Approach 1: Post-Transcription Keyword based Segmentation
 Figure 1 Flowchart of Approach 1
Figure 1 Flowchart of Approach 1
如Figure 1所示,原始的音頻通過一個人聲頻率的band-pass filter後,使用google cloud speech-to-text service把整段選項(choice)的音頻轉換成文字後,用"1","2","3","4"關鍵字(keyword)在整段文字中檢索,根據"1","2","3","4"時間上的位置(timestamp),把選項1,2,3,4的音頻分開產生choice 1 Audio、choice 2 Audio、choice 3 Audio、choice 4 Audio。最後把這些分割好的音頻再一次丟入`google cloud speech-to-text service 裡面,輸出更精確的結果。
Code Implementation
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 9 06:02:41 2018
@author: petertsai
"""
import io
import os
import glob
import re
import numpy as np
import pandas as pd
import argparse
from openpyxl import load_workbook
import sys
def get_platform():
platforms = {
'linux1' : 'Linux',
'linux2' : 'Linux',
'darwin' : 'OS X',
'win32' : 'Windows'
}
if sys.platform not in platforms:
return sys.platform
return platforms[sys.platform]
def transcribe_file_with_word_time_offsets(speech_file, timestamp_writer, language_code='cmn-Hant-TW', beta=False, alternative_language= None):
"""Transcribe the given audio file synchronously and output the word time
offsets."""
if beta:
from google.cloud import speech_v1p1beta1 as speech
from google.cloud.speech_v1p1beta1 import enums
from google.cloud.speech_v1p1beta1 import types
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code='cmn-Hant-TW',
#alternative_language_codes=['en-US'],
