MODEL.py 定義了 QACNN model
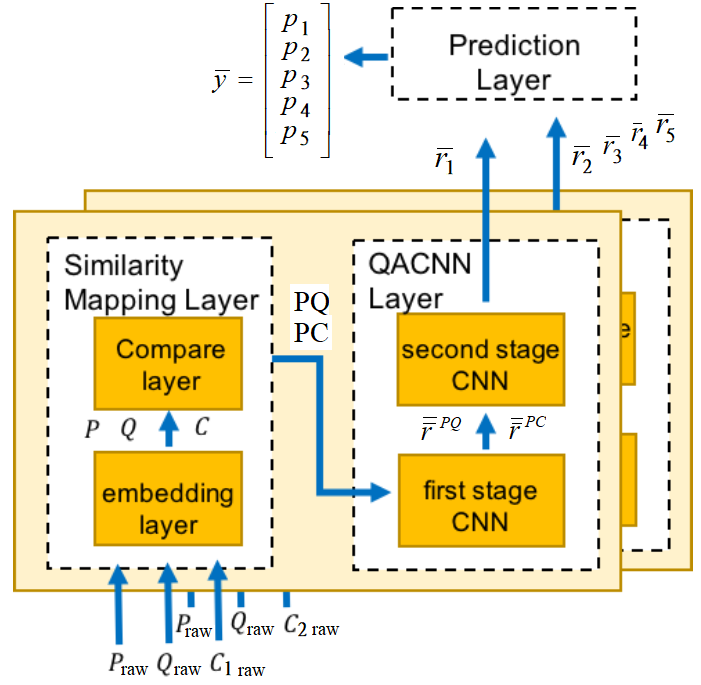
Fig.1 Overview on QACNN model.
denotes the probability of choices A, B, C, D and E.
is a paragraph.
is a query.
is choice, including , , , and .
MODEL.py 分為三個部分。第一部分為 import modules。第二部分為 class MODEL 中的 __init__ 函式。第三部分為 class MODEL 中的其他函式,統稱為 Utility
Figure 1: Schematic View of model.py , Functions other than __init__ can be view as utility.
Fig.1 為 MODEL.py 的三個部分。import modules, class MODEL 中的 __init__ 函式,以及 class MODEL 中的其他函式
import numpy as np
import json
import tensorflow as tf
from tensorflow.python.ops import control_flow_ops
from tensorflow.python.ops import math_ops
from tensorflow.python.ops import state_ops
from tensorflow.python.framework import ops
from tensorflow.python.training import optimizer
class MODEL(object):
def __init__(self,batch_size,x_dimension,dnn_width,cnn_filterSize,cnn_filterSize2,cnn_filterNum,cnn_filterNum2 ,learning_rate,dropoutRate,choice,max_plot_len,max_len,parameterPath):
self.parameterPath = parameterPath
self.p = tf.placeholder(shape=(batch_size,max_plot_len,max_len[0],x_dimension), dtype=tf.float32) ##(batch_size,p_sentence_num,p_sentence_length,x_dimension)
self.q = tf.placeholder(shape=(batch_size,max_len[1],x_dimension), dtype=tf.float32) ##(batch_size,q_sentence_length,x_dimension)
self.ans = tf.placeholder(shape=(batch_size*choice,max_len[2],x_dimension), dtype=tf.float32) ##(batch_size*5,ans_sentence_length,x_dimension)
self.y_hat = tf.placeholder(shape=(batch_size,choice), dtype=tf.float32) ##(batch_size,5)
self.dropoutRate = tf.placeholder(tf.float32)
self.filter_size = cnn_filterSize
self.filter_size2 = cnn_filterSize2
self.filter_num = cnn_filterNum
self.filter_num2 = cnn_filterNum2
choose_sentence_num = max_plot_len
normal_p = tf.nn.l2_normalize(self.p,3)
## (batch_size,max_plot_len*max_len[0],x_dimension)
normal_p = tf.reshape(normal_p,[batch_size,max_plot_len*max_len[0],x_dimension])
## (batch_size,max_len[1],x_dimension)
normal_q = tf.reshape(tf.nn.l2_normalize(self.q,2),[batch_size,max_len[1],x_dimension])
normal_ans = tf.nn.l2_normalize(self.ans,2)
## (batch_size,choice*max_len[2],x_dimension)
normal_ans = tf.reshape(normal_ans,[batch_size,choice*max_len[2],x_dimension])
PQAttention = tf.matmul(normal_p,tf.transpose(normal_q,[0,2,1])) ##(batch,max_plot_len*max_len[0],max_len[1])
PAnsAttention = tf.matmul(normal_p,tf.transpose(normal_ans,[0,2,1])) ##(batch,max_plot_len*max_len[0],choice*max_len[2])
PAnsAttention = tf.reshape(PAnsAttention,[batch_size,max_plot_len*max_len[0],choice,max_len[2]]) ##(batch,max_plot_len*max_len[0],choice,max_len[2])
PAAttention,PBAttention,PCAttention,PDAttention,PEAttention = tf.unstack(PAnsAttention,axis = 2) ##[batch,max_plot_len*max_len[0],max_len[2]]
PQAttention = tf.unstack(tf.reshape(PQAttention,[batch_size,max_plot_len,max_len[0],max_len[1],1]),axis = 1) ##[batch,max_len[0],max_len[1],1]
PAAttention = tf.unstack(tf.reshape(PAAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
PBAttention = tf.unstack(tf.reshape(PBAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
PCAttention = tf.unstack(tf.reshape(PCAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
