Text-domain Sentence Boundary Detection
Choice中文語音Sentence Boundary Detection

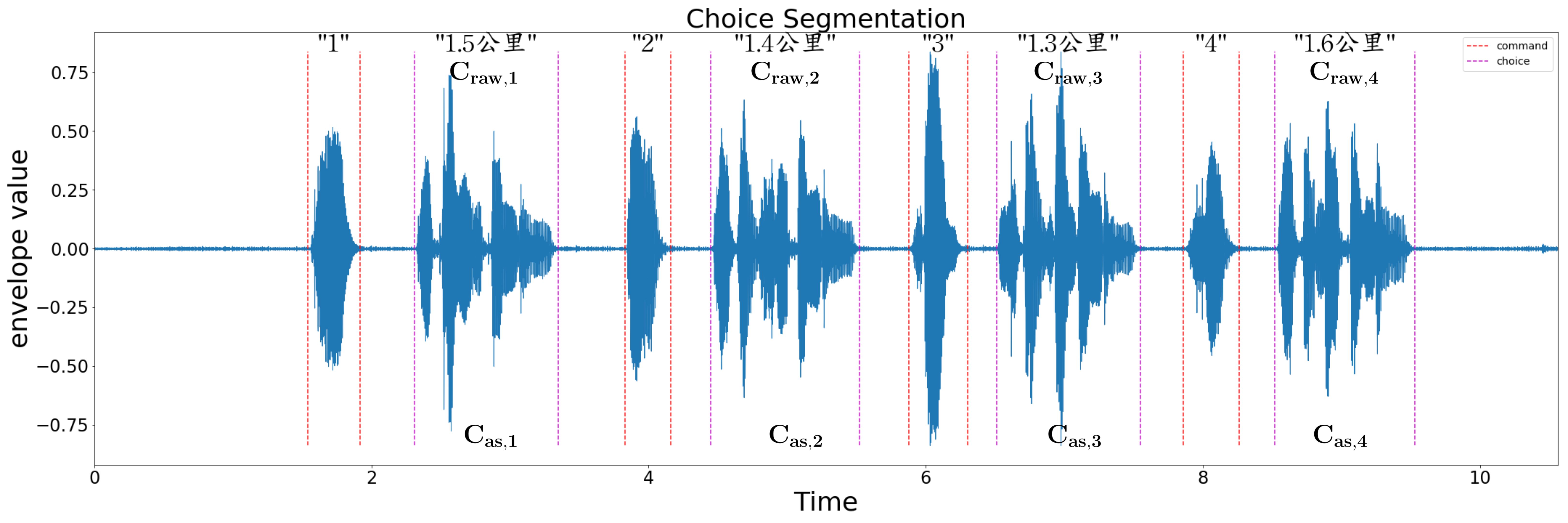 Fig. 1 Schematic of Choice 中文語音Sentence Segmentation.
Fig. 1 Schematic of Choice 中文語音Sentence Segmentation.
