Run QACNN codes on Ubuntu Linux
Anaconda Environment
我們使用Anaconda來安裝tensorflow package,好處是可以透過設定不同anaconda environment在一台主機上模擬不同python版本、不同tensorflow版本做測試。安裝anaconda的方式是
- 到Anaconda的官網[2]下載anaconda,選擇python 3.6的安裝檔。
- 在Termial type
bash Anaconda3-4.3.1-Linux-x86_64.sh - 設定一些系統變數(??設定什麼系統變數??),安裝完成。
安裝完Anaconda之後,我們要新增一個anaconda環境tensorflow-1.8py3。
做法是在Terminal type conda create -n tensorflow-1.8py3 pip python=3,
等安裝環境完成後,type source activate tensorflow-1.8py3。
這時terminal會在指令列最前面出現(tensorflow-1.8py3),這代表Terminal已經在anaconda環境tensorflow-1.8py3下運作,所有安裝操作只會更動tensorflow-1.8py3環境的設定,不會影響到原本的主機。
接下來要安裝QACNN需要的module tensorflow, nltk。
安裝tensorflow的方式是在tensorflow-1.8py3環境下輸入[3]
(tensorflow-1.8py3)$ pip install --ignore-installed --upgrade tfBinaryURL
其中的tfBinaryURL是指網路上tensorflow binary code的網路路徑(URL),我們要安裝的是python 3.6版本的tensorflow
CPU only
https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.8.0-cp36-cp36m-linux_x86_64.whl
GPU support
https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.8.0-cp36-cp36m-linux_x86_64.whl
安裝nltk的方式是在terminal type [4]
conda install -c anaconda nltk
Download MovieQA dataset
到MovieQA官網申請帳號跟使用許可
download MovieQA_benchmark repo.
download MovieQA source data
Run QACNN
Download QACNN repository [0]
put data given by MovieQA into raw_data folder (
qa.jsonandsplit_plot/*.split.wiki)Download GloVe word2vec and put it into word_vec folder
run
plot2vec.py, (requireraw_data/plot/*.split.wikiandword_vec/glove.42B.300d.json), it generateregister.jsonandoutput_data/plot/xxxx.wiki.json', Figure 16GB memory required
run
qa2vec.py(requireword_vec/register.json,raw_data/question/qa.jsonandword_vec/glove.42B.300d.json), outputoutput_data/question/qa.train.json,output_data/question/qa.val.json
andoutput_data/question/qa.test.json, 16GB memory required
run
main.py(20GB memory required)
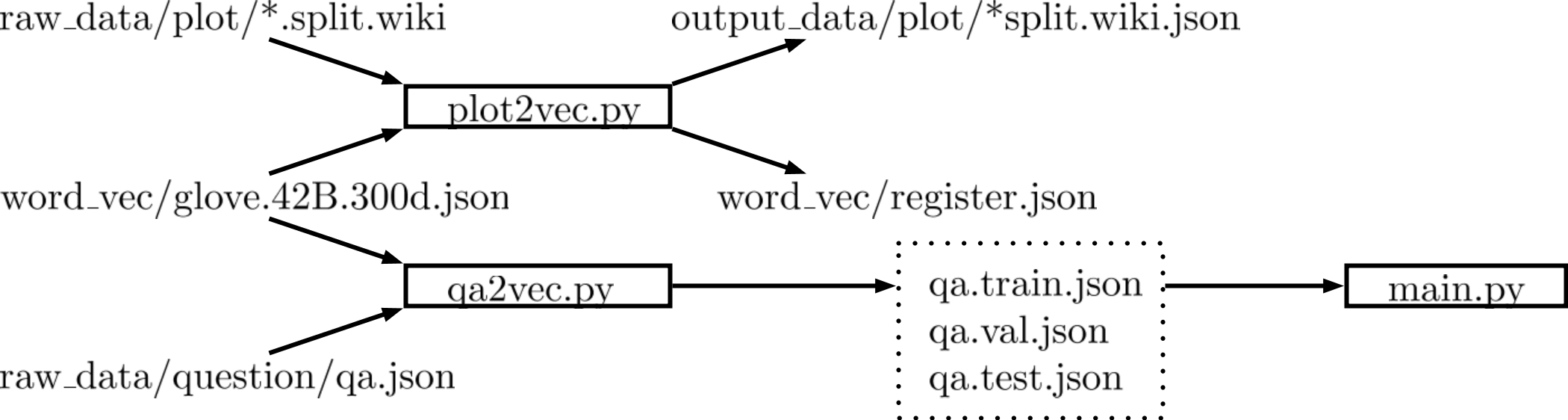
Figure 2: Flowchart of preprocess stage
Figure 2 顯示出在執行plot2vec.py跟qa2vec.py時,所需要input data跟它們output data。
plot2vec.py 需要的資料是raw data/plot/*.splitwiki, word vec/glove.42B.300d.json.