PDAttention = tf.unstack(tf.reshape(PDAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
PEAttention = tf.unstack(tf.reshape(PEAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
### CNN 1 ###
pooled_outputs_PQ_1 = []
pooled_outputs_PA_1 = []
pooled_outputs_PB_1 = []
pooled_outputs_PC_1 = []
pooled_outputs_PD_1 = []
pooled_outputs_PE_1 = []
for i, filter_size in enumerate(self.filter_size):
with tf.name_scope("conv1-maxpool-%s" % (filter_size)):
filter_shape = [filter_size,max_len[2], 1, self.filter_num]
W1 = tf.get_variable(name="W1-%s"%(filter_size), shape=filter_shape,initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.constant(0.1, shape=[self.filter_num]), name="b1")
WQ1 = tf.get_variable(name="WQ1-%s"%(filter_size), shape=filter_shape,initializer=tf.contrib.layers.xavier_initializer())
bQ1 = tf.Variable(tf.constant(0.1, shape=[self.filter_num]), name="bQ1")
hiddenPQ_1 = []
hiddenPA_1 = []
hiddenPB_1 = []
hiddenPC_1 = []
hiddenPD_1 = []
hiddenPE_1 = []
for sentence_ind in range(len(PQAttention)):
convPQ_attention = tf.nn.conv2d(
PQAttention[sentence_ind],
WQ1,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
convPQ_1 = tf.nn.conv2d(
PQAttention[sentence_ind],
W1,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
convPA_1 = tf.nn.conv2d(
PAAttention[sentence_ind],
W1,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
convPB_1 = tf.nn.conv2d(
PBAttention[sentence_ind],
W1,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
convPC_1 = tf.nn.conv2d(
PCAttention[sentence_ind],
W1,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
convPD_1 = tf.nn.conv2d(
PDAttention[sentence_ind],
W1,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
convPE_1 = tf.nn.conv2d(
PEAttention[sentence_ind],
W1,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch,wordNumberP- filter_size + 1, 1,self.filter_num]
wPQ_1 = tf.transpose(tf.sigmoid(tf.nn.bias_add(convPQ_attention,bQ1)),[0,3,2,1])
wPQ_1 = tf.nn.dropout(wPQ_1,self.dropoutRate)
wPQ_1 = tf.nn.max_pool(
wPQ_1,
ksize=[1,self.filter_num, 1,1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool_pq") ## [batch_size,1,1,wordNumberP- filter_size
wPQ_1 = tf.transpose(tf.tile(wPQ_1,[1,self.filter_num,1,1]),[0,3,2,1])
onesentence_hiddenPQ_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPQ_1, b1), name="relu"),self.dropoutRate)
hiddenPQ_1.append(onesentence_hiddenPQ_1)
onesentence_hiddenPA_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPA_1, b1), name="relu"),self.dropoutRate)*wPQ_1
hiddenPA_1.append(onesentence_hiddenPA_1)
onesentence_hiddenPB_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPB_1, b1), name="relu"),self.dropoutRate)*wPQ_1
hiddenPB_1.append(onesentence_hiddenPB_1)
onesentence_hiddenPC_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPC_1, b1), name="relu"),self.dropoutRate)*wPQ_1
hiddenPC_1.append(onesentence_hiddenPC_1)
onesentence_hiddenPD_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPD_1, b1), name="relu"),self.dropoutRate)*wPQ_1
hiddenPD_1.append(onesentence_hiddenPD_1)
onesentence_hiddenPE_1 = tf.nn.dropout(tf.nn.relu(tf.nn.bias_add(convPE_1, b1), name="relu"),self.dropoutRate)*wPQ_1
hiddenPE_1.append(onesentence_hiddenPE_1)