Figure 1 呈現Choice中文語音Sentence Boundary Detection,是choice acoustic signal (.wav檔), 是選項1的辨識字串(string),是選項2,3,4的辨識字串。
Flowchart of Text-domain Sentence Boundary Detection Algorithm
 Fig. 2 Flowchart of Text-domain Sentence Boundary Detection Algorithm
Fig. 2 Flowchart of Text-domain Sentence Boundary Detection Algorithm
Figure 2呈現在text-domain上做選項中文語音sentence boundary detection的流程圖。
將acoustic signal (聲音訊號)通過band-pass filter後,使用google cloud speech-to-text service把整段選項(choice)的音頻轉換成文字。
再用"1","2","3","4"關鍵字(keyword)在整段文字中檢索出"1","2","3","4"的時間位置(timestamp)。
便可把音頻分開產生choice 1 Audio、choice 2 Audio、choice 3 Audio、choice 4 Audio。
最後把這些分割好的音頻再丟入`google cloud speech-to-text service 裡面,輸出更精確的結果。
Transcribe Entire Acoustic Signal into Characters
![]() Fig. 3 Transcribe entire acoustic signal into characters
Fig. 3 Transcribe entire acoustic signal into characters
Fig. 3呈現Transcribe_file_with_word_offset.py把整段音頻透過google cloud speech-to-text service轉譯成有時間資訊文字的流程。
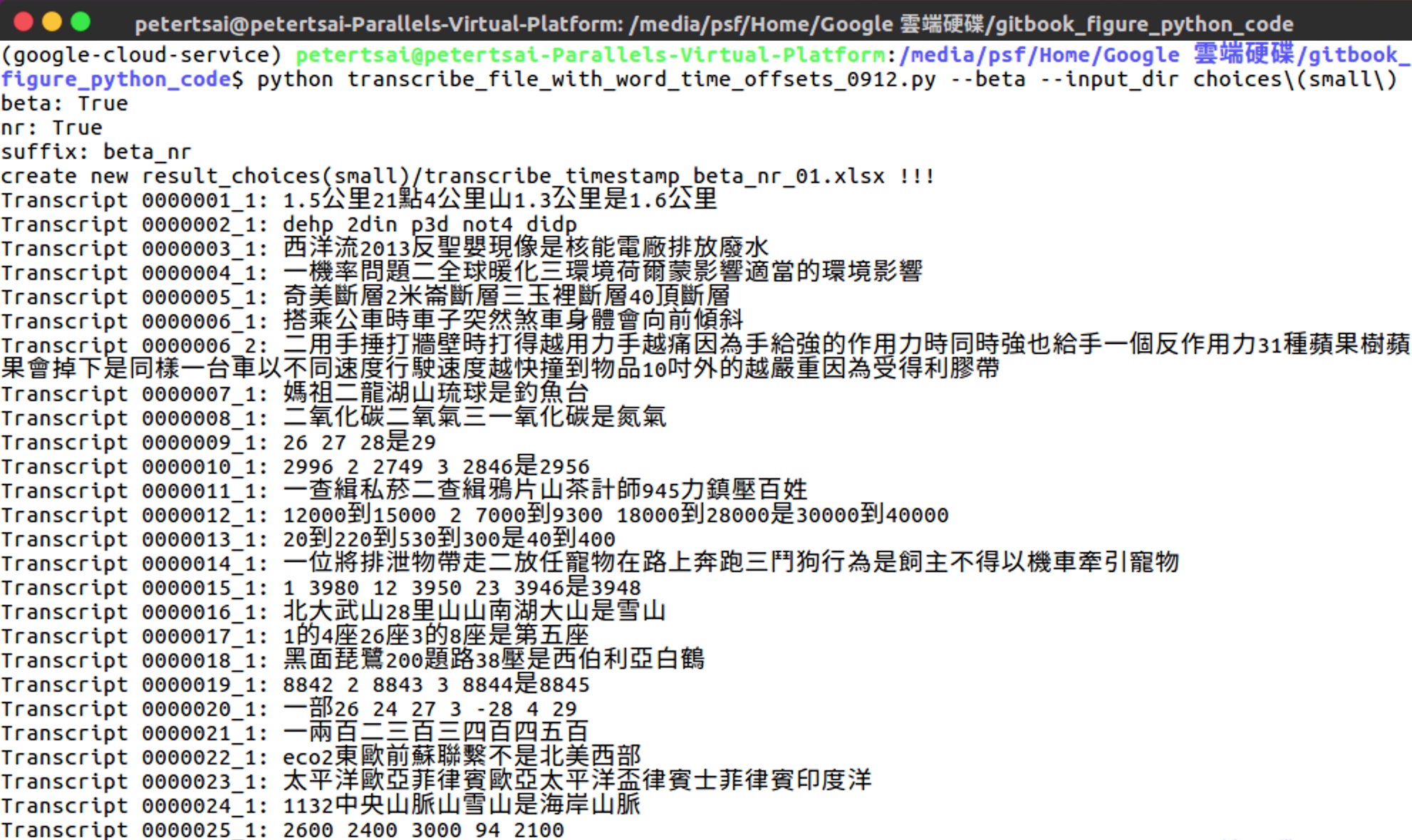 Fig. 4 在命令列上執行python file來使用google speech-to-text
Fig. 4 在命令列上執行python file來使用google speech-to-text
Fig. 4呈現在命令列打 "python transcribe_file_with_word_offset.py --beta_idx 1-2 --input_dir choices (small)" 與螢幕輸出。
--beta\_idx與--input\_dir是transcribe\_file\_with\_word\_offset.py的輸入參數。
transcribe_file_with_word_time_offest.py將使用google cloud speech-to-text api把指定資料夾中所有語音檔(.wav)轉譯成文字。
transcribe\_file\_with\_word\_offset.py 將產生 Transcript 00000001_1, Transcript 00000002_1, ...。
一個音檔就對應一段或多段transcript(字串)。
Transcript 00000001_1是第一個音檔的一段辨識字串。 第一個音檔也就是第一題的選項音檔。 第一個音檔google speech辨識的結果是"1.5公里21點4公里山1.3公里是1.6公里"。 第一個音檔人類辨識的結果是"一1.5公里 二1.4公里 三1.3公里 四1.6公里"。
Transcript 00000002_1是第二個音檔的一段辨識字串。
