MovieQA: Story Understanding Benchmark
MovieQA[1] was introduced by Toronto Unviversity, which aims to evaluate automatic story comprehension from both video and text. The dataset consists of almost 15,000 multiple choice question answers* obtained from over 400 movies** and features high semantic diversity.
Each question comes with a set of five highly plausible answers; only one of which is correct. The questions can be answered using multiple sources of information movie clips, plots, subtitles, and for a subset scripts and DVS [2]. DVS (Descriptive video service) is a linguistic description that allow visually impaired people to follow a movie.
To adapt MovieQA dataset into your code, you must first understand how to download and run code in MovieQA repository[3].
Fig. 1 shows how to adapt movieQA as your training data.
 Figure 1: Flowchart of Adapting MovieQA dataset into your codes
Figure 1: Flowchart of Adapting MovieQA dataset into your codes
Fig. 2 shows file hierarchy of the MovieQA repository. .gitignore, CHANGELOG, and README.md are used for GitHub configuration. __init__.py and config.py are used for python module configuration. data_loader.py, download_dvs_stories.py, and story_loader.py are codes to access benchmark dataset. Folder data contains metadata of movie stories in json format. Folder story contains MovieQA source data which detail will be described in following article.
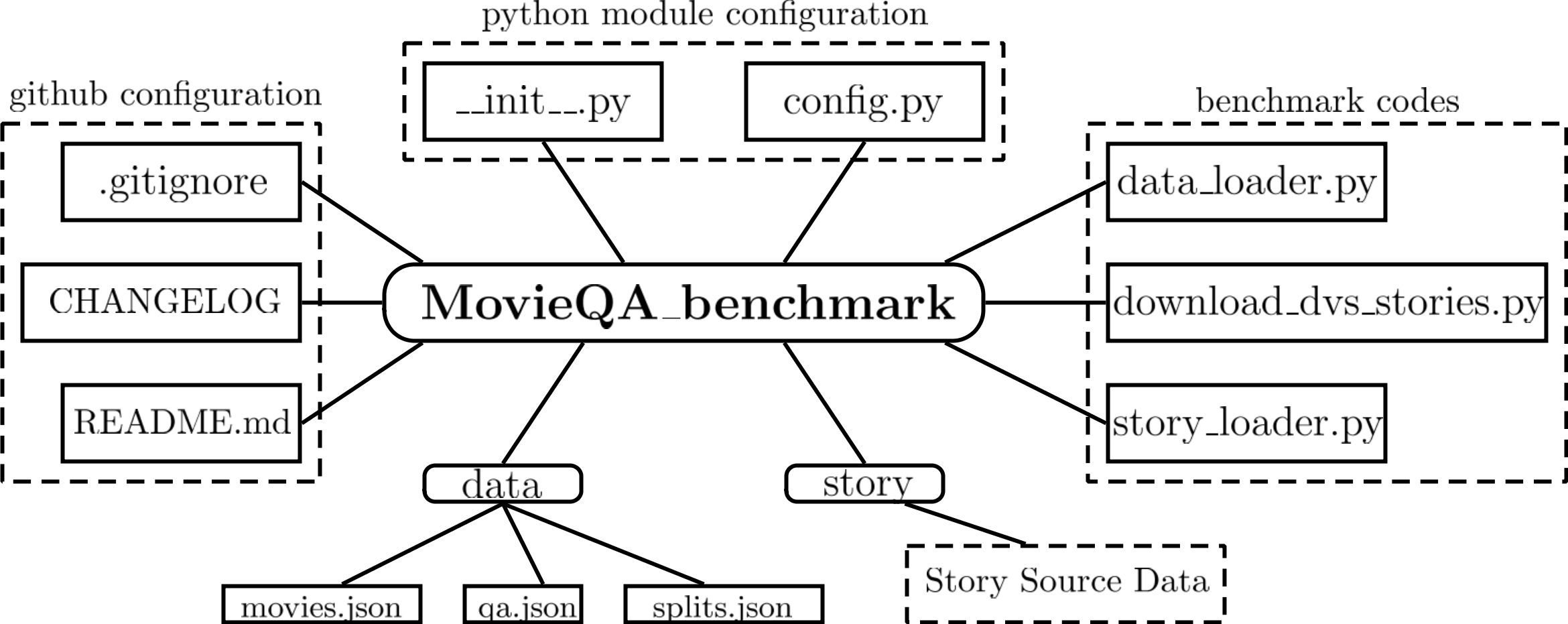 Figure 2: Schematic of MovieQA Github repository
Figure 2: Schematic of MovieQA Github repository
[1] http://movieqa.cs.toronto.edu/home/
[2] MPII Movie Description dataset
[3] Benchmark data and code for Question-Answering on Movie stories