hiddenPQ_1 = tf.concat(hiddenPQ_1, 1) ## [batch,max_plot_len*(wordNumberP- filter_size + 1), 1,self.filter_num]
hiddenPA_1 = tf.concat(hiddenPA_1, 1)
hiddenPB_1 = tf.concat(hiddenPB_1, 1)
hiddenPC_1 = tf.concat(hiddenPC_1, 1)
hiddenPD_1 = tf.concat(hiddenPD_1, 1)
hiddenPE_1 = tf.concat(hiddenPE_1, 1)
hiddenPQ_1 = tf.reshape(tf.squeeze(hiddenPQ_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num]) ## [batch,max_plot_len,(wordNumberP- filter_size + 1),self.filter_num]
hiddenPA_1 = tf.reshape(tf.squeeze(hiddenPA_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
hiddenPB_1 = tf.reshape(tf.squeeze(hiddenPB_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
hiddenPC_1 = tf.reshape(tf.squeeze(hiddenPC_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
hiddenPD_1 = tf.reshape(tf.squeeze(hiddenPD_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
hiddenPE_1 = tf.reshape(tf.squeeze(hiddenPE_1), [batch_size, max_plot_len, (max_len[0] - filter_size + 1), self.filter_num])
pooledPQ_1 = tf.nn.max_pool(
hiddenPQ_1,
ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ## [batch_size, max_plot_len, 1, self.filter_num]
pooled_outputs_PQ_1.append(pooledPQ_1)
pooledPA_1 = tf.nn.max_pool(
hiddenPA_1,
ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ## [batch_size, max_plot_len, 1, self.filter_num]
pooled_outputs_PA_1.append(pooledPA_1)
pooledPB_1 = tf.nn.max_pool(
hiddenPB_1,
ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ##[batch_size, max_plot_len, 1, self.filter_num]
pooled_outputs_PB_1.append(pooledPB_1)
pooledPC_1 = tf.nn.max_pool(
hiddenPC_1,
ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ##[batch_size, max_plot_len, 1, self.filter_num]
pooled_outputs_PC_1.append(pooledPC_1)
pooledPD_1 = tf.nn.max_pool(
hiddenPD_1,
ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ##[batch_size, max_plot_len, 1, self.filter_num
pooled_outputs_PD_1.append(pooledPD_1)
pooledPE_1 = tf.nn.max_pool(
hiddenPE_1,
ksize=[1, 1, (max_len[0] - filter_size + 1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ##[batch_size, max_plot_len, 1, self.filter_num]
pooled_outputs_PE_1.append(pooledPE_1)
h_pool_PQ_1 = tf.transpose(tf.concat(pooled_outputs_PQ_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
h_pool_PA_1 = tf.transpose(tf.concat(pooled_outputs_PA_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
h_pool_PB_1 = tf.transpose(tf.concat(pooled_outputs_PB_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
h_pool_PC_1 = tf.transpose(tf.concat(pooled_outputs_PC_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
h_pool_PD_1 = tf.transpose(tf.concat(pooled_outputs_PD_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
h_pool_PE_1 = tf.transpose(tf.concat(pooled_outputs_PE_1, 3), perm=[0,3,1,2]) ##[batch_size, num_filters_total, max_plot_len, 1]
### CNN 2 ###
pooled_outputs_PQ_2 = []
pooled_outputs_PA_2 = []
pooled_outputs_PB_2 = []
pooled_outputs_PC_2 = []
pooled_outputs_PD_2 = []
pooled_outputs_PE_2 = []
num_filters_total = self.filter_num * len(self.filter_size)
for i, filter_size in enumerate(self.filter_size2):
with tf.name_scope("conv2-maxpool-%s" % (filter_size)):
filter_shape = [num_filters_total, filter_size, 1, self.filter_num2]
