initialize parameters
Initialize parameters is the "Similarity Mapping Layer" part of QACNN model.
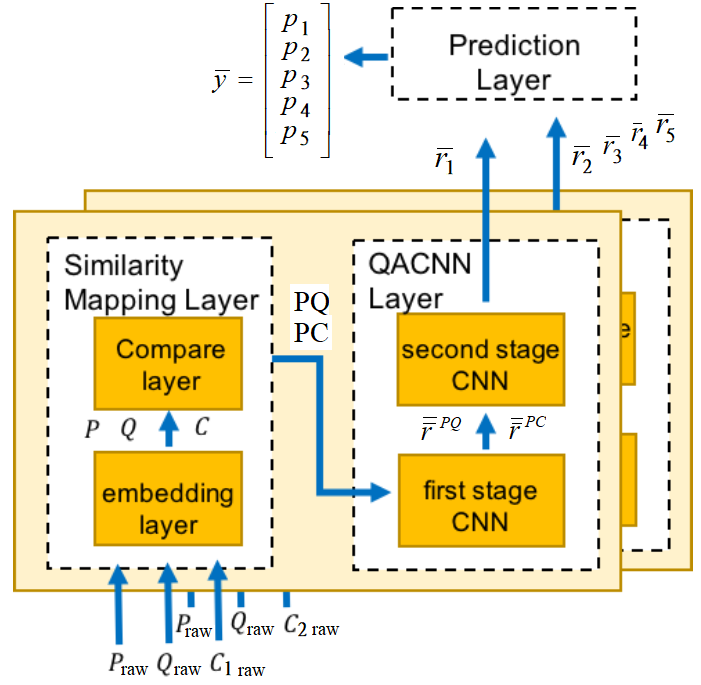
Fig.1 Overall data flow of QACNN model
# initialize parameter分成兩個部分,第一部分是12~35行, 將建構 "embedding layer",第二部分是38~48行, 將建構 "Compare layer"。
The embedding layer transform , ,
into word embedding , , and .
The compare layer generates paragraph-query similarity map and paragraph-choice similarity map .
# initialize parameter
Given a paragraph (with sentences), a query , and a choice , the embedding layer transforms every words in , and into word embedding, whose length is x_dimension.
is the total number of sentence in paragraph, and is the total number of words in each sentence.
Query is considered as one sentence.
is the total number of words in query sentence.
choice is considered as one sentence.
is the total number of words in choice sentence.
The sentences in all the paragraphs have the same length by padding.
, and are word embeddings.
The compare layer compares each paragraph sentence to and at word level separately.
__init__() 函數中, # initialize parameters # 第一部分為以下 12~35 行 :
12 def __init__(self,batch_size,x_dimension,dnn_width,cnn_filterSize,cnn_filterSize2,cnn_filterNum,cnn_filterNum2 ,learning_rate,dropoutRate,choice,max_plot_len,max_len,parameterPath):
13 self.parameterPath = parameterPath
