Neural Machine Translation (seq2seq)
Shrimp Chen 0422/2018
Structure of the document
background on NMT
installing the tutorial
training
-embedding
-encoder
-decoder
-loss
-gradient computation & optimization
hands-on train an NMT model
inference
background on attention mechansim
hands-on building an attention-based NMT model
building training, eval, inference graphs
data input pipeline
other details for better NMT models
-bidirectional RNN
-beam search
-hyperparameters
-hyperparameters
-multi-GPU-training
IWSLT English-Vietnamese
WMT German-English
WMTEnglish-German -full comparison
StadardHPHParams
Required Environment
This tutorial requires TensorFlow Nightly [1].
TensorFlow versions of tf-1.4 is recommended [2].
Introduction
Sequence-to-sequence (seq2seq) models are used for machine translation, speech recognition, and text summarization.
This tutorial will show how to build a competitive seq2seq model from scratch, and focus on Neural Machine Translation (NMT).
The basic knoweldge about seq2seq models for NMT is introduced.
How to build and train a vanilla NMT model is explained.
Details of building a NMT model with attention mechanism will be described.
Tips and tricks to build the best possible NMT models (both in speed and translation quality) such as TensorFlow best practices (batching, bucketing), bidirectional RNNs, beam search, as well as scaling up to multiple GPUs using GNMT attention are discussed.
Basic
Background on Neural Machine Translation
Traditional phrase-based translation systems performed their task by breaking up source sentences into multiple chunks and then translated them phrase-by-phrase. However, Neural Machine Translation (NMT) mimics how humans translate- read the whole sentence, understand its meaning, and then translate.

Figure 1. An example of a general approach for NMT (often refers as the encoder-decoder architecture). An encoder converts a source sentence into a "meaning" vector which is passed through a decoder to produce a translation.
As shown in Figure 1, an NMT system first reads the source sentence using an encoder to build a "thought" vector, a sequence of numbers that represents the sentence meaning; a decoder, then, processes the sentence vector to emit a translation.
In this manner, NMT can capture long-range dependencies in languages, e.g., gender agreements, syntax structures, etc.
NMT models vary in terms of their exact architectures. Recurrent neural network (RNN) is used by most NMT models for sequential data.
An RNN is usually used for both the encoder and decoder. The RNN models differ in terms of: (a) directionality – unidirectional or bidirectional; (b) depth – single- or multi-layer; and (c) type – often either a vanilla RNN, a Long Short-term Memory (LSTM), or a gated recurrent unit (GRU).
In this tutorial, a deep multi-layer RNN which is unidirectional and LSTM are considered as a recurrent unit. This model is shown in Figure 2. In the model, a source sentence "I am a student" was translated into a target sentence "Je suis étudiant".
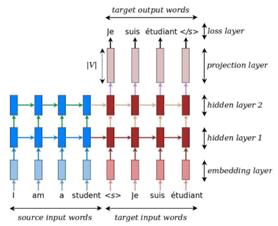
Figure 2. An example of a deep recurrent architecture. Here, "<s>" marks the start of the decoding process while "</s>" tells the decoder to stop. (說明不清楚,待理解後要再補)
At a high level, the NMT model consists of two recurrent neural networks: the encoder RNN simply consumes the input source words without making any prediction; the decoder, on the other hand, processes the target sentence while predicting the next words.
Installing the Tutorial
To install this tutorial, we need to have TensorFlow installed on our system. It requires TensorFlow Nightly. To install TensorFolw, follow the instructions here.
Then, we can download the source code of this tutorial by running:
git clone https://github.com/tensorflow/nmt
Training-How to build NMT system
Let's first dive into the heart of building an NMT model with concrete code snippets through which we will explain Figure 2. in more detail. We defer data preparation and the full code to later. This part refers to the file model.py.
At the bottom layer, the encoder and decoder RNNs receive as input the following: first, the source sentence, then a boundary marker "\<s>" which indicates the transition from encoding to the decoding mode, and the target sentence. For _training, _we will feed the system with the following tensors, which are in time-major format and contain word indices:
- encoder inputs [max_encoder_time, batch_size]: source input words.
- decoder inputs [max_encoder_time, batch_size]: target input words.
- decoder outputs [max_decoder_time, batch_size]: target output words, these are decoder inputs shifted to the left by one time step with and end-of-sentence tag appended on the right.
Here foe efficiency, we train with multiple sentence (batch_size) at once. Testing is slightly different, so we will discuss it later.
Embedding
Given the categorical nature of words, the model must first look up the source and target embeddings to retrieve the corresponding word representations. For this _embedding _layer to work, a vocabulary is first chosen for each language. Usually, a vocabulary size V is selected, and only the most frequent words are treated as unique. All other words are converted to an "unknown" token and all get the same embedding The embedding weights, one set per language, are usually learner during training.
這裡還有一段表格
Similarly, we can build embedding_decoder _and _decoder_emb_inp. Note that one can choose to initialize embedding weights with pretrained word representations such as word2vec or Glove vectors. In general, given a large amount of training data we can learn these embeddings from scratch.
Encoder
Decoder
Loss
Gradient computation & optimization
Hands-on train an NMT model
nmt.py
Inference- generate translations
Intermediate
Background on the Attention Mechanism
Attention Wrapper API
Hands-on building an attention-based NMT model
Tips and Tricks
Building training, Eval, and inference Graphs
Data input pipeline
Other details for better NMT models
bidirectional RNNs,
Beam search,
hyperparameters,
multi-GPU training,
Benchmarks
IWSLT English-Vietnames
WMT German-English
WMT English-German -full comparison
Standard HParams
other resources
Reference
[0] https://www.tensorflow.org/tutorials/seq2seq