Fixed-size-segment Segmentation & Classification
Fixed-size-segment segmentation & Classification is applied on fix-sized segments of an audio recording, and yields a sequence of class labels.
Fixed-size-segment segmentation refers to mtFileClassification() function in audioSegmentation.py
mtFileClassification()
mtFileClassification()splits an audio signal to successive mid-term segments (fixed-sized segment) and extracts mid-term feature statistics from each segments, usingmtFeatureExtraction()inaudioFeatureExtraction.pymtFileClassification()classifies each mid-term segment using a pre-trained supervised model.mtFileClassification()merges successive fix-sized segments, which share the same class label, into larger segments.- The statistics of the result of segmentation-classification process can be visualized.
Usage example
from pyAudioAnalysis import audioSegmention as aS
[flagsInd, classesAll, acc, CM] = as.mtFileClassification("data/scottish.wav", "data/svmSM", "svm", True, 'data/scottish.segments')
data/scottish.segments (last argument) is used as ground-truth (if available) to estimate overall performance of classification-segmentation method. If data/scottish.segments does not exist, the performance measure is not calculated.
The .segments files are comma-separated format <segment start (seconds)>, <segment end (seconds)>, <segment label>. For example
0.01, 9.90, speech
9.90, 10.70, silence
10.70, 23.50, speech
23.50, 184.30, music
184.30, 185.10, silence
185.10, 200.75, speech
...
Function plotSegmentationResults() plots segmentation-classification result and evaluate the performance of this result (if ground-truth file is available).
Command-line usage
python audioAnalysis.py segmentClassifyFile -i <inputFile> --model <model type svm or knn)> --modelName <path to classifier model>
Example
python audioAnalysis.py segmentClassifyFile -i data/scottish.wav --model svm --modelName data/svmSM
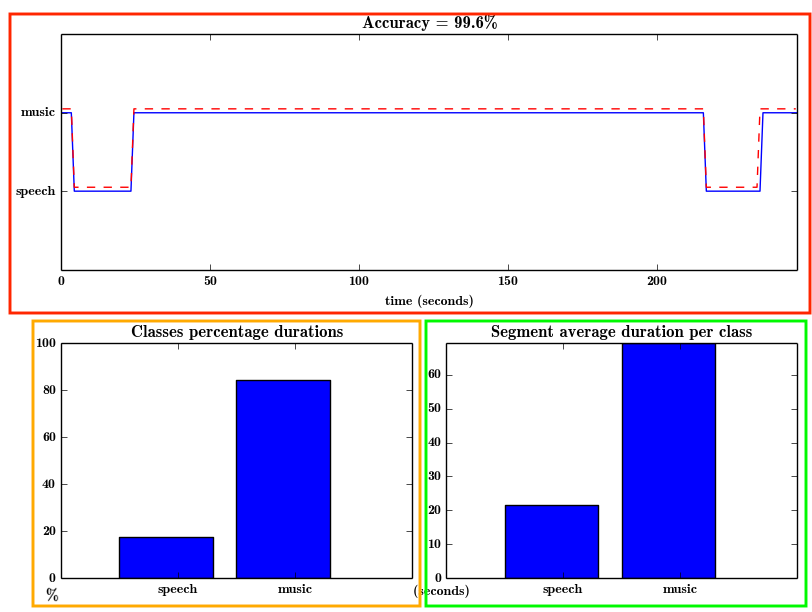 Figure 1 Segmentation-Classification Result of
Figure 1 Segmentation-Classification Result of data/scottish.wav
Figure 1 shows response of commanding code python audioAnalysis.py segmentClassifyFile -i data/scottish.wav --model svm --modelName data/svmSM result.
Figure 1(紅)中 紅色虛線是ground-truth答案,藍色實線Fixed-size-segment Segmentation & Classification的結果。
The overall accuracy of 99.6% is calculated from ground-truth data/scottish.segments.
Figure 1(橙)顯示每個Class在audio duration的比例。
Figure 1(綠)顯示每個Class平均的時間長度。