qa2vec.py 需要的資料是 word vec/glove.42B.300d, raw data/question/qa.json。
Ubuntu Linux instead of MacOSX
原本我們打算直接在MacOSX上直接執行QACNN,不過在執行plot2vec.py遇到json.load()載入word_vec/glove.42B.300d.json遇到如Figure 1所示的OSError: [Errno 22] Invalid argument,google之後知道這個是OSX作業系統本身的問題[1],所以我們轉換到Ubuntu Linux平台來執行QACNN。
值得注意的是,在MacOSX開Virtual Machine來跑Ubuntu Linux,可以跑原生的Linux所有的操作。
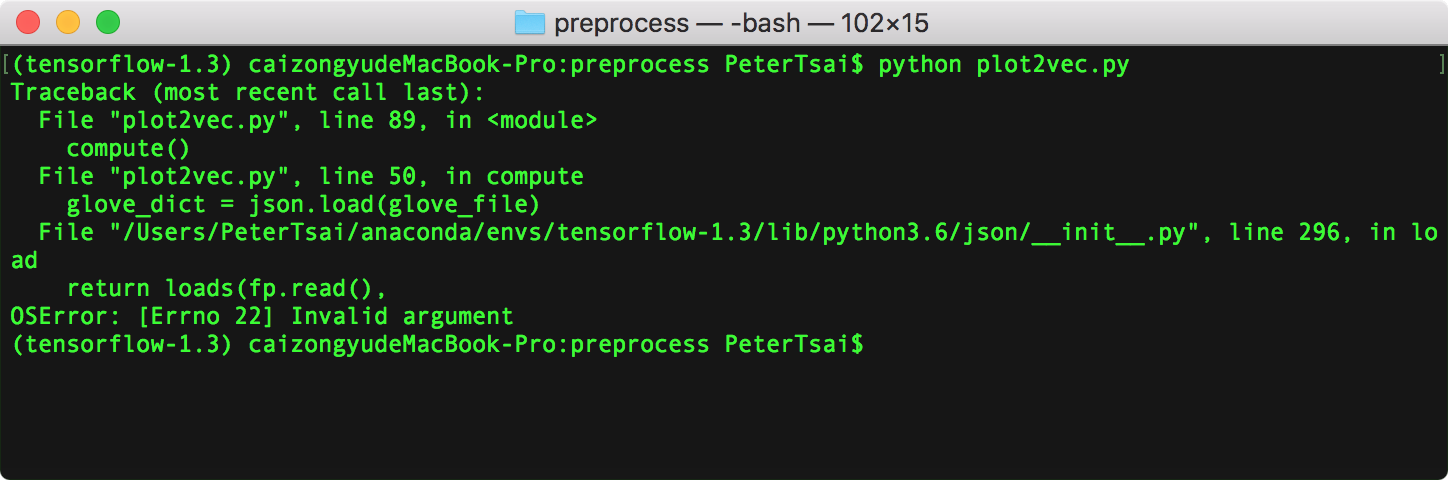
Figure 1: QACNN on MacOSX suffers from json.load() bug
[0]
https://github.com/chun5212021202/QACNN
[1]
https://stackoverflow.com/questions/41315394/file-size-limit-for-read
[2]
http://continuum.io/downloads
[3]
https://www.tensorflow.org/install/install_linux#the_url_of_the_tensorflow_python_package