QA Neural Network Models
Among numerous models proposed for multiple QA (Trischler et al., 2016; Fang et al., 2016; Tseng et al., 2016), we adopt the End-to-End Memory Network (MemN2N) (Sukhbaatar et al., 2015) and Query-Based Attention CNN (QACNN) (Liu et al., 2017), both open-sourced, to conduct the experiments. Below we briefly introduce the two models in Section 4.1 and Section 4.2 respectively. For the detail of the models, please refer to the original papers.
End-to-End Memory Networks
A n End-to-End Memory Network (MemN2N) first transforms into a vector representation with an embedding layer . At the same time, all sentences in are also transformed into two different sentence representations with two additional embedding layer and . The first sentence representation is used in conjunction with the question representation to produce an attention-like mechanism that outputs the similarity between each sentence in and . The similarity is then used to weight the second sentence representation. We then obtain the sum of question representation and the weighted sentence representations over as . In original MemN2N, is decoded to provide the estimation of the probability of being an answer for each word within a fixed set. The word with the highest probability is then selected as the answer. However, in multiple-choice QA, is in the form of open, natural language sentences instead of a single word. **Hence we modify MemN2N by adding an embedding layer to encode as a vector representation by averaging the embeddings of words in . We then compute the similarity between each choice representation and . The choice C with highest probability is then selected as the answer.
Query-Based Attention CNN
A Query-based Attention CNN (QACNN) first uses an embedding layer to transform , , and into a word embedding. Then a compare layer generates a story-question similarity map and a story-choice similarity map . The two similarity maps are then passed into a two-stage CNN architecture, where a question-based attention mechanism on the basis of is applied to each of the two stages. The first stage CNN generates a word-level attention map for each sentence in , which is then fed into second stage CNN to generate a sentence-level attention map, and yield choice-answer features for each of the choices. Finally, a classifier that consists of two fully-connected layers collects the information form every choice answer feature and outputs the most likely answer. The trainable parameters are the embedding layer , the two-stage CNN and that integrate information form the word to the sentence level, and from the sentence to story level, and the two fully-connected layers and that make the final prediction. In Section 5, we will conduct experiments to analyze the transferability of the QACNN by fine-tuning some parameters while keeping others fixed. Since QACNN is a newly proposed QA model has a relatively complex structure, We illustrate its architecture in Figure 1, which is enough for understanding the rest of the paper. Please refer to the original paper (Liu et al., 2017) for more details.
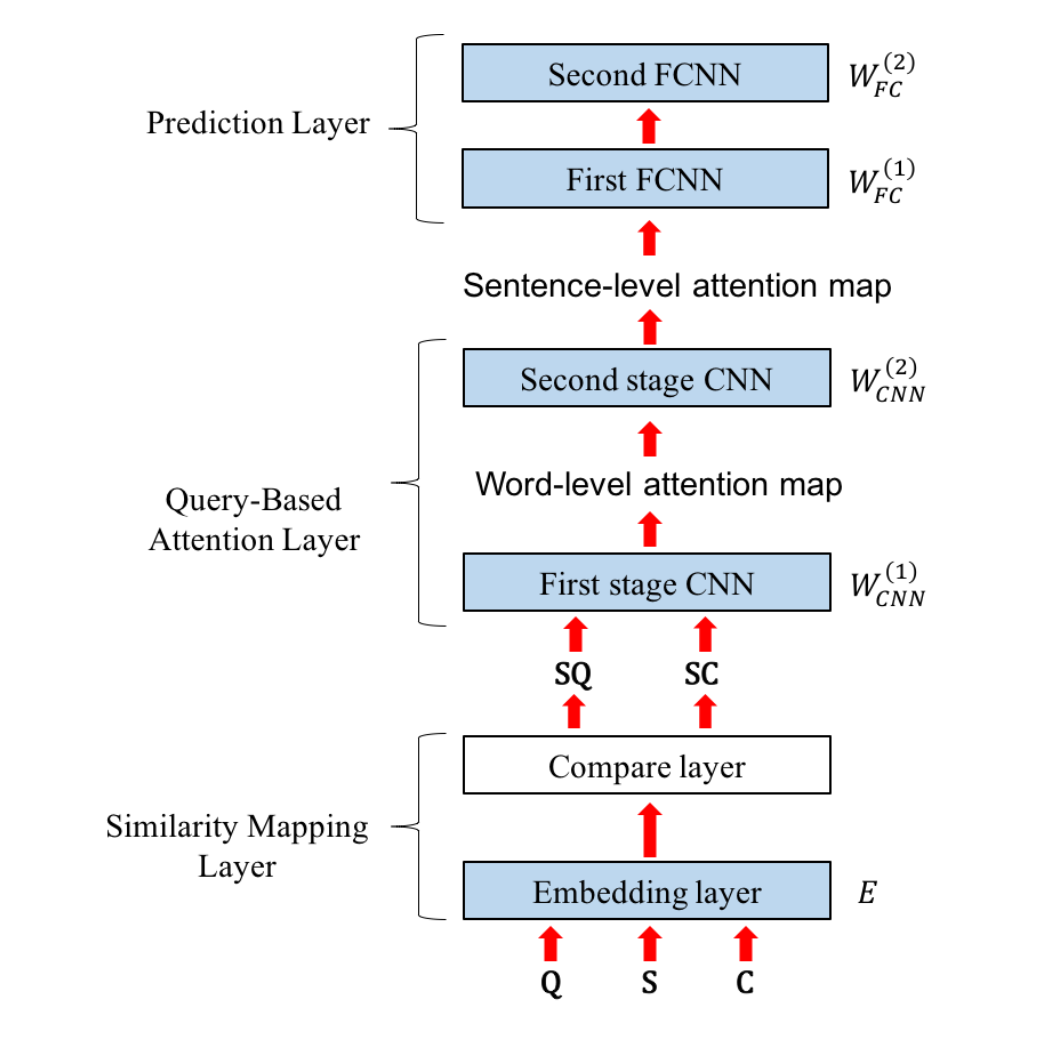 Figure 1: QACNN architecture overview. The trainable parameters, including , , , , and , are colored in light blue.
Figure 1: QACNN architecture overview. The trainable parameters, including , , , , and , are colored in light blue.