varSentencePadding in Utility file
def varSentencePadding(plots,max_len):
""" Padding batch of plots
Parameters
----------
plots : 4d numpy array, 4th level list
each dimension represents (batch, plot, sentence, word_vec) respectively
max_len : int
length of the longest sentence (default is 100)
Returns
-------
4d numpy array
batch of plots (padded)
"""
newPlot = []
filler = np.zeros(300)
max_plot_len = 0
plot_filler = np.zeros((max_len,300))
max_plot_len = 101
for plot in plots:
newSentence = []
for sentences in plot:
newSentence.append(sentences+[filler]*(max_len-len(sentences)))
newPlot.append(newSentence+[plot_filler]*(max_plot_len-len(plot)))
return np.asarray(newPlot)
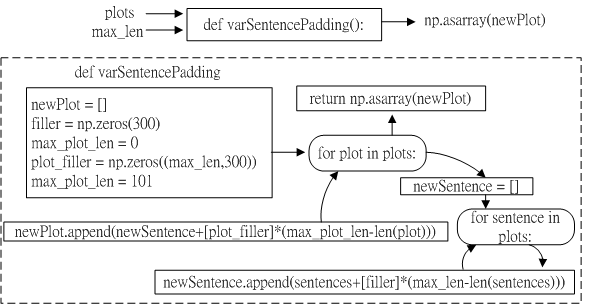
Fig.1 Schematic of varSentencePadding and overflow of varSentencePadding.
Fig.1 shows the flowchart of varSentencePadding function with "plots" (4d numpy array) and "max_len" (integer) two inputs.
The dimension in "plots" are batch, plot, sentence and word vec, respectively.
"max_len" refers to the length of the longest sentence.
"newPlot" is a 4d numpy array.
Test function in utility.py
def test(ACMNet_object,plotFilePath,data,batchSize,max_len,choice,isVal):
""" test the accuracy of given data
Parameters
----------
ACMNet_object : object instance
from class "MODEL" built up by tensorflow
plotFilePath : string
path of plot files in word vector form
data : list of dictionary
list of training data, each of which has structure of :
{
'imdb_key' : string
'question' : 2d numpy array (sentence, word_vec)
'answers' : 3d numpy array (5, sentence, word_vec)
'correct_index' : int
}
batchSize : int
max_len : list
only 3 elements are in the list,
["max length of sentence in plot", "max length of question", "max length of choice"]
choice : int
number of given choices (default 5)
isVal : bool
whether the given data is validation data
validation data : true
training data : false
Returns
-------
float
accuracy of given data
"""
batchP = []
batchQ = []
batchAnsVec = []
batchAnsOpt = []
### Test validation set #########
predictAns = []
filler = [0]*300
for question in data:
imdb_key = plotFilePath+question["imdb_key"]+".split.wiki.json"
with open(imdb_key) as data_file:
testP = json.load(data_file)
batchP.append(testP)
batchQ.append(question["question"])
AnsOption = []
for j in range(choice):
if question["answers"][j]:
pass
else:
question["answers"][j] = [filler]
batchAnsVec.append(question["answers"][j])
AnsOption.append(0)
AnsOption[question["correct_index"]] = 1
batchAnsOpt.append(AnsOption)
if len(batchP) == batchSize:
batchP = varSentencePadding(batchP,max_len[0])
batchQ = batchPadding(batchQ,max_len[1])
batchAnsVec = batchPadding(batchAnsVec,max_len[2])
tmp = ACMNet_object.predict(batchP,batchQ,batchAnsVec)
predictAns.extend(tmp)
batchP = []
batchQ = []
batchAnsVec = []
###calculate accuracy###
correct_num = 0.0
question_num = len(predictAns)
for idx in range(question_num):
predictIdx = predictAns[idx]
if batchAnsOpt[idx][predictIdx] == 1:
correct_num += 1
print ('correct:%d total:%d rate:%f' % (correct_num,question_num,correct_num/question_num))
print(predictAns)
return correct_num/question_num

Fig.2 schematic of def test function in utility.py file.
Fig.2 shows the schematic of def test function with "ACMNet object" (object instance), "plotFilePath" (string), "data" (list of dictionary), "batchsize" (integer), "max len" (integer), "choice" (integer), "isVal" (bool) as inputs parameters.
"ACMNEt object" is an object instance from "MODEL" class built up by tensorflow.
"plotFilePath" is a string, and is the path of plot files in word vector form.
"data" is a list of dictionary. "data" is a list of training data, each of which as structure of
{
'imdb_key': string
'question': 2d numpy array (sentence, word vector)
'answer' : 3d numpy array (5, sentence, word vector)
'correct index': integer
}
"batchSize" is an integer.
"max len" is a list. Three elements are in the "max len" list
"max length of sentence in plot",
"max length of question",
"max length of choice"
"choice" is an integer. "choice" is the number of given choices (default 5).
"isVal" is a bool, and it refers to whether the given data is validation data.
The accuracy of given data is returned by this test function.
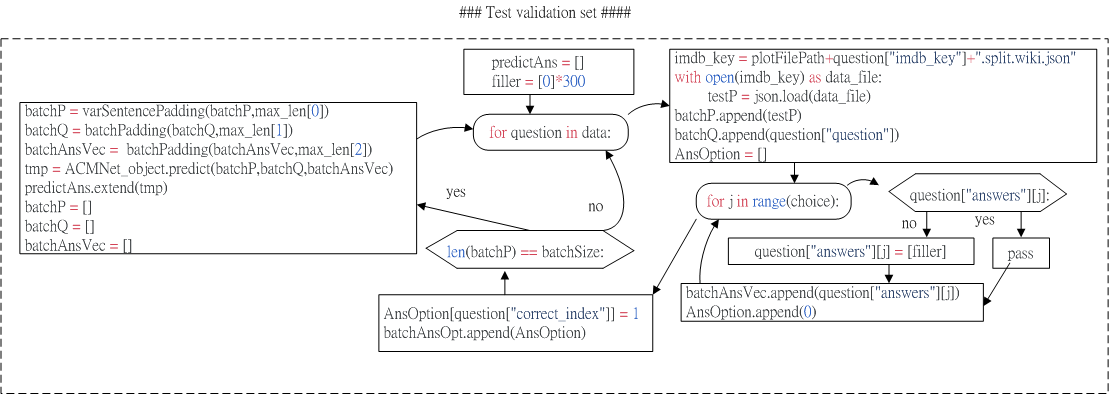
Fig.3 Flowchart of Test validation set part.
The imdb key stores the data path as
where is iteration index.
Fig.3 shows the flowchart of test validation set.

Fig.4 Flowchart of calculate accuracy part.
Fig.4 shows the flow chart of calculate accuracy part.
As the model prediction is correct, , the number of correction is added, .
The accuracy is calculated as