Silence Removal and Event Detection
Function silenceRemoval() in audioSegmentation.py takes an audio recording as input and return segments endpoints corresponding to individual audio events. All "silent" areas of the signal are removed.
Function silenceRemoval() use a semi-supervised approach
- an SVM model is trained to distinguish between high-energy and low-energy short-term frames. 10% of the highest energy frames along with 10% of the lowest ones are used in training.
- the SVM model with a probabilistic output is applied on whole recording and a dynamic thresholding is used to detect the active segments
Usage example
from pyAudioAnalysis import audioBasicIO as aIO
from pyAudioAnalysis import audioSegmentation as aS
[Fs, x] = aIO.readAudioFile("data/recording1.wav")
segments = aS.silenceRemoval(x, Fs, 0.020, 0.020, smoothWindow = 1.0, Weight = 0.3, plot = True)
segments is a list of segments endpoints.
Each endpoint has two elements, segment beginning and segment ending (in seconds).
Command-Line Usage Example
指令1 python audioAnalysis.py silenceRemoval -i data/recording3.wav --smoothing 1.0 --weight 0.3
指令2 python audioAnalysis.py classifyFolder -i data/recording3_ --model svm --classifier data/svmSM --detail
指令1 把data/recording3.wav裁減出很多以data/recording3_開頭的segment檔。
指令2 把data/recording3_的segment檔用事先訓練好的data/svmSM svm model是屬於speech或music。
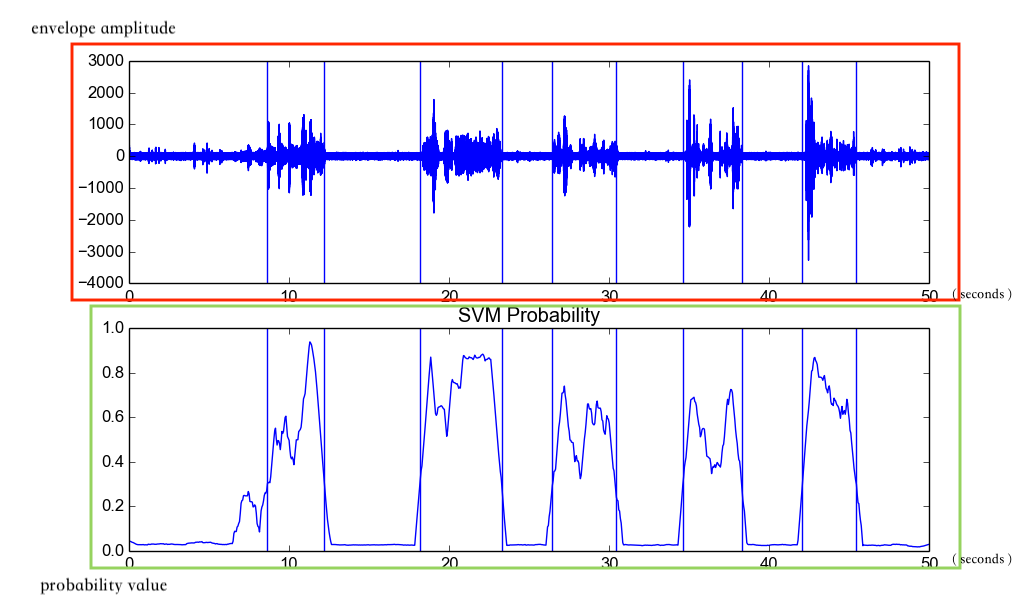 Figure 2
Figure 2 silenceRemoval() result on data/recording3.wav
Figure 2 呈現函數silenceRemoval()處理音頻data/recording3.wav的結果。
Figure 2(紅)顯示音頻data/recording3.wav的波形圖。垂直線是segment的邊界(boundary),在第一條跟第二條垂直線中間是第一個active segment,第三條跟第四條垂直線中間是第二個active segment。
以此類推,在第跟第垂直線中間是第個active segment。其他非active segment就是silence segment。
Figure 2(橙)顯示音頻data/recording3.wav是active segment的機率圖。橫軸是時間軸,單位是秒;縱軸是機率值。垂直線跟Figure 2(紅)一樣是segment的邊界。
In rather sparse recordings (i.e. the silent periods are quite long), longer smoothing window and a looser probability threshold are used.
In continuous recording, a shorter smooth window and a stricter probability threshold are used.
continuos recording example
python audioAnalysis.py silenceRemoval -i data/count2.wav --smoothing 0.1 --weight 0.6