Transcript 00000006_1與Transcript 00000006_2是第六個音檔辨識出來的兩段字串。 我們猜測被拆成兩個字串的原因是因為選項1跟選項2中間有超過1秒的間隔,所以第六個音檔被拆成兩段。
Transcript 00000006_1 其實是選項1的字串 Transcript 00000006_2 其實是選項2到4的字串
![]() Fig.5
Fig.5 C0000001.wav 的Google transcription result
考慮一個音頻C0000001.wav,Fig. 5呈現Google trascription result: 1.5公里21點4公里山1.3公里是1.6公里。
此結果有三個瑕疵:
1 "一"跟1.5的"1"被合併在一起
2 "三"被誤辨識成"山",其中“三”羅馬拼音為san(不捲舌),"山"羅馬拼音為shan(捲舌)。
3 "四"被誤辨識成"是",其中“四”羅馬拼音為si,“是”羅馬拼音為shi(捲舌)。
由以上的三個瑕疵觀察,我們推斷僅使用google cloud speech-to-text service(把整個choice acoustic signal轉譯成繁體中文),沒有辦法做到Choice中文語音Sentence Boundary Detection。
辨識結果的存檔
 Fig. 6 transcription資料夾的檔案
。
Fig. 6 transcription資料夾的檔案
。
一批次將被設定為25個音檔 (note 可自行改動大小)
Fig. 6呈現google speech recognition 辨識完的transcription檔案。
Fig. 6(藍)呈現輸出的資料夾,命名方式為result_+<輸入音頻資料夾名稱>。
Fig. 6(紅)transribe_output_beta.csv是辨識結果的總表,存所有音頻辨識的結果,但是辨識結果不包含時間資訊。
Fig. 6(綠)是包含時間資訊的批次辨識檔
transcribe\_timestamp\_beta\_01.xlsx是第一批次音檔的辨識字串。