W2 = tf.get_variable(name="W2-%s"%(filter_size),shape = filter_shape,initializer = tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.constant(0.1, shape=[self.filter_num2]), name="b2")
WQ2 = tf.get_variable(name="WQ2-%s"%(filter_size),shape = filter_shape,initializer= tf.contrib.layers.xavier_initializer())
bQ2 = tf.Variable(tf.constant(0.1, shape=[self.filter_num2]), name="bQ2")
convPQ_2 = tf.nn.conv2d(
h_pool_PQ_1,
WQ2,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch, 1, (max_plot_len-filter_size+1), self.filter_num]
convPA_2 = tf.nn.conv2d(
h_pool_PA_1,
W2,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch, 1, (max_plot_len-filter_size+1), self.filter_num]
convPB_2 = tf.nn.conv2d(
h_pool_PB_1,
W2,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch, 1, (max_plot_len-filter_size+1), self.filter_num]
convPC_2 = tf.nn.conv2d(
h_pool_PC_1,
W2,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch, 1, (max_plot_len-filter_size+1), self.filter_num]
convPD_2 = tf.nn.conv2d(
h_pool_PD_1,
W2,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch, 1, (max_plot_len-filter_size+1), self.filter_num]
convPE_2 = tf.nn.conv2d(
h_pool_PE_1,
W2,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")## [batch, 1, (max_plot_len-filter_size+1), self.filter_num]
#hiddenPQ_2 = tf.nn.relu(tf.nn.bias_add(convPQ_2, b2), name="relu")
wPQ_2 = tf.transpose(tf.sigmoid(tf.nn.bias_add(convPQ_2,bQ2)),[0,3,2,1])
wPQ_2 = tf.nn.dropout(wPQ_2,self.dropoutRate)
wPQ_2 = tf.nn.max_pool(
wPQ_2,
ksize=[1,self.filter_num2, 1,1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool_pq_2") ## [batch_size,1,max_plot_len- filter_size+1,1]
wPQ_2 = tf.transpose(tf.tile(wPQ_2,[1,self.filter_num2,1,1]),[0,3,2,1])
hiddenPA_2 = tf.nn.relu(tf.nn.bias_add(convPA_2, b2), name="relu")*wPQ_2
hiddenPB_2 = tf.nn.relu(tf.nn.bias_add(convPB_2, b2), name="relu")*wPQ_2
hiddenPC_2 = tf.nn.relu(tf.nn.bias_add(convPC_2, b2), name="relu")*wPQ_2
hiddenPD_2 = tf.nn.relu(tf.nn.bias_add(convPD_2, b2), name="relu")*wPQ_2
hiddenPE_2 = tf.nn.relu(tf.nn.bias_add(convPE_2, b2), name="relu")*wPQ_2
hiddenPA_2 = tf.nn.dropout(hiddenPA_2,self.dropoutRate)
hiddenPB_2 = tf.nn.dropout(hiddenPB_2,self.dropoutRate)
hiddenPC_2 = tf.nn.dropout(hiddenPC_2,self.dropoutRate)
hiddenPD_2 = tf.nn.dropout(hiddenPD_2,self.dropoutRate)
hiddenPE_2 = tf.nn.dropout(hiddenPE_2,self.dropoutRate)
pooledPA_2 = tf.nn.max_pool(
hiddenPA_2,
ksize=[1, 1, (max_plot_len-filter_size+1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ## [batch_size, 1, 1, self.filter_num]
pooled_outputs_PA_2.append(pooledPA_2)
pooledPB_2 = tf.nn.max_pool(
hiddenPB_2,
ksize=[1, 1, (max_plot_len-filter_size+1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ##[batch_size, 1, 1, self.filter_num]
pooled_outputs_PB_2.append(pooledPB_2)
pooledPC_2 = tf.nn.max_pool(
hiddenPC_2,
ksize=[1, 1, (max_plot_len-filter_size+1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ##[batch_size, 1, 1, self.filter_num]
pooled_outputs_PC_2.append(pooledPC_2)
pooledPD_2 = tf.nn.max_pool(
hiddenPD_2,
ksize=[1, 1, (max_plot_len-filter_size+1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ##[batch_size, 1, 1, self.filter_num]
pooled_outputs_PD_2.append(pooledPD_2)
pooledPE_2 = tf.nn.max_pool(
hiddenPE_2,
