Attention-based Model
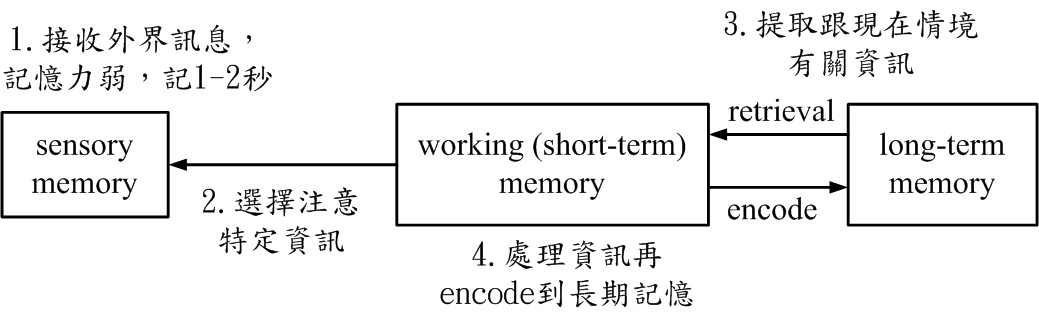 圖一、人類記憶機制示意圖。
圖一、人類記憶機制示意圖。
圖一顯示人類記憶機制示意圖。
人類記憶分三種,sensory memory(感知記憶), working memory(工作記憶), long-term memory(長期記憶)。當外界有訊號進來時,會先經過sensory memory 做簡單處理,它的記憶力弱,只能記一兩秒。
在人做推論或感知最重要的記憶體是working memory,也稱做short-term memory(短期記憶),而目前心理學界較常稱working memory。working memory做的事情是,選擇要注意sensory memory的什麼地方。
比方你面對講台,你的視線選擇注意在投影幕,而不是其它地方。
working memory 能從長期記憶提取出它需要的、跟現在情境有關的資訊,比如你要了解我現在說的話,你要回憶我們之前上課的內容。
working memory處理過這些資訊後,再encode到長期記憶裡面,那你就把今天學到的內容永遠記下來。
Attention-based model是模擬人類working memory的功用。
Attention-based model可分為兩大類,第一類是working memory和sensory memory溝通的部份;第二類是working memory 和 long-term memory溝通的部份。
圖一、第一類Attention-based model。
圖一顯示第一類Attention-based model。Attention-based model(注意力模型)是2014年底蓬勃發展的想法。
第一類的好處是說,假設輸入是一個很長的序列,比如你翻譯時,輸入是一個句子;或是輸入是一張影像;
若輸入是一個資訊量多的東西,你可能很難把所有資訊量一次處理好,那attention-based model 可以一次只注意input object的某個部份。
例如一句很長的句子,我可以每次只注意在某個子句或某個片語上面,這樣一小部份一小部份的考慮,機器可能可以把最後的翻譯做得比較好。
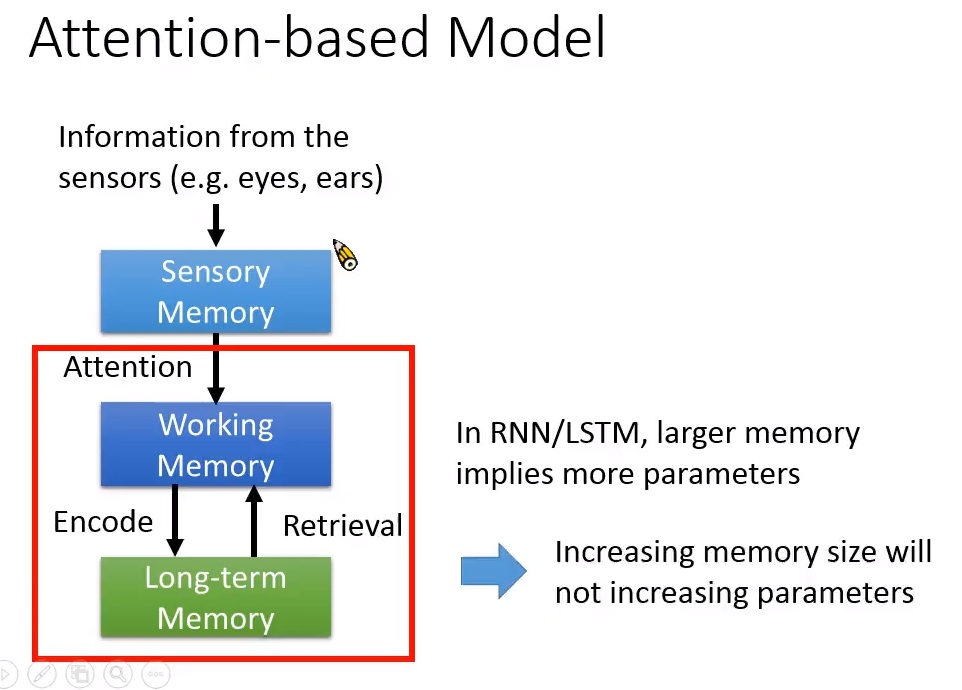
圖二、第二類Attention-based model。
圖二顯示第二類Attention-based model: 模擬working memory 與 long-term memory的溝通。
RNN/LSTM的memory的問題是memory沒有辦法太大,因為memory越大,參數就越多。
RNN裡面,memory到memory之間有一個transition weight。
若memory size 是 k,那就需一個k-by-k的矩陣。參數越多,它可能越容易overfitting。
第二類Attention-based model相較於RNN/LSTM的好處之一是memory增加時,模型參數並不會增加。
Machine Translation
![]()
圖三、seq-to-seq learning應用於翻譯。翻譯場景下,輸入長度與輸出長度不一定一樣。
圖三顯示seq-to-seq learning應用於翻譯。seq-to-seq learning可用來做machine translation (機器翻譯)。一般RNN可處理的問題是輸入序列長度與輸出序列長度一樣的case。實際上,它能處理輸入與輸出長度不一樣的case。
