Inference- generate translations
While you are training your NMT models (and once you have trained models), you can obtain translations given previously unseen source sentences. This process is called inference. There is a clear distinction between training and inference (testing): at inference time, we only have access to the source sentence, i.e., encoder_inputs. There are many was to perform decoding. Decoding methods include greedy, sampling, and beam-search decoding. Here, we will discuss the greedy decoding strategy.
The idea is simple and we illustrate it in Figure 3:
- We still encode the source sentence in the same way as during training to obtain an encoder_state, and this encoder_state is used to initialize the decoder.
- The decoding (translation) process is started as soon as the decoder receives a starting symbol "\<s>" (refer as tgt_sos_id in our code).
- For each timestep on the decoder side, we treat the RNN's output as a set of logits. We choose the most likely word, the id associated with the maximum logit value, as the emitted word (this is the "greedy" behavior). For example in Figure 3, the word "moi" has the highest translation probability in the first decoding step. We then feed this word as input to the next timestep.
- The process continues until the end-of-sentence marker "\</s>" is produced as an output symbol (refer as tgt_eos_id in our code).
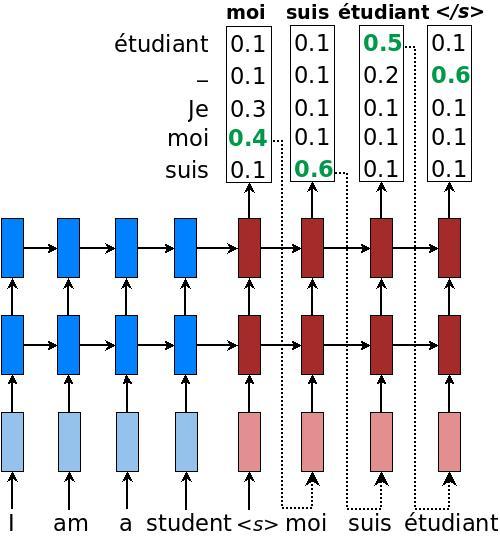
Figure 3. Greedy decoding - example of how a trained NMT model produces a translation for a source sentence "Je suis étudiant" using greedy search.
Step 3 is what makes inference different from training. Instead of always feeding the correct target words as an input, inference uses words predicted by the mode. Here's the code to achieve greedy decoding. It is very similar to the training decoder.
# Helper
helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(
embedding_decoder,
tf.fill([batch_size], tgt_sos_id), tgt_eos_id)
# Decoder
decoder = tf.contrib.seq2seq.BasicDecoder(
decoder_cell, helper, encoder_state,
output_layer = projection_layer)
# Dynamic decoding
outputs, _ = tf.contrib.seq2seq.dynamic_decoder(
decoder, maximum_iterations = maximum_iterations)
translations = outputs.sample_id
Here, we use GreedyEmbeddingHelper instead of TrainingHelper. Since we do not know the target sequence lengths in advance, we use maximum_iterations to limit the translation lengths. One heuristic is to decode up to two times the source sentence lengths.
maximum_iterations = tf.round(tf.reduce_max(source_sequence_length) * 2)
Having trained a model, we can now create an inference file and translate some sentences:
cat > /tmp/my_infer_file.vi
# (copy and paste some sentences from /tmp/nmt_data/tst2013.vi)
python -m nmt.nmt \
--out_dir = /tmp/nmt_model \
--inference_input_file = /tmp/my_infer_file.vi \
--inference_output_file = /tmp/nmt_model/output_infer
cat /tmp/nmt_model/output_infer # to view the inference as output
Note the above commands can also be run while the model is still being trained as long as there exists a training checkpoint. See inference.py for more details.
Intermediate
Having gone through the most basic seq2seq2 model, let's get more advanced! To bulild state-of-the-art neural machine translation systems, we will need more "secret sauce": the attention mechanism, which was first introduced by Bahdanau et al., 2015, then later refined by Luong et al., 2015 and others. The key idea of the attention mechanism is to establish direct short-cut connections between the target and the source by paying "attention" to relevant source content as we translate. A nice byproduct of the attention mechanism is an easy-to -visualize alignment matrix between the source and target sentences (Figure 4.).

Figure 4. Attention visualization - example of the alignments between source and target sentences. Image is taken from Bahdanau et al., 2015.
Remembering that in the vanilla seq2seq2 model, we pass the last source state from the encoder to the decoder when starting the decoding process. This works well for short and medium-length sentences; however, for long sentences, the single fixed-sized hidden state becomes an information bottleneck. In stead of discarding all of the hidden states computed in the source RNN, the attention mechanism provides an approach that allows the decoder to peek at them (treating them as a dynamic memory of the source information). By doing so, the attention mechanism improves the translation of longer sentences. Nowadays, attention mechanisms are the defacto standard and have been successfully applied to many other tasks (including image caption generation, speech recognition, and text summarization).