1 TextSource = namedtuple('TextSource', 'plot dvs subtitle script')
2
3 # TODO: add characters info
4 MovieInfo = namedtuple('Movie', 'name year genre text video')
5
6 QAInfo = namedtuple('QAInfo',
7 'qid question answers correct_index imdb_key video_clips')
8
9 ...
10
11 # region Initialize and Load class data
12 def _populate_movie(self):
13 """Create a map of (imdb_key, MovieInfo) and its inversed map.
14 """
15 with open(cfg.MOVIES_JSON, 'r') as f:
16 movies_json = json.load(f)
17
18 for movie in movies_json:
19 t = movie['text']
20 ts = TextSource(t['plot'], t['dvs'], t['subtitle'], t['script'])
21 vs = None
22 self.movies_map[movie['imdb_key']] = MovieInfo(
23 movie['name'], movie['year'], movie['genre'], ts, vs)
24
25 self.movies_map_inv = {(v.name + ' ' + v.year):k
26 for k, v in self.movies_map.iteritems()}
27
28 def _populate_qa(self):
29 """Create a list of QaInfo for all question and answers.
30 """
31 with open(cfg.QA_JSON, 'r') as f:
32 qa_json = json.load(f)
33
34 for qa in qa_json:
35 self.qa_list.append(
36 QAInfo(qa['qid'], qa['question'], qa['answers'], qa['correct_index'],
37 qa['imdb_key'], qa['video_clips']))
38
39 def _populate_splits(self):
40 """Get the list of movies in each split.
41 """
42 with open(cfg.SPLIT_JSON, 'r') as f:
43 self.data_split = json.load(f)
44
45 # endregion
namedtuple()
在python中,傳統的tuple只能通過下標(index)來訪問各個元素,namedtuple[1] 能夠創建類似於tuple,通過namedtuple,每個元素有自己的名字,這樣數據的意義就可以一目了然。
% tuple
data = (1, 'Justin', 93)
data[0]
Friend=namedtuple("Friend",['name','age','email'])
f1=Friend('xiaowang',33,'xiaowang@163.com')
print(f1.age)
name,age,email=f1
print(name,age,email)
行1建立TextSource的namedtuple,裡面元素名稱有'plot', 'dvs', 'subtitle', 'script'。