一批次包含25個音檔。
transcribe\_timestamp\_beta\_02.xlsx是第二批次音檔的辨識字串。
批次檔的結構在Fig. 8有詳細解釋。
辨識總表
![]() Figure 7
Figure 7 transcribe_output_beta.csv 裡面的內容格式
Fig.7呈現transcribe_output_beta.csv的內容格式,裡頭紀錄著所有音檔(C0000001.wav, C0000002.wav, ...)的辨識字串。
Fig.7(紅)代表第個檔案,python計數從0開始。
通常一個音檔對應一個transcript,如Fig.7(藍)所示。
一個音檔如果有多段transcript,多個字串會被合成一格cell,如第六題音檔的兩個辨識字串,已被整合成一個cell,如Fig.7(綠)。
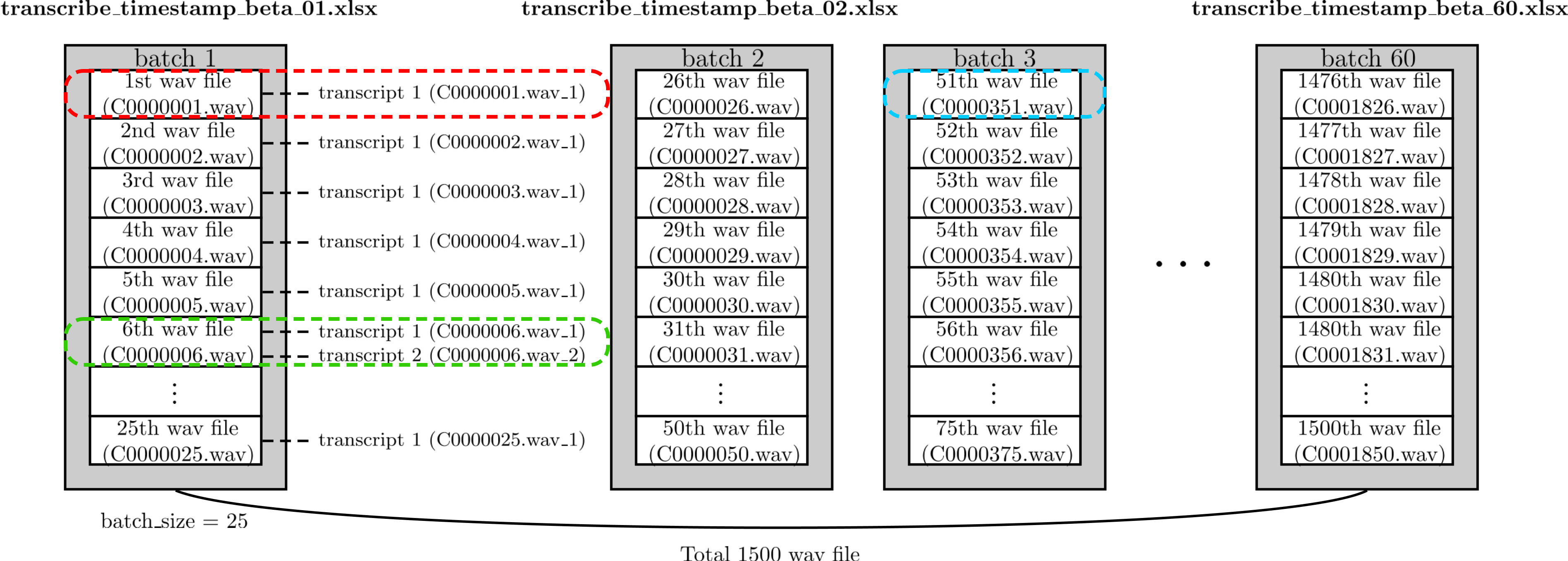 Fig. 8 Batch Operation of
Fig. 8 Batch Operation of Transcribe_file_with_word_offset.py
Fig.8呈現Transcribe_file_with_word_offset.py 批次處理的方式。
每個batch包含25個音頻檔。第一個batch對應檔案transcribe_timestamp_beta_01.xlsx,第二個batch對應檔案transcribe_timestamp_beta_02.xlsx,以此類推。
每個音頻檔會有一個[Fig.8(紅)]或多個[Fig.8(綠)]辨識結果。
第個檔案未必是第題,如Fig.8(藍)所示,第51個檔案是第351題,原因為kaggle官方在資料庫沒有提供第51~350題。
每個batch具有時間訊息的xlsx檔
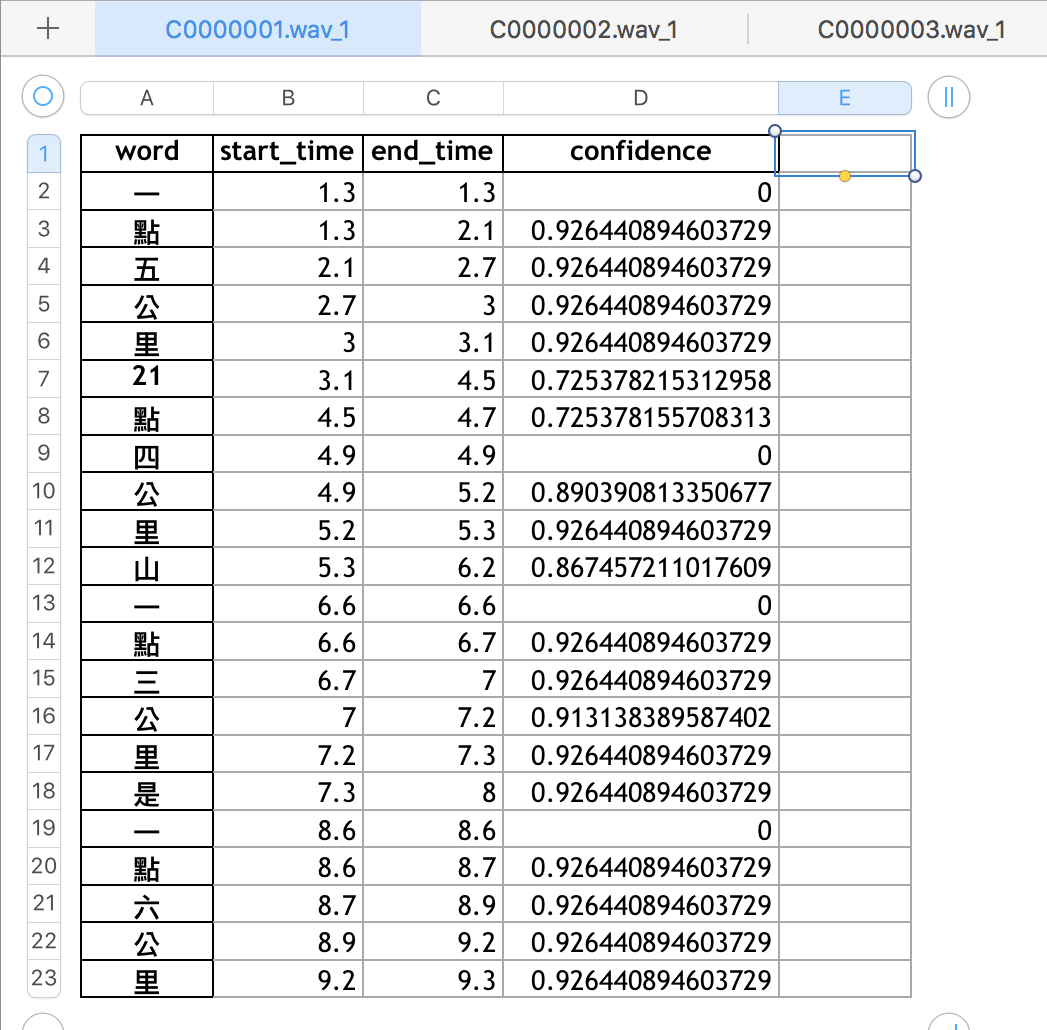 Fig. 9