翻譯時就需要處理輸入與輸出長度不一樣的case。例如把機器學習翻成machine learning。翻譯時不知道翻出來的長度比輸入長度長還是短,此時需要seq-to-seq model。
首先學一個RNN/LSTM encoder把input character seq依序丟進RNN裡面。最後一個time step 的hidden layer包含整個句子的資訊。再來做翻譯,把hidden layer output作為另一個rnn decoder的input。
此decoder在每個time step的input為encoder的hidden layer output以及上一個time step的decoder output。
它第一個decode出來的字為machine,再輸出下一個字為learning,最後再輸出一個終止的符號,表示產生output sequence 的process結束。上述seq-to-seq learning沒有達到state of the art 的結果。但hidden layer output的這個vector真的能代表整個輸入的sequence嗎?
那麼就用attention-based model來改善。加入attention-based model 之後,seq-to-seq learning就真的可以得到state of the art的結果了。
![]() 圖四、Attention-based model for machine translation。
圖四、Attention-based model for machine translation。
圖四顯示Attention-based model for machine translation。首先也是有一個encode RNN,但不期待最後time step 的hidden layer output vector能代表整個sentence的information。
代表input每個character的vector。 再來,initialize一個vector ,它是RNN initial 的memory。接下來有一個match 的function,它的輸入是以及某一個hidden layer output比如說。
output一個scalar,記為 。此match function有不同的做法,最簡單的做法是兩向量與的cosine similarity,也就是向量內積。match也可以是一個小的NN, input是與的串接,output是一個scalar。
或是也可以做這樣的操作: 。在第二、三個case裡的參數如何訓練?在此先不多談。
![]()
圖五、計算示意圖。
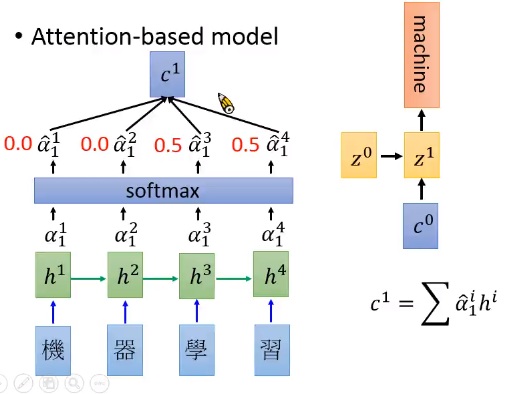
圖五顯示計算示意圖。用match function可以得出 -再經過softmax得到match scores -,其和是1。
再來把 到 作為weight乘上 再加起來得到vector ,亦即
舉例來說,若,則。這個例子表示機器注意在前兩個字而忽視後兩個字。
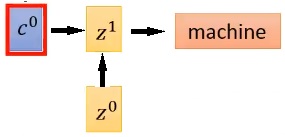
圖六、作為RNN decoder的input並得出翻譯"machine"之示意圖。
圖六為作為RNN decoder的input並得出翻譯"machine"之示意圖。把 作為RNN decoder的input, 是decoder的initial memory,因此第一個時間點的hidden layer output為
表示注意力在"機"跟"器"兩個字,希望decoder知道是這兩字的向量和,那麼經過翻譯得到"machine"。
那麼match function如何訓練?