14 self.p = tf.placeholder(shape=(batch_size,max_plot_len,max_len[0],x_dimension), dtype=tf.float32) ##(batch_size,p_sentence_num,p_sentence_length,x_dimension)
15 self.q = tf.placeholder(shape=(batch_size,max_len[1],x_dimension), dtype=tf.float32) ##(batch_size,q_sentence_length,x_dimension)
16 self.ans = tf.placeholder(shape=(batch_size*choice,max_len[2],x_dimension), dtype=tf.float32) ##(batch_size*5,ans_sentence_length,x_dimension)
17 self.y_hat = tf.placeholder(shape=(batch_size,choice), dtype=tf.float32) ##(batch_size,5)
18 self.dropoutRate = tf.placeholder(tf.float32)
19 self.filter_size = cnn_filterSize
20 self.filter_size2 = cnn_filterSize2
21 self.filter_num = cnn_filterNum
22 self.filter_num2 = cnn_filterNum2
23 choose_sentence_num = max_plot_len
24
25
26 normal_p = tf.nn.l2_normalize(self.p,3)
27 ## (batch_size,max_plot_len*max_len[0],x_dimension)
28 normal_p = tf.reshape(normal_p,[batch_size,max_plot_len*max_len[0],x_dimension])
29
30 ## (batch_size,max_len[1],x_dimension)
31 normal_q = tf.reshape(tf.nn.l2_normalize(self.q,2),[batch_size,max_len[1],x_dimension])
32
33 normal_ans = tf.nn.l2_normalize(self.ans,2)
34 ## (batch_size,choice*max_len[2],x_dimension)
35 normal_ans = tf.reshape(normal_ans,[batch_size,choice*max_len[2],x_dimension])
13,14行 定義 (paragraph)
13 self.parameterPath = parameterPath
