooled_outputs_PD_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
158 h_pool_PE_1 = tf.transpose(tf.concat(pooled_outputs_PE_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
16~21行,定義變數 hiddenPQ_1, hiddenPA_1, ..., hiddenPE_1
16 hiddenPQ_1 = []
17 hiddenPA_1 = []
18 hiddenPB_1 = []
19 hiddenPC_1 = []
20 hiddenPD_1 = []
21 hiddenPE_1 = []
hiddenPQ_1, hiddenPA_1, ..., hiddenPE_1 變數為空的 list。
第22行 for loop, from 0, 1, ... to (N-1)
22 for sentence_ind in range(len(PQAttention)):
第22行將for loop each sentence in paragraph, from 0 to N-1。
,所以 len(PQAttention) = N
range(len(PQAttention)) 會產生一個 list,內容是 [0, 1, ..., N-1]。
sentence_ind 就是 n。
CNN1 第一部分 Generate Attention Map (wPQ_1) of First stage

fig.xx 計算 attention map (wPQ_1) 的流程
fig.xx 將計算
其中 wPQ_1 是 再加上 batch size 維度
第23~28行 compute the convolution of PnQ and the kernel WQ1
23 convPQ_attention = tf.nn.conv2d(
24 PQAttention[sentence_ind],
25 WQ1,
26 strides=[1, 1, 1, 1],
27 padding="VALID",
28 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
第23~28行將執行

Fig.xx convolution of PQAttention[sentence_ind] and WQ1
Fig.xx shows the schematic of the convolution of and .
"PQAttention[sentence_ind]" _refers to _
"WQ1" refers to .
strides of convolution is [1, 1, 1, 1]
第66行 convPQ_attention 加上 bias,計算 sigmoid,以及轉置
66 wPQ_1 = tf.transpose(tf.sigmoid(tf.nn.bias_add(convPQ_attention,bQ1)),[0,3,2,1])

fig.xx Schematic of add bias and sigmoid into convPQ_attention
fig.xx shows the schematic corresponds to line 66.
line 66 computes
"wPQ1" is , "bQ1" is .
before transpose, 維度為 :
轉置後, 維度為
第67行 wPQ_1 dropout
67 wPQ_1 = tf.nn.dropout(wPQ_1,self.dropoutRate)
dropout 隨機將 Hidden Layer 一定比例 (self.dropoutRate) 前一層到下一層的連線刪去。程式中 self.dropoutRate 被設定為 0.8
第68~73行 wPQ_1 取 max pool
68 wPQ_1 = tf.nn.max_pool(
69 wPQ_1,
70 ksize=[1,self.filter_num, 1,1],
71 strides=[1, 1, 1, 1],
72 padding='VALID',
73 name="pool_pq") ## [batch_size,1 ,1 ,wordNumberP-filter_size+1

fig.xx Schematic of max_pool in
fig.xx shows the schematic of max_pool in
wPQ_1 is , the word-level attention map
ksize is the size of the window for each dimension of the input tensor.
第74行 wPQ_1 展開與轉置
74 wPQ_1 = tf.transpose(tf.tile(wPQ_1,[1,self.filter_num,1,1]),[0,3,2,1])

fig.xx Schematic of tf.tile (, [1, l, 1, 1])
fig.xx 維度是 ,依 展開後,維度變為
轉置後維度為
CNN1 第二部分 Generate paragraph sentence features based on query (h_pool_PQ_1)
 fig.xx 計算 paragraph sentence features based on query (h_pool_PQ_1) 的流程
fig.xx 計算 paragraph sentence features based on query (h_pool_PQ_1) 的流程
fig.xx 將計算
其中 h_pool_PQ_1 是 再加上 batch size 維度
第29~34行 compute the convolution of PnQ and the kernel W1 to convPQ_1
29 convPQ_1 = tf.nn.conv2d(
30 PQAttention[sentence_ind],
31 W1,
32 strides=[1, 1, 1, 1],
33 padding="VALID",
34 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]

Fig.xx convolution of PQAttention[sentence_ind] and W1
Fig.xx show the schematic of the convolution of PQAttention[sentence_ind] and W1.
PQAttention[sentence_ind] is ,
W1 is
convPQ_1 is
strides of convolution is [1, 1, 1, 1]
第75行 計算 onesentence_hiddenPQ_1
75 onesentence_hiddenPQ_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPQ_1, b1), name="relu"),self.dropoutRate)
75行將執行

fig.xx Schematic of computing
fig.xx 計算 的示意圖
b1 is ,
onesentence_hiddenPQ_1 is
dropout 隨機將 Hidden Layer 一定比例 (self.dropoutRate) 上一層到下一層的連結刪去。程式中 self.dropoutRate 被設定為 0.8
第76行 將 N 個 onesentence_hiddenPQ_1 合併為 hiddenPQ_1
76 hiddenPQ_1.append(onesentence_hiddenPQ_1)

fig.xx Schematic of onesentence_hiddenPQ_1 append to hiddenPQ_1
fig.xx shows onesentence_hiddenPQ_1 append to hiddenPQ_1
第87行 串接 (concat) hiddenPQ_1
87 hiddenPQ_1 = tf.concat(hiddenPQ_1, 1) ## [batch,max_plot_len*(wordNumberP- filter_size + 1), 1,self.filter_num]