行4建立MovieInfo的namedtuple,裡面元素名稱有'name', 'year', 'genre', 'text', 'video'。
行6建立QAInfo的namedtuple,裡面元素名稱有'qid', 'question', 'answers', 'correct_index', 'imdb_key', 'video_clips'。
def _populate_movie(self):
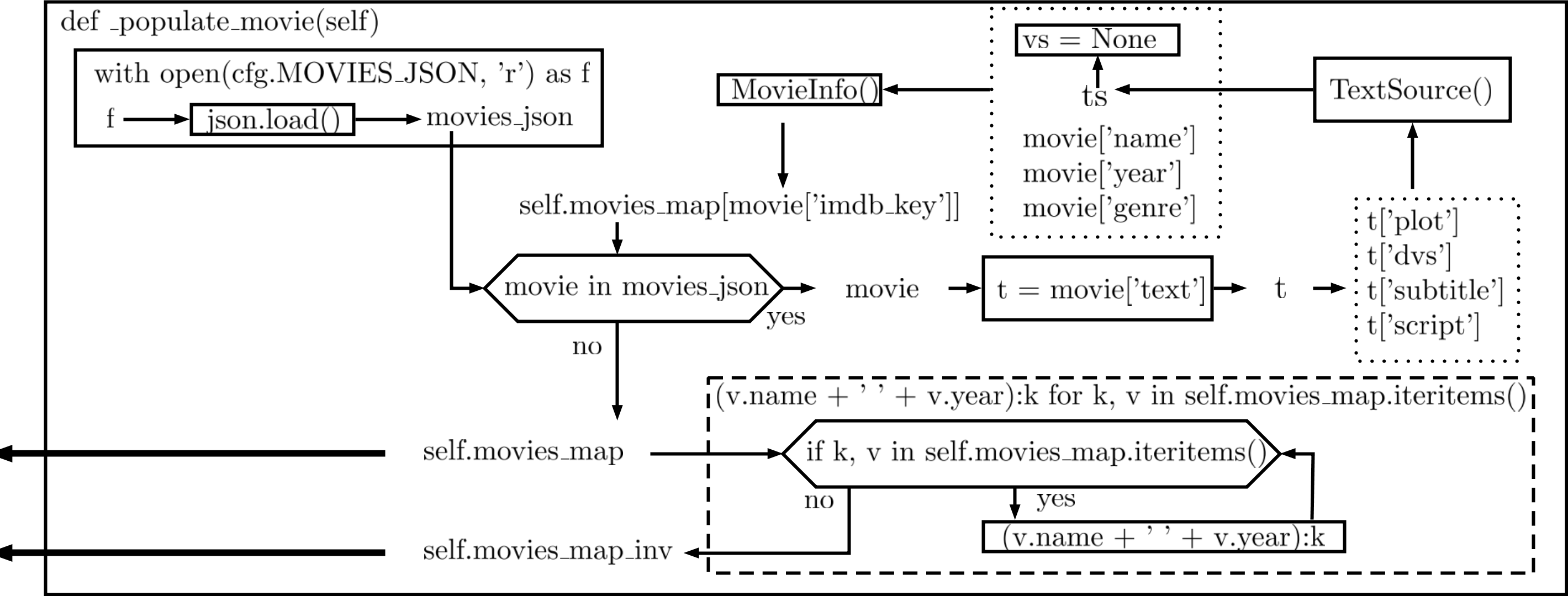 Figure 1: Flowchart of helper function
Figure 1: Flowchart of helper function _populate_movie
如Figure 1所示,_populate_movie function首先open cfg.MOVIES_JSON所指向的json file,並且開啟的檔案用f來表示。
f丟入json.load()把檔案的內容放入movies_json變數。
for loop 逐次讀取movies_json裡面單個movie的資料,先取出movie['text']裡面的內容,再把t['plot'], t['dvs'], t['subtitle'], t['script']細分出來,透過TextSource(),變成一個namedtuple變數ts,從t到ts應該就是把原本json的format轉變成python的namedtuple。
最後透過MovieInfo(),把vs, ts, movie['name'], movie['year'], movie['genre'],變成一個namedtuple放入self.movies\_map[movie['imdb\_key']],movies_map是個dictionary of namedtuple MovieInfo Object。
def _populate_qa(self):
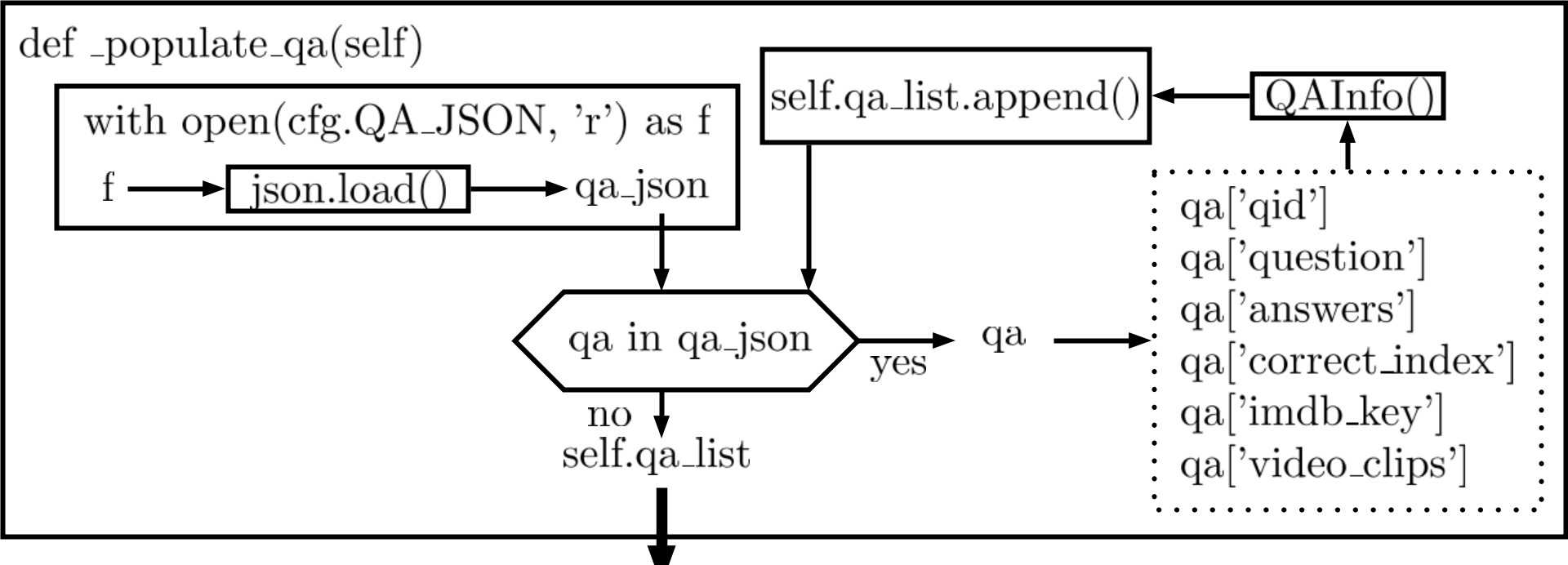 Figure 2: Flowchart of helper function
Figure 2: Flowchart of helper function _populate_qa
如Figure 2所示,_populate_qa()function首先opencfg.QA_JSON所指向的json file,開啟之後用f來表示。
f丟入json.load()把檔案的內容放入qa_json變數。
for loop逐次讀取qa_json裡面單個qa的資料,在把qa['qid'], qa['question'], qa['answers'], qa['correct_index'], qa['imdb_key'], qa['video_clips']細分出來,透過QAInfo()產生一個namedtuple變數,把它append到self.qa_list,self.qa_list是一個list of namedtuple QAInfo Object。
def _populate_splits(self):
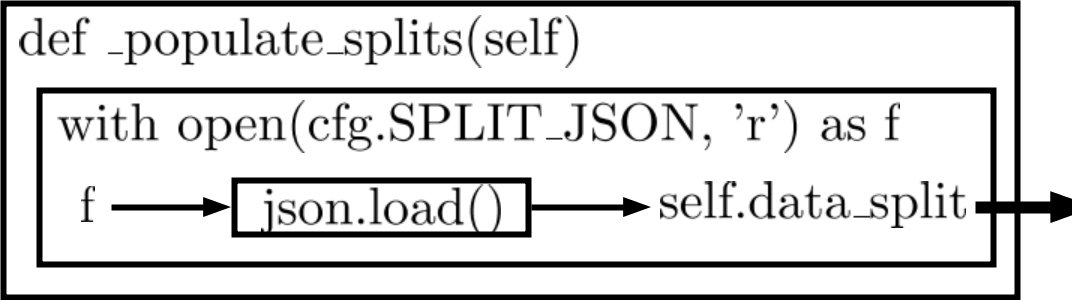 Figure 3: Flowchart of helper function
Figure 3: Flowchart of helper function _populate_splits
如Figure 3所示,_populate_splits() function open cfg.SPLIT_JSON所指向的json file,開啟之後用f來表示。
f丟入json.load()把檔案內容放入self.data_split裡面,self.data_split是一個dictionary。