我們知道第一個時間點的output word應該是machine。
做backpropagation後,會調decoder的權重,也會調的值,因此,會調match scores -。
而match scores是來自與的交互作用結果,因此會回調match function裡面的參數再回調與。
這個模型是有點複雜的,自己編碼backpropagation會有點難算,但tensorflow是支援gradient這件事情,因此,把feed forward兜起來,backward的地方就交給程式處理就好。
圖七、以計算之示意圖。
圖七顯示以計算之示意圖。用 算match scores -,再得到
此時,match scores可能為, ,表示注意力在"學習"兩個字。接著,再進入RNN decoder得到以及翻譯結果"learning"。

圖八、輸入至RNN decoder並得翻譯結果"learning"之示意圖。
圖八顯示輸入至RNN decoder並得翻譯結果"learning"之示意圖。接下來,RNN encoder再以為memory算出,直至終止的符號"======"出現。
![]()
圖九、以注意力模型實現機器翻譯之簡略流程圖。
圖九顯示以注意力模型實現機器翻譯之簡略流程圖。
Reading Comprehension
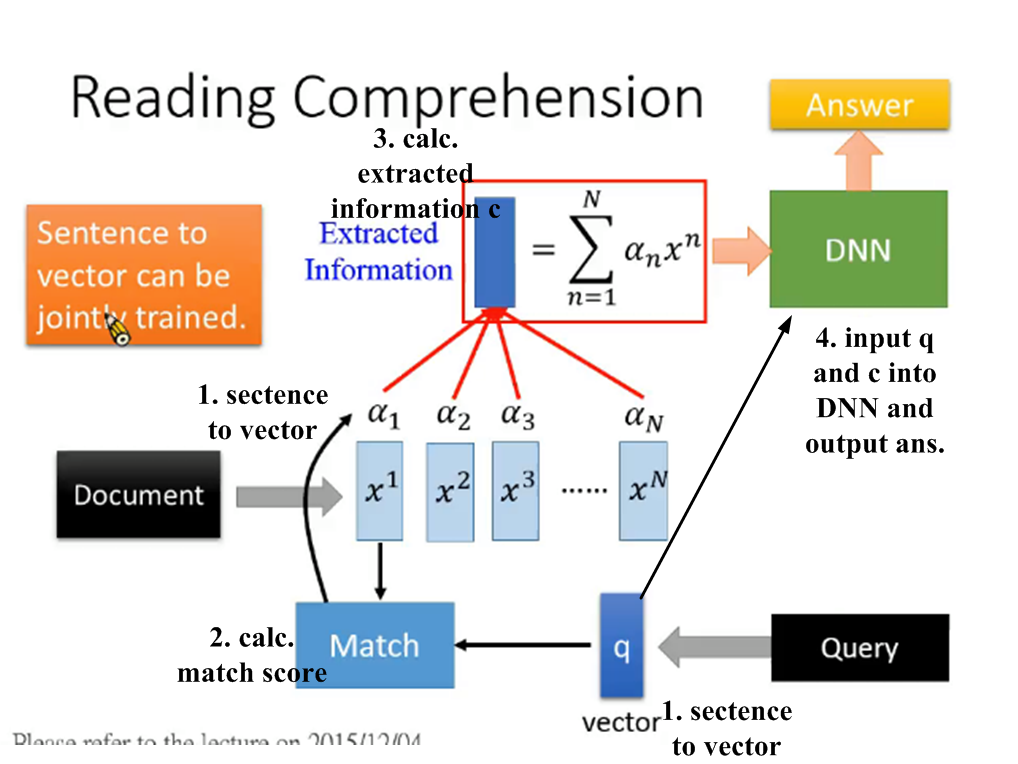
圖十、注意力模型應用於閱讀理解(reading comprehension)之示意圖。
圖十顯示注意力模型應用於閱讀理解(reading comprehension)之示意圖。給機器看一段文章,問它一個問題,希望輸出一個正確答案。1. 先把文章中的每個句子用向量表示。問機器的問題也用向量表示。表示成向量的方法很多,例如,一個句子變成一個bag of word丟到DNN裡面去,輸出就是一個低維度可代表這個句子的feature vector。2. 根據這個問題對這些句子向量做attention。把問題向量與句子向量輸入至match function,輸出該句子向量 所對應的match score ,共得到N個匹配分數-。3. 把這些句子向量乘以匹配分數做weighted sum,得到extracted information ,