fig.xx Schematic of tf.concat of hiddenPQ_1
hiddenPQ_1 concat 後維度是四維
第94行 hiddenPQ_1 squeeze and reshape
94 hiddenPQ_1 = tf.reshape(tf.squeeze(hiddenPQ_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num]) ## [batch,max_plot_len,(wordNumberP- filter_size + 1),self.filter_num]
tf.squeeze removes dimensions of size 1 from the shape of a tensor.
所以 tf.squeeze(hiddenPQ_1) 後的維度是三維
再 reshape 後是四維
第101~106行 hiddenPQ_1 計算 max_pool
101 pooledPQ_1 = tf.nn.max_pool(
102 hiddenPQ_1,
103 ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
104 strides=[1, 1, 1, 1],
105 padding='VALID',
106 name="pool") ## [batch_size, max_plot_len, 1, self.filter_num]

fig.xx pooledPQ_1 is computed max_pool by hiddenPQ_1
fig.xx shows pooledPQ_1 is computed max_pool by hiddenPQ_1.
第107行 將 3 個 pooledPQ_1 合併為 pooled_outputs_PQ_1
107 pooled_outputs_PQ_1.append(pooledPQ_1)

fig.xx pooled_outputs_PQ_1 is appended by pooledPQ_1
fig.xx shows pooled_outputs_PQ_1 is appended by pooledPQ_1 three times when d=1, d=3 and d=5
第153行 derivation to paragraph feature (h_pool_PQ_1) based on query
153 h_pool_PQ_1 = tf.transpose(tf.concat(pooled_outputs_PQ_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]

fig.xx Schematic of tf.concat(pooled_outputs_PQ_1, 3)
fig.xx 表示 pooled_outputs_PQ_1 依照第三個維度 (3l) 連接
經過 tf.transpose 後得到 h_pool_PQ_1
CNN1 第二部分 Generate Paragraph sentence feature based on chioce (h_pool_PA_1, ..., h_pool_PE_1)
modify bQ1 and arrow
 fig.xx 計算 paragraph sentence features based on choice (以 h_pool_PA_1 為例) 的流程
fig.xx 計算 paragraph sentence features based on choice (以 h_pool_PA_1 為例) 的流程
fig.xx 將計算 . 有五個 :
is multiplied by the word-level attention map through the first dimension.
其中 h_pool_PA_1 是 再加上 batch size 維度
第29~34行 compute the convolution of PAAttention and the kernel W1
29 convPA_1 = tf.nn.conv2d(
30 PAAttention[sentence_ind],
31 W1,
32 strides=[1, 1, 1, 1],
33 padding="VALID",
34 name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]

PnQ error, J => K
Fig.xx convolution of PAAttention[sentence_ind] and W1
Fig.xx show the schematic of the convolution of PAAttention[sentence_ind] and W1.
同理,第41~64行 convolution 計算 convPB_1, convPC_1, convPD_1 and convPE_1
第77行 convPA_1 加上 bias、計算 relu 與 dropout、乘上 wPQ_1
77 onesentence_hiddenPA_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPA_1, b1), name="relu"),self.dropoutRate)*wPQ_1

fig.xx Schematic of onesentence_hiddenPA_1
onesentence_hiddenPA_1 為 convPA_1 加上 bias,計算 relu 與 dropout,以及乘上 (wPQ_1) 得到
第78行 將 N 個 onesentence_hiddenPA_1 合併為 hiddenPA_1
78 hiddenPA_1.append(onesentence_hiddenPA_1)
第88行 串接 (concat) hiddenPA_1
88 hiddenPA_1 = tf.concat(hiddenPA_1, 1)
第95行 hiddenPA_1 squeeze and reshape
95 hiddenPA_1 = tf.reshape(tf.squeeze(hiddenPA_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
tf.squeeze removes dimensions of size 1 from the shape of a tensor.
tf.squeeze(hiddenPA_1) 後的維度是三維
再 reshape 後是四維
第109~114行 hiddenPA_1 計算 max_pool
109 pooledPA_1 = tf.nn.max_pool(
110 hiddenPA_1,
111 ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
112 strides=[1, 1, 1, 1],
113 padding='VALID',
114 name="pool") ## [batch_size, max_plot_len, 1, self.filter_num]
fig.xx pooledPQ_1 is computed max_pool by hiddenPQ_1
fig.xx shows pooledPQ_1 is computed max_pool by hiddenPQ_1.
第115行 將 3 個 pooledPA_1 合併為 pooled_outputs_PA_1
115 pooled_outputs_PA_1.append(pooledPA_1)
fig.xx pooled_outputs_PQ_1 is appended by pooledPQ_1
fig.xx shows pooled_outputs_PQ_1 is appended by pooledPQ_1 three times when d=1, d=3 and d=5
第154行 derivation to paragraph feature (h_pool_PA_1) based on choice A
154 h_pool_PA_1 = tf.transpose(tf.concat(pooled_outputs_PA_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
pooled_outputs_PA_1 依照第三個維度 (3l) 連接
經過 tf.transpose 後得到 h_pool_PA_1
同理得出 h_pool_PB_1, h_pool_PC_1, h_pool_PD_1, h_pool_PE_1, derivation to paragraph feature based on choice B, C, D and E.