alternative_language_codes = alternative_language,
enable_word_time_offsets=True,
speech_contexts=[types.SpeechContext(
phrases=['四', '三', '二', '一'],
)],
enable_word_confidence=True
)
else:
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code=language_code,
enable_word_time_offsets=True,
speech_contexts=[types.SpeechContext(
phrases=['四', '三', '二', '一'],
)],
#enable_word_confidence=True
)
client = speech.SpeechClient()
with io.open(speech_file, 'rb') as audio_file:
content = audio_file.read()
audio = types.RecognitionAudio(content=content)
response = client.recognize(config, audio)
if get_platform == 'Windows':
m = re.match(r'(.+)\\(.+)', speech_file)
else:
m = re.match(r'(.+)/(.+)', speech_file)
filename = m.group(2)
n = re.match(r'C(.+)\.wav', filename)
audio_index = n.group(1)
results = []
for i, result in enumerate(response.results):
alternative = result.alternatives[0]
print(u'Transcript {}_{}: {}'.format(audio_index, i+1, alternative.transcript))
results.append(alternative.transcript)
word_index = []
start_time_column = []
end_time_column = []
confidences_list = []
for word_info in alternative.words:
word = word_info.word
start_time = word_info.start_time
end_time = word_info.end_time
word_index.append(word)
start_time_column.append(start_time.seconds + start_time.nanos * 1e-9)
end_time_column.append(end_time.seconds + end_time.nanos * 1e-9)
if hasattr(word_info, 'confidence'):