是機器根據query從各句子向量抽取出的要回答query的相關資訊。接下來把query與向量輸入至DNN,希望它輸出正確答案。同樣架構也可以應用到visual QA problem,就是把輸入改成一張影像,抽取出影像向量。其中,文字轉向量的過程也可以跟這個注意力模型一起訓練。訓練時,要有query-answer pair,知道正確答案,並一路backpropagation回來,訓練DNN,再訓練,再訓練match function,再訓練句子轉向量的網路參數。
Memory Network
 圖十一、運用記憶網路(Memory network)做閱讀問答之架構示意圖。
圖十一、運用記憶網路(Memory network)做閱讀問答之架構示意圖。
圖十一顯示運用記憶網路(Memory network)做閱讀問答之架構示意圖。 運作步驟如下:1. 記憶網路用兩組不同參數的DNN ( DNN_1_及 DNN_2,此兩組DNN是聯合訓練)來做句子轉向量,輸入文章內的同一個句子會轉成兩種向量,做attention的向量與抽information的向量。2. 用算match scores。3. 將match scores與DNN_1得出的句子向量做weighted sum得出document中與query相關的資訊。4. 做n次hopping,為預先設定好。hopping作法是將extracted information與query vector相加 (也有其它更複雜的作法),得出新的extracted information。5. 將extracted information輸入至DNN,得出答案。
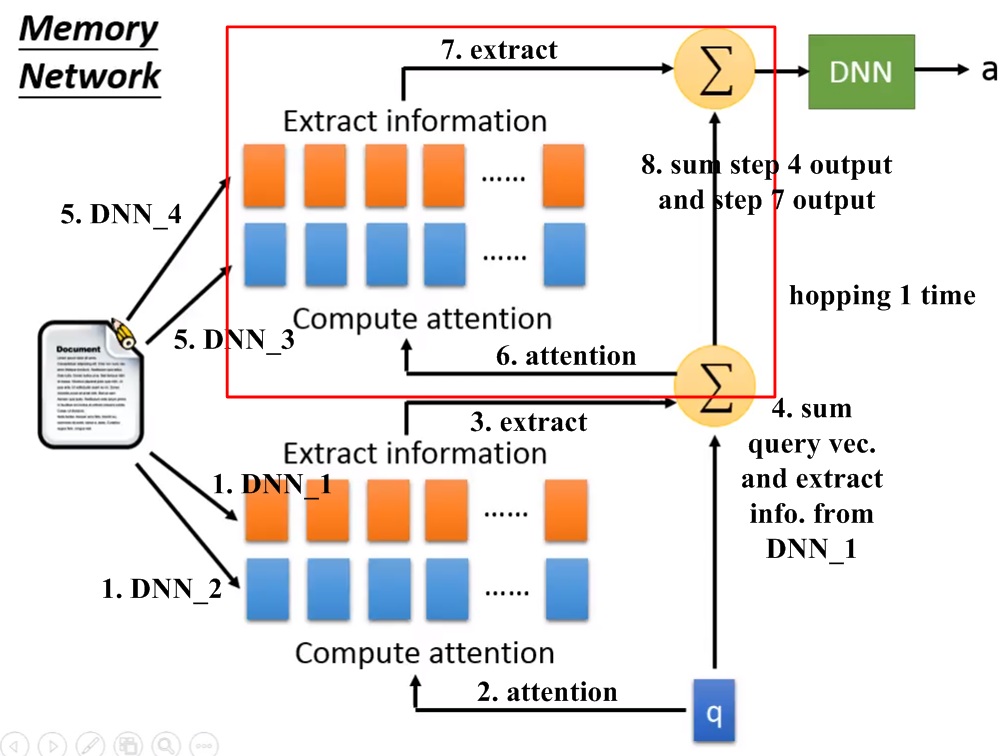 圖十二、運作一次hopping的記憶網路架構示意圖。
圖十二、運作一次hopping的記憶網路架構示意圖。
圖十二顯示運作一次hopping的記憶網路架構示意圖。步驟如下:1. 兩組DNN ( DNN-1及 DNN-2)得出算match scores用的向量以及抽訊息用的向量。2. 計算match scores:注意力移到與query相關的訊息上。3. 由DNN-1得出extracted information。4. 將query vector與來自DNN-1的extracted information相加。5. 以另兩組DNN(DNN-3及DNN-4)得出算match scores用的向量以及抽訊息用的向量。6. 以步驟4的結果與DNN-3的輸出向量計算match scores。7. 以DNN-4的輸出向量計算extracted information。8. 將步驟4的結果與步驟7的結果相加後輸入DNN得出答案。紅色框框為一次hopping。每次hopping的DNN不同。計算一次hopping用4組DNN,計算兩次hopping用6組DNN。