ksize=[1, 1, (max_plot_len-filter_size+1), 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool") ##[batch_size, 1, 1, self.filter_num]
pooled_outputs_PE_2.append(pooledPE_2)
num_filters_total = self.filter_num2 * len(self.filter_size2)
h_pool_PA_2 = tf.concat(pooled_outputs_PA_2, 3) ##[batch_size, 1, 1,num_filters_total]
h_pool_PB_2 = tf.concat(pooled_outputs_PB_2, 3) ##[batch_size, 1, 1,num_filters_total]
h_pool_PC_2 = tf.concat(pooled_outputs_PC_2, 3) ##[batch_size, 1, 1,num_filters_total]
h_pool_PD_2 = tf.concat(pooled_outputs_PD_2, 3) ##[batch_size, 1, 1,num_filters_total]
h_pool_PE_2 = tf.concat(pooled_outputs_PE_2, 3) ##[batch_size, 1, 1,num_filters_total]
h_pool_flat_PA = tf.squeeze(h_pool_PA_2) ##[batch_size, num_filters_total]
h_pool_flat_PB = tf.squeeze(h_pool_PB_2) ##[batch_size, num_filters_total]
h_pool_flat_PC = tf.squeeze(h_pool_PC_2) ##[batch_size, num_filters_total]
h_pool_flat_PD = tf.squeeze(h_pool_PD_2) ##[batch_size, num_filters_total]
h_pool_flat_PE = tf.squeeze(h_pool_PE_2) ##[batch_size, num_filters_total]
result = tf.concat([h_pool_flat_PA,h_pool_flat_PB,h_pool_flat_PC,h_pool_flat_PD,h_pool_flat_PE],0) #[5*batch_size,num_filters_total]
with tf.variable_scope('last_DNN_PARAMETER'):
wtrans = tf.get_variable("wtrans", [num_filters_total,dnn_width],initializer=tf.truncated_normal_initializer(stddev=0.1,dtype=tf.float32))
btrans = tf.get_variable("btrans", [dnn_width],initializer=tf.truncated_normal_initializer(stddev=0.1,dtype=tf.float32))
wout = tf.get_variable("wout", [dnn_width,1],initializer=tf.truncated_normal_initializer(stddev=0.1,dtype=tf.float32))
bout = tf.get_variable("bout", [1],initializer=tf.truncated_normal_initializer(stddev=0.1,dtype=tf.float32))
y = tf.tanh(tf.matmul(result,wtrans)+btrans) ##(5*batch,dnn_width)
y = tf.matmul(y,wout)+bout ##(5*batch,1)
y = tf.transpose(tf.reshape(y,[5,batch_size]),[1,0]) ##(batch,5)
self.output_logit = tf.nn.softmax(y)
self.predict_result = tf.argmax(y, dimension=1)
self.cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y,labels=self.y_hat))
global_step = tf.Variable(0, trainable=False)
self.train_op = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(self.cost,global_step=global_step)
self.saver = tf.train.Saver()
self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement = True))
######### Utility #########
def train(self,input_p,input_q,input_ans,input_y_hat,input_dropout):
_,loss = self.sess.run([self.train_op,self.cost],feed_dict={self.p:input_p,self.q:input_q,self.ans:input_ans,
self.y_hat:input_y_hat,
self.dropoutRate:input_dropout})
return loss
def initialize(self):
print ("init")
self.sess.run(tf.global_variables_initializer())
def save(self,num):
save_path = self.saver.save(self.sess, "para/acm_model_"+str(num)+".ckpt")
print ("Model saved in file: ",save_path)
def restore(self,path):
self.saver.restore(self.sess,path)
print ("Model restored")
def predict(self,input_p,input_q,input_ans):
return self.sess.run(self.predict_result,feed_dict={self.p:input_p,self.q:input_q,self.ans:input_ans,self.dropoutRate:1})
def predict_prob(self,input_p,input_q,input_ans):
return self.sess.run(self.output_logit,feed_dict={self.p:input_p,self.q:input_q,self.ans:input_ans,self.dropoutRate:1})