2# AI Great Challenge Preliminary Competition Round 1
本文件是為AI語音大擂台的準備文件,為了描述整體程式的架構跟所用到每個Component。
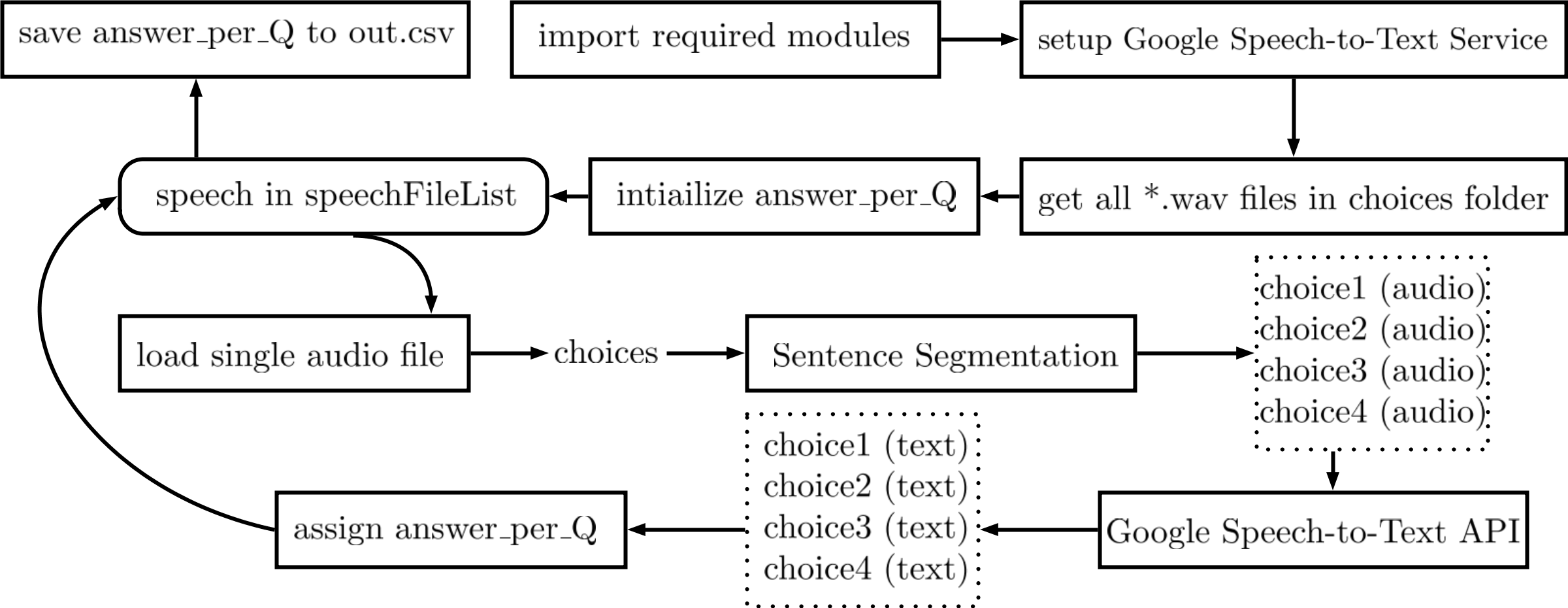 Figure 1: Flowchart of 第一版程式
Figure 1: Flowchart of 第一版程式
Figure 1 是整個main.py的流程,
- 導入要用到python modules
- 設定好 Google Speech-to-Text Service
- Client 是一個本地端程序(procedure?),負責把程式的指令傳送到Google Server[?]
- 使用
glob.glob()取得指定資料夾(./BC/C/)裡面所有副檔名為.wav的檔案名稱 - 使用for loop,對於每個檔案,把對應的audio匯入
- 一個audio包含4個選項,丟入Sentence Segmentation後把4個選項的音頻分開
- 每個選項就是一個句子,呼叫Google Speech API把audio轉換成Text
- 對於選項1~4,計算每個選項的字數,我們選擇字數最少的選項為答案,如果有兩個以上有最少的字數,則選擇選項數字最小的那一個
- 把每個問題的答案存成
out.csv,上傳到Kaggle。
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 """
4 Created on Sat Jun 23 08:57:19 2018
5
6 @author: PeterTsai
7 """
8
9 from pydub import AudioSegment
10 from pydub.silence import split_on_silence
11
12 # [START speech_quickstart]
13 import io
14 import os
15 import numpy as np
16 import pandas as pd
17 import glob
18
19 # Imports the Google Cloud client library
20 # [START migration_import]
21 from google.cloud import speech
22 from google.cloud.speech import enums
23 from google.cloud.speech import types
24 # [END migration_import]
25
26 # Instantiates a client
27 # [START migration_client]
28 client = speech.SpeechClient()
29 # [END migration_client]
30
31 config = types.RecognitionConfig(
32 encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
33 sample_rate_hertz=16000,
34 language_code='cmn-Hant-TW')
35
36 speechFileList = sorted(glob.glob('./BC/C/*.wav'))
37 answer_per_Q = np.zeros(len(speechFileList))+3
38
39 q = 1
40 ID = []
41 for speech in speechFileList:
42 print('Question {}'.format(q))
43 song = AudioSegment.from_wav(speech)
44
45 #split track where silence is 1 seconds or more and get chunks
46
47 chunks = split_on_silence(song,
48 # must be silent for at least 1 seconds or 1000 ms
49 min_silence_len=1000,
50
51 # consider it silent if quieter than -16 dBFS
52 #Adjust this per requirement
53 silence_thresh=song.dBFS
54 )
55
56 word_num_per_choice = np.zeros(len(chunks))
57 #Process each chunk per requirements
58 for i, chunk in enumerate(chunks):
59 #Create 0.5 seconds silence chunk
60 silence_chunk = AudioSegment.silent(duration=500)
61
62 #Add 0.5 sec silence to beginning and end of audio chunk
63 audio_chunk = silence_chunk + chunk + silence_chunk
64
65 # Loads the audio into memory
66 audio = types.RecognitionAudio(content=audio_chunk.raw_data)
67
68 # Detects speech in the audio file
69 response = client.recognize(config, audio)
70
71 for result in response.results:
72 print('Choice {}, Transcript: {}, word number: {}'.format(i+1, result.alternatives[0].transcript, len(result.alternatives[0].transcript)))
73 word_num_per_choice[i] = len(result.alternatives[0].transcript)
74
75 print('word_num_per_choice: ', word_num_per_choice)
76 answer = np.argmin(word_num_per_choice)+1
77 if answer >= 1 and answer <= 4:
78 answer_per_Q[q] = answer
79
80 ID.append(q)
81 q = q + 1
82
83 answers = {'ID':ID, 'Answer':answer_per_Q}
84 print(answers)
85 df = pd.DataFrame(data=answers, dtype=np.int32)
86 print(df)
87 df.to_csv('out.csv',index=False)