 圖十三、記憶網路運用hopping推論出問題答案之示意圖。
圖十三、記憶網路運用hopping推論出問題答案之示意圖。
圖十三顯示記憶網路運用hopping推論出問題答案之示意圖。這個例子展示hopping的好處;它是做在babi corpus上[2]。它給機器讀的文件是按照某個pattern產生,裡面的句子是非常簡單的。問機器一個問題:"what color is Greg?"希望得出正確答案:"yellow"。記憶網路做了三次hopping。步驟如下:0. 輸入問題"what color is Greg?"。1. hop 1時,由問題中的"Greg",注意到"Greg is a frog"。2. hop 2 時,由hop 1的"frog",注意到"Brian is a frog"。3. hop 3時,由hop 2的"Brian"注意到"Brian is yellow"。4. 得出正確答案"yellow"。
Neural Turing Machine
Neural Turing Machine是RNN/LSTM加上一組external memory,它模擬人類的working memory與long-term memory之間的互動(如圖二)。Neural Turing Machine的架構與計算機的范紐曼架構是很類似的。
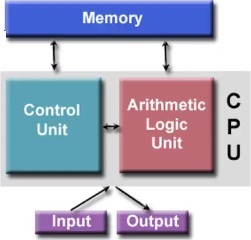
圖十四、計算機的范紐曼架構示意圖。
圖十四顯示計算機的范紐曼架構示意圖。此架構包含CPU以及external memory,CPU中分成control unit與 arithmetic logic unit (ALU)兩部份。input進來時,會視需求對external memory有所存取,process後,最後output結果。
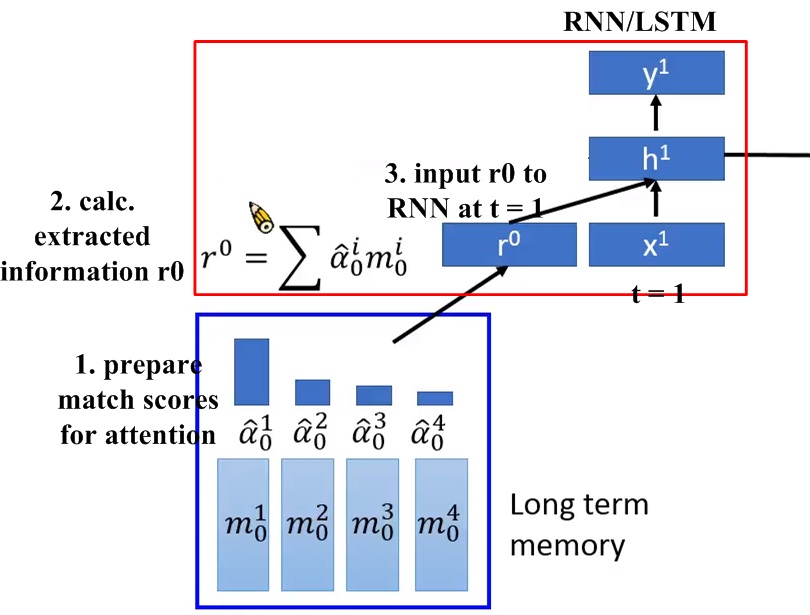
圖十五、Retrieval process from long-term memory in neural Turing machine,