confidences_list.append(word_info.confidence)
else:
confidences_list.append(float('nan'))
df = pd.DataFrame({'start_time':start_time_column, 'end_time':end_time_column, 'confidence':confidences_list}, index=word_index)
#print(df)
df.index.name = 'word'
df.to_excel(timestamp_writer,'{}_{}'.format(filename, i+1))
return results
def batch_transcribe_speechFile(speechFileQueue,existSpeechFileList,choices_list,timestamp_writer,beta=True):
print('speech files in Queue:')
print(speechFileQueue)
for i, speechFile in enumerate(speechFileQueue):
choices = transcribe_file_with_word_time_offsets(speechFile, timestamp_writer, beta=beta)
choices_list.append(choices)
existSpeechFileList.append(speechFile)
df = pd.DataFrame({'filename':existSpeechFileList, 'sentence':choices_list})
df = df.sort_values(by=['filename'])
df.to_csv(output_csv_filename)
timestamp_writer.save()
if __name__ == '__main__':
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="GC-AI-Challenge-4dc21e90cad0.json"
parser = argparse.ArgumentParser(
description=__doc__,
formatter_class=argparse.RawDescriptionHelpFormatter)
parser.add_argument('--beta', dest='beta', action='store_true')
parser.add_argument('--no-beta', dest='beta', action='store_false')
parser.add_argument('--reset', dest='reset', action='store_true')
parser.add_argument('--no-reset', dest='reset', action='store_false')