Fig. 9 transcribe_timestamp_beta_01.xlsx裡面的內容格式
Fig.9呈現 transcribe_timestamp_beta_01.xlsx的內容格式。
一個transcript存在一個頁面(sheet)。
每個頁面裡word欄是辨識出來的文字,start time與end_time指該個字的起始與結束時間(單位:秒),confidence是其信心值。
以第一個音頻檔為例,"一"的起始時間是1.3秒,結束時間是1.3秒,信心值為0。
"點"的起始時間是1.3秒,結束時間是2.1秒,信心值為0.926440894603729。
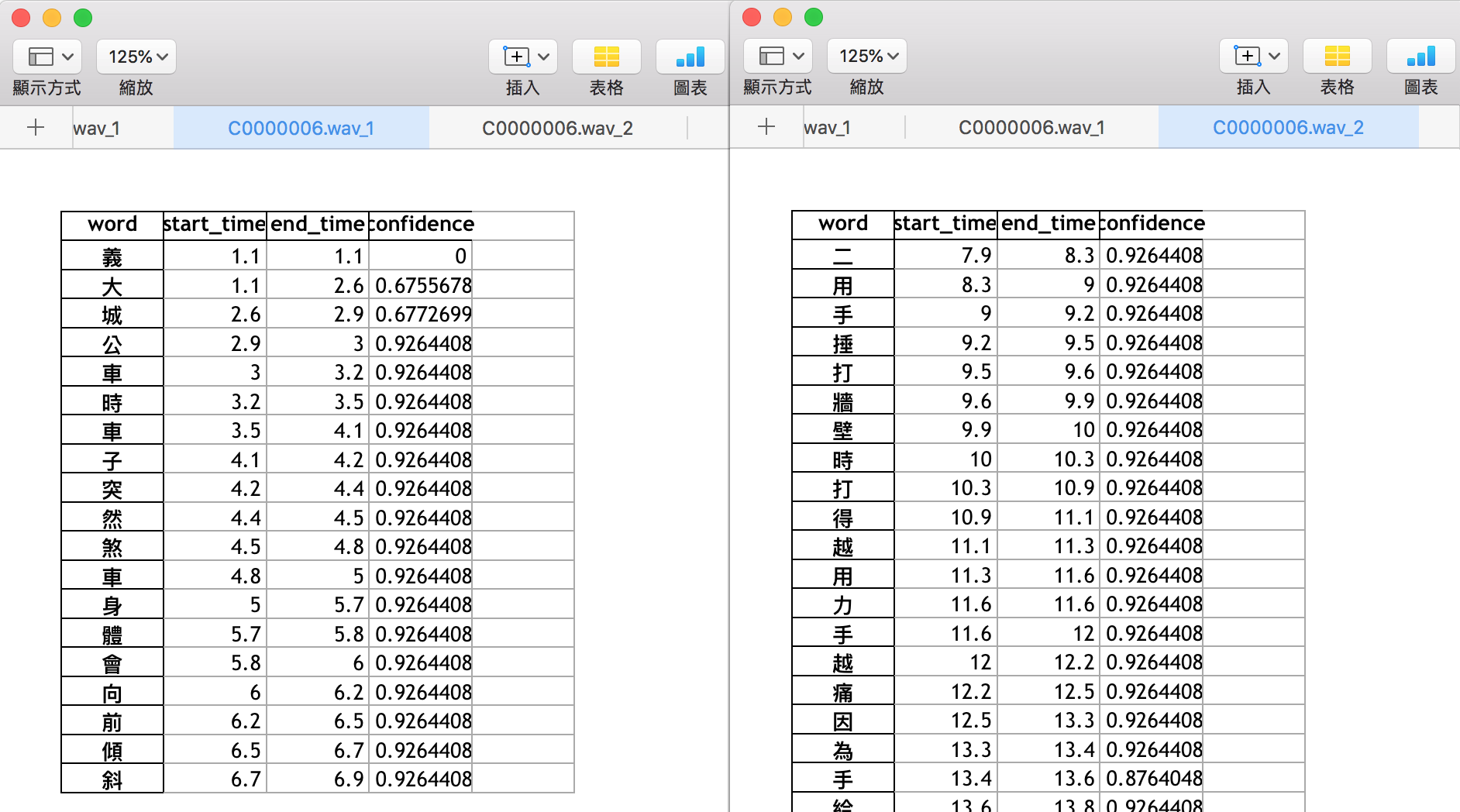 Fig.10 當audio phoneme之間的間隔超過1s,google api會自動把audio分段(下半段)
Fig.10 當audio phoneme之間的間隔超過1s,google api會自動把audio分段(下半段)
Fig.10呈現一個音頻(C0000006.wav)產生兩個辨識檔(C0000006.wav_1,C0000006.wav_2),存在兩個xlsx頁面。Fig. 10左半為第一個分段(選項1)"義大城公車時車子突然煞車身體會向前傾斜",Fig. 10右半為第二個分段(選項2,選項3,選項4)"二用手捶打牆壁時打得越用力手越痛因為手..."。我們判斷是分段的規則當audio phoneme之間的間隔超過1s,google api會自動把audio分段。
圖5要合在一起
實驗結果與問題討論
目前會遇到的問題有
- 長句子精確度下降
- "1","2","3","4" 同音異字or merge問題。
為了解決這個問題,可能會有幾種替代的做法 alternative 1: 先分割成一個一個選項再丟辨識 alternative 2: 把acoustic model轉譯成羅馬拼音或英文,從拼音space來抓“一”、“二”、“三”、“四“。