圖十五顯示Retrieval process from long-term memory in neural Turing machine。Neural Turing Machine除了原本RNN/LSTM的內部memory,還有一組external memory,它是一個memory block,可以想成是人的long-term memory,圖中的block寬度為4,表示由4個向量組成-。process時,RNN可以request long-term memory裡的資料以得到更好結果。此long-term memory伴隨一組match scores (attention係數) -,進行retrieval process。1. 產生一組match scores。2. 提取資訊為。3. 將其作為RNN在time step 的input,與一同輸入至hidden layer。
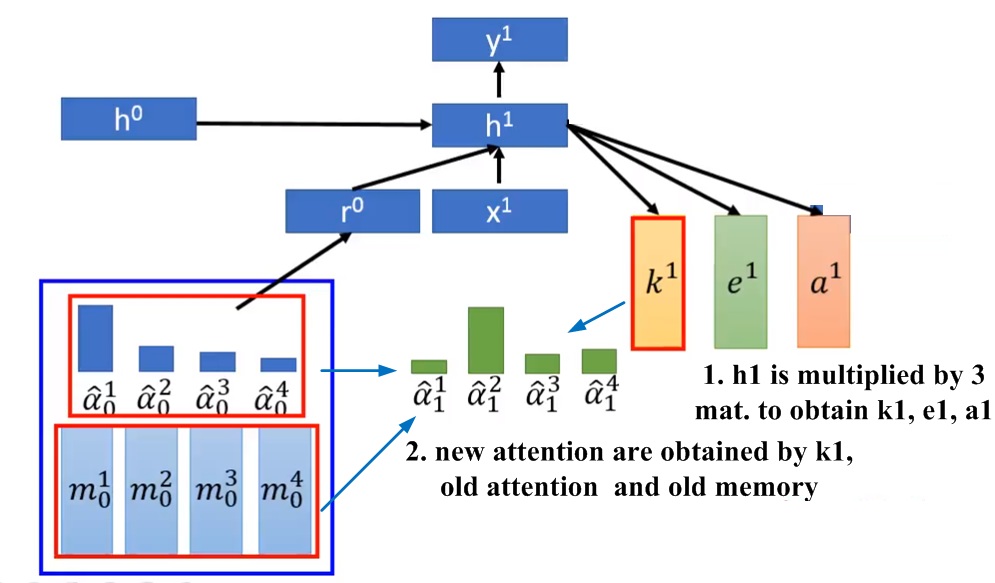 圖十六、更新attention係數之示意圖。
圖十六、更新attention係數之示意圖。
圖十六顯示更新attention係數之示意圖。會乘上三個不同矩陣,得到三個不同向量, , ,此三個向量的維度跟memory裡面的向量是一樣的。根據、這個時間點的attention(-)以及memory(-)產生下個時間點的attentionn(-):
上式為產生attention的一個簡化版本。原論文中,是丟入一個NN而得出。上式的會再經過softmax得出下個時間點的attentionn(-)。
由新的attention(-)來更新memory
[0]
http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/Lecture/Attain (v3).ecm.mp4/index.html
[1]
End-to-end memory Networks. S. Sukhbaatar, A. Szlam, J. Weston, R. Fergus. NIPS, 2015.
[2]
Example of attention-based model by Keras from babi corpus:
https://github.com/fchollet/keras/blob/master/examples/babi_memnn.py