parser.add_argument('--batch_idx', dest='batch_idx', help='[1-60]')
parser.add_argument('--batch_size', dest='batch_idx', help='default 25')
parser.add_argument('--input_dir', dest='input_dir', help='input wav folder')
parser.set_defaults(beta=True, reset=False, batch_idx='0', batch_size=25, input_dir='choices(small)')
args = parser.parse_args()
beta = args.beta
reset = args.reset
batch_size = args.batch_size
string_batch_range = args.batch_idx
input_dir = args.input_dir
output_dir= 'result_'+ input_dir
if not os.path.isdir(output_dir):
os.makedirs(output_dir)
entireSpeechFileList = sorted(glob.glob(os.path.join(input_dir,'*.wav')))
#print('entire speech files in folder {}'.format(input_dir))
#print(entireSpeechFileList)
if re.search('-', string_batch_range):
rr = re.match(r'([0-9]*)-([0-9]*)', string_batch_range)
if rr.group(1):
begin_idx = int(rr.group(1)) - 1
else:
begin_idx = 0
if rr.group(2):
end_idx = int(rr.group(2))
else:
end_idx = int(np.ceil(len(entireSpeechFileList)/batch_size))
else:
rr = re.match(r'([0-9]*)', string_batch_range)
if int(rr.group(1)) != 0:
begin_idx = int(rr.group(1))
end_idx = int(rr.group(1)) + 1
else:
begin_idx = 0
end_idx = int(np.ceil(len(entireSpeechFileList)/batch_size))
print('beta:', beta)
if beta:
suffix = '_beta'
else:
suffix = ''
print('suffix:', suffix)
output_csv_filename = os.path.join(output_dir,'transcribe_output{}.csv'.format(suffix))
'''check result csv exist or not'''
if os.path.isfile(output_csv_filename) and not(reset):
df = pd.read_csv(output_csv_filename,index_col=0)
existSpeechFileList = df.filename.tolist()
choices_list = df.sentence.tolist()
else:
choices_list = []
existSpeechFileList = []
for b in range(begin_idx,end_idx):
timestamp_xls_filename = os.path.join(output_dir,'transcribe_timestamp{}_{:02d}.xlsx'.format(suffix,b+1))
timestamp_writer = pd.ExcelWriter(timestamp_xls_filename)
''' check batch xlsx status 1. complete task 2. proccessing yet finished 3. new '''
titles = []
if os.path.isfile(timestamp_xls_filename):
print('load {} ...'.format(timestamp_xls_filename))
book = load_workbook(timestamp_xls_filename)
for ws in book.worksheets:
mmm = re.match(r'(.+)\.wav_(.+)', ws.title)
titles.append(os.path.join(input_dir,mmm.group(1)+ '.wav'))
titles = sorted(list(set(titles)))
print('number of sheets: {}'.format(len(titles)))
if len(titles) == batch_size or b == end_idx-1:
continue
else:
book = load_workbook(timestamp_xls_filename)
timestamp_writer.book = book
timestamp_writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
speechFileQueue = sorted(list(set(entireSpeechFileList[b*batch_size:(b+1)*batch_size]) - set(titles)))
batch_transcribe_speechFile(speechFileQueue,existSpeechFileList,choices_list,timestamp_writer,beta=beta)
else:
print('create new {} !!!'.format(timestamp_xls_filename))
speechFileQueue = entireSpeechFileList[b*batch_size:(b+1)*batch_size]
batch_transcribe_speechFile(speechFileQueue,existSpeechFileList,choices_list,timestamp_writer,beta=beta)
Code Realization
C0000001.wav Transcript: 1.5公里21點4公里山1.3公里是1.6公里
正確答案:一 1.5公里 二 1.4公里 三 1.3公里 四 1.6公里
"一"被google api跟1.5的"1"合併在一起 "三"被google api弄成"山" (捲舌不捲舌) 拼音:san vs shan "四"被google api弄成"是" (捲舌不捲舌) 拼音:si vs shi
type
python transcribe_file_with_word_time_offsets.py --beta --batch_size 25 --batch_idx <batch range> --input_dir <input data folder>
 Figure 1 在命令列執行指令的螢幕輸出
Figure 1 在命令列執行指令的螢幕輸出
 Figure 2 transcription 結果的儲存檔
Figure 2 transcription 結果的儲存檔
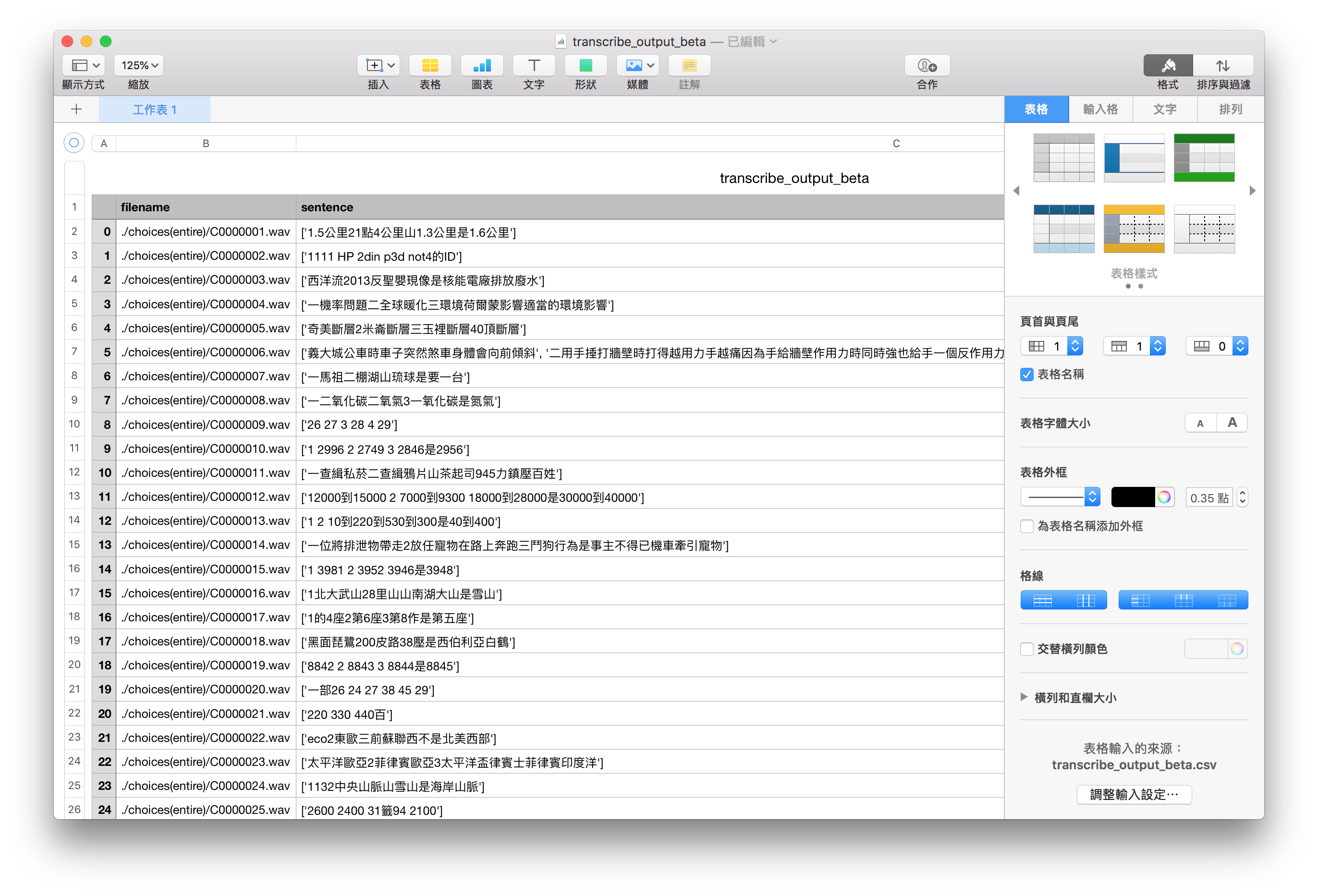 Figure 3
Figure 3 transcribe_output_beta.csv 裡面的內容格式
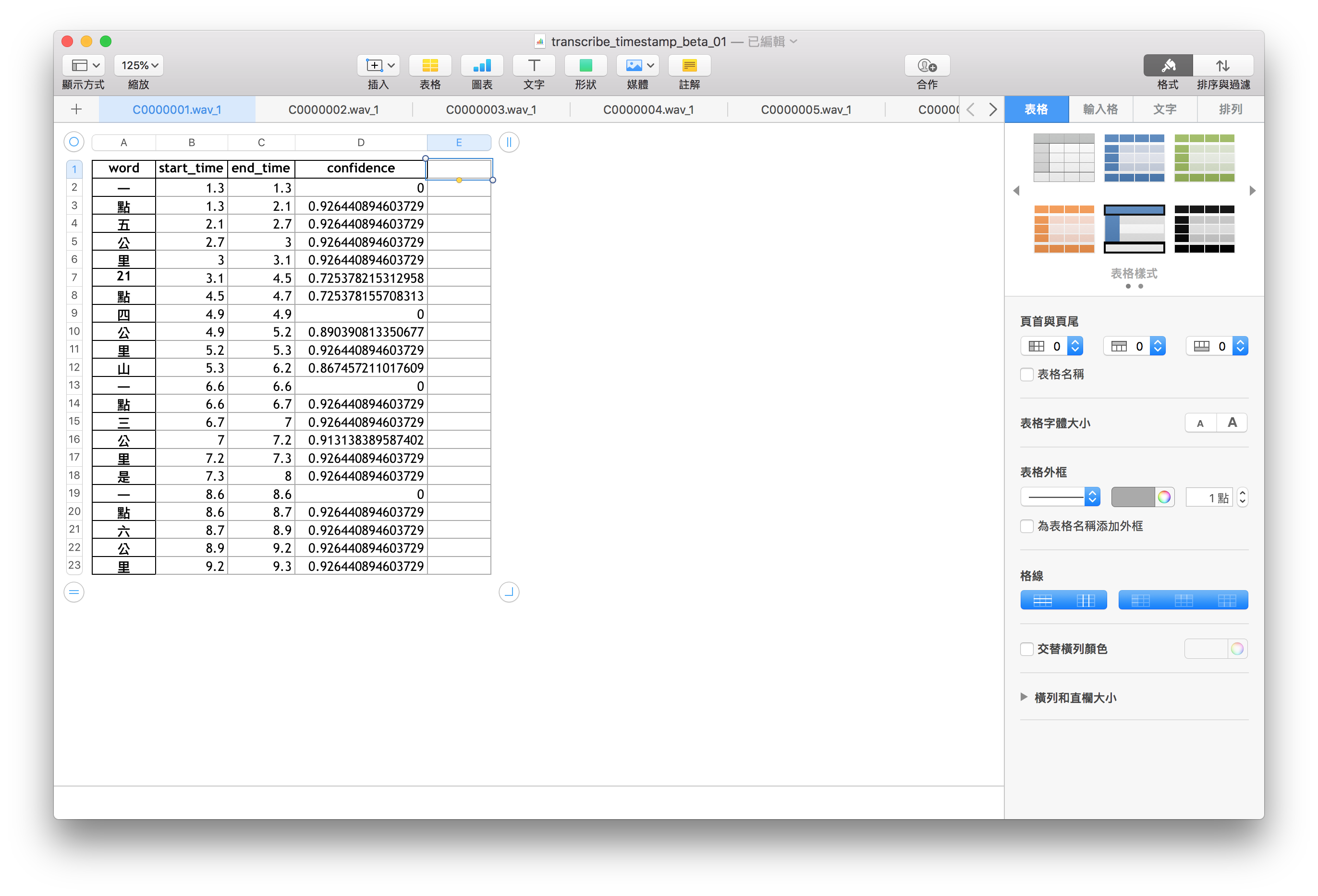 Figure 4
Figure 4 transcribe_timestamp_beta_01.xlsx裡面的內容格式
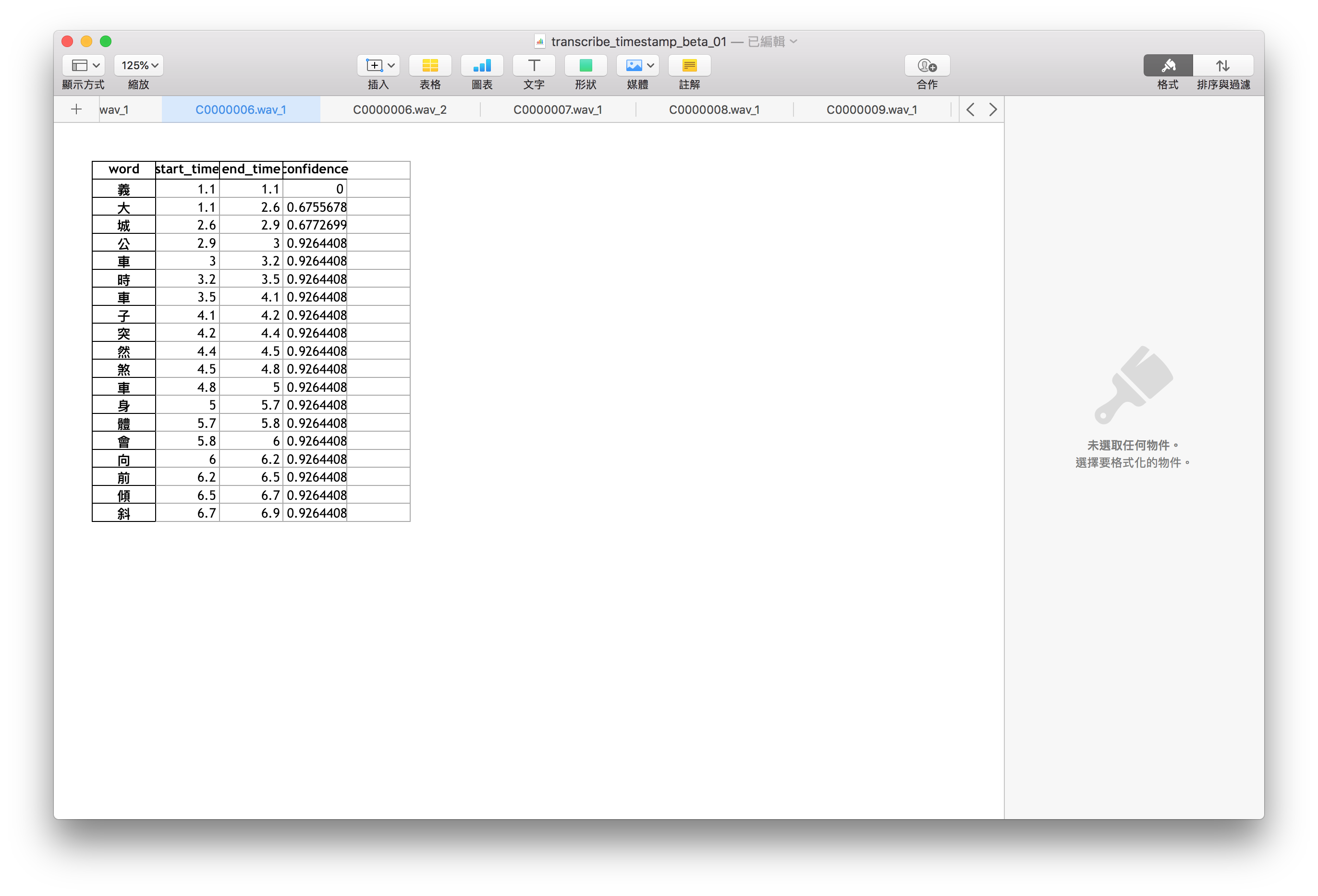 Figure 5 當audio phoneme之間的間隔超過1s,google api會自動把audio分段(上半段)
Figure 5 當audio phoneme之間的間隔超過1s,google api會自動把audio分段(上半段)
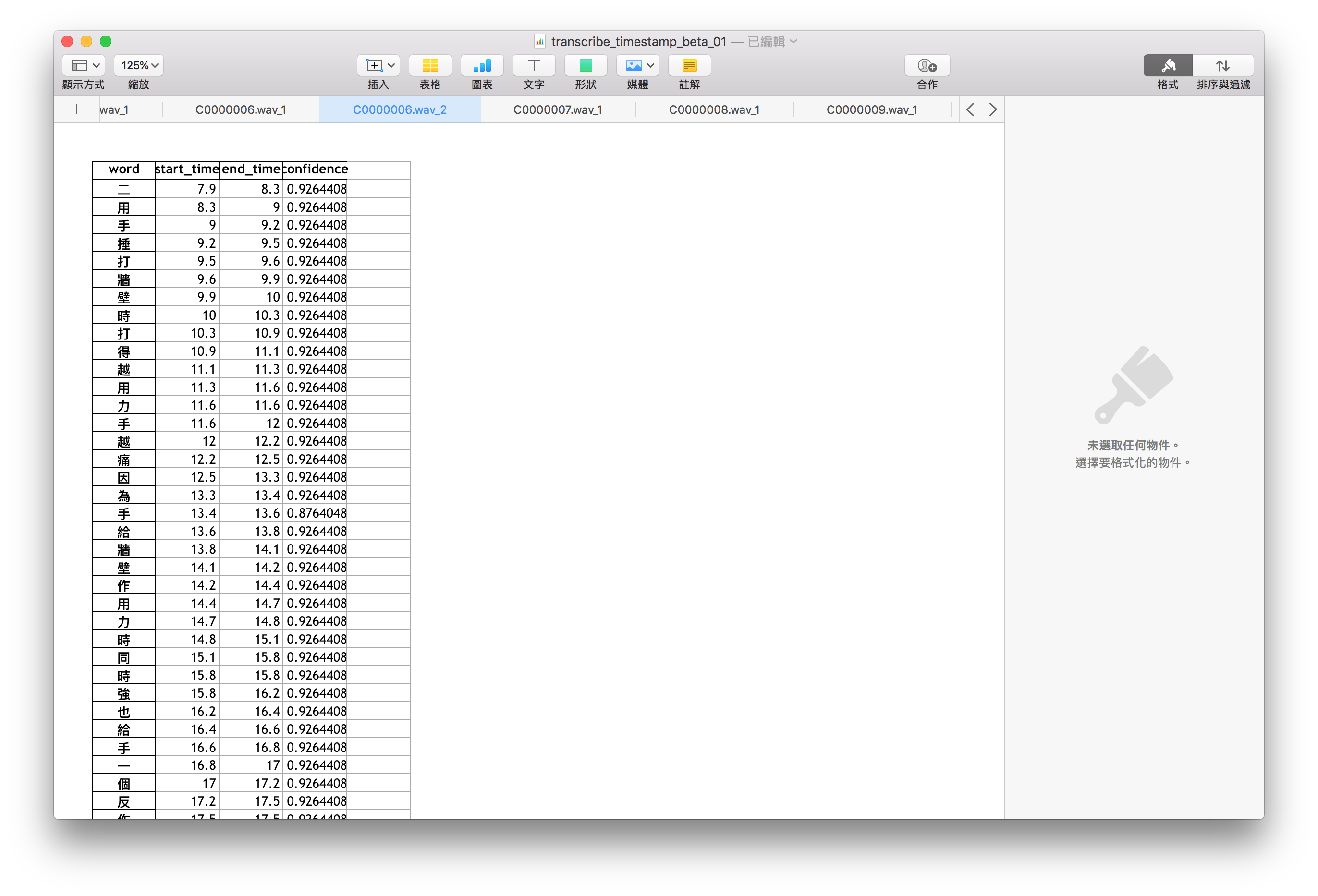 Figure 5 當audio phoneme之間的間隔超過1s,google api會自動把audio分段(下半段)
Figure 5 當audio phoneme之間的間隔超過1s,google api會自動把audio分段(下半段)
實驗結果與問題討論
目前會遇到的問題有1. 長句子精確度下降 (two-step) 2. "1","2","3","4" 同音異字or merge問題。
可再改良的作法
先分割完再丟辨識 change io.read to librosa (to get time2frame function)
read audio wav and manual boundary -> slice piece of audio -> transcribe to text -> show result(alternatives)