14 self.p = tf.placeholder(shape=(batch_size,max_plot_len,max_len[0],x_dimension), dtype=tf.float32) ##(batch_size,p_sentence_num,p_sentence_length,x_dimension)
13 行的 parameter 將在 /main.py 被assign (程式中不會使用)。
14 行將定義一個tensor self.p, ,它就是 (paragraph)。
其中,max_plot_len 是 (number of sentence in paragraph);
max_len[0] 是 (number of word in a sentence)。
batch size 指的是一個 batch 的 size。
x_dimension 指的是 word vector 的長度。
所以, 可以寫成。
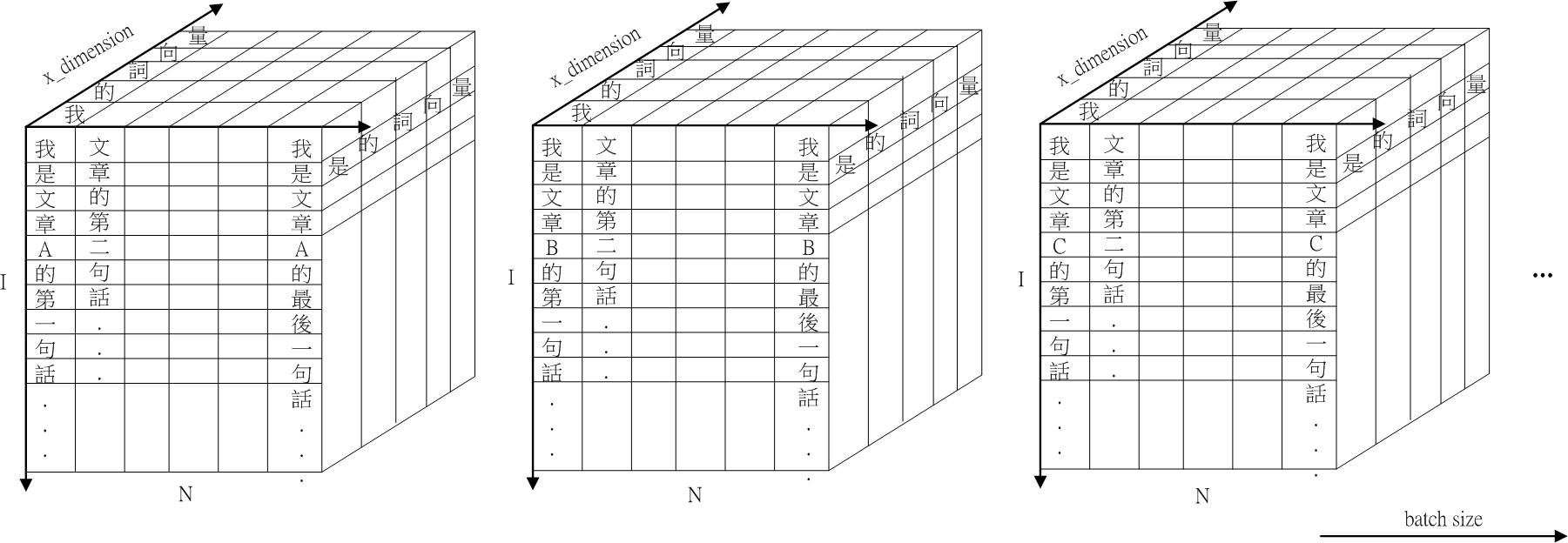 Fig.2 self.p 示意圖。
Fig.2 self.p 示意圖。
Fig.2 呈現 self.p () 的示意圖。self.p 有四個維度:batch size, sentence num (), sentence length (), x_dimension。
假設 paragraph 為N 句話: "我是文章的第一句話...,文章的第二句話...,..., 我是文章的第N句話" 。
每一句話的長度皆為 I。
x_dimension 是 word vector 的長度。
batch_size 是批次的 size。
26行 L2 normalization正規化
26 normal_p = tf.nn.l2_normalize(self.p,3)
26 行將 self.p 的第四個維度 (note 維度從 0 計算,3 則是第四個維度),x_dimension 維度做 L2 正規化,結果存入 normal_p。
L2 正規化 (L2 normalization,簡稱 L2 norm) 的輸入與輸出都是一個 vector (一維陣列)。
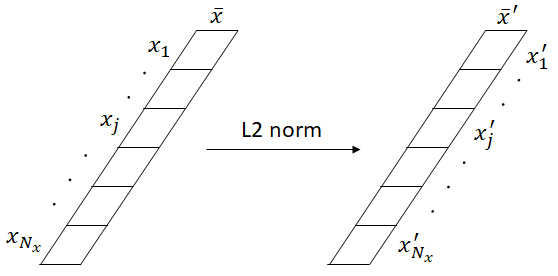
Fig.3 L2 norm 示意圖
Fig.3 為 L2 norm 示意圖。輸入和輸出皆是向量,計算對應的 element
假定一個 vector ,其中 是 的 element 個數,則 的 L2 正規化的計算式可表示為:
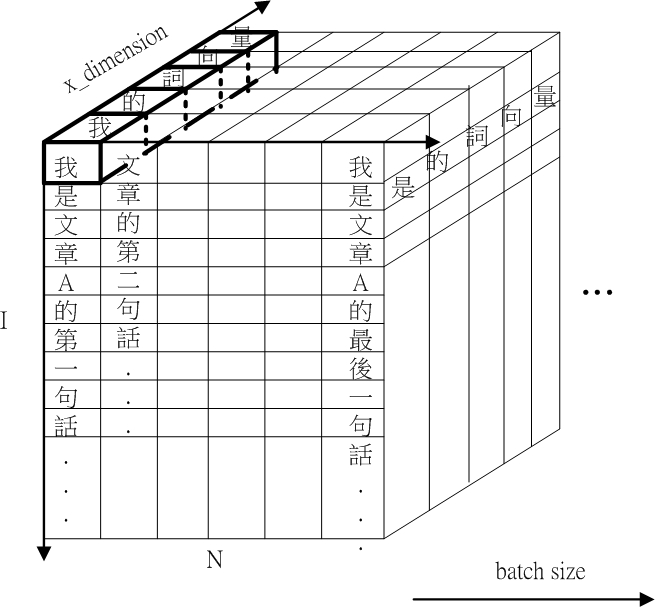
Fig.4 self.p 以 x_dimension 維度計算 L2 norm 的示意圖
Fig.4 呈現self.p () 以 x_dimension 維度做 L2 正規化的示意圖。self.p () 的每個字向量都進行 L2 norm 計算
27, 28行 Reshape 轉換tensor 形狀
27 ## (batch_size,max_plot_len*max_len[0],x_dimension)
28 normal_p = tf.reshape(normal_p,[batch_size,max_plot_len*max_len[0],x_dimension])
28 行將 (四維,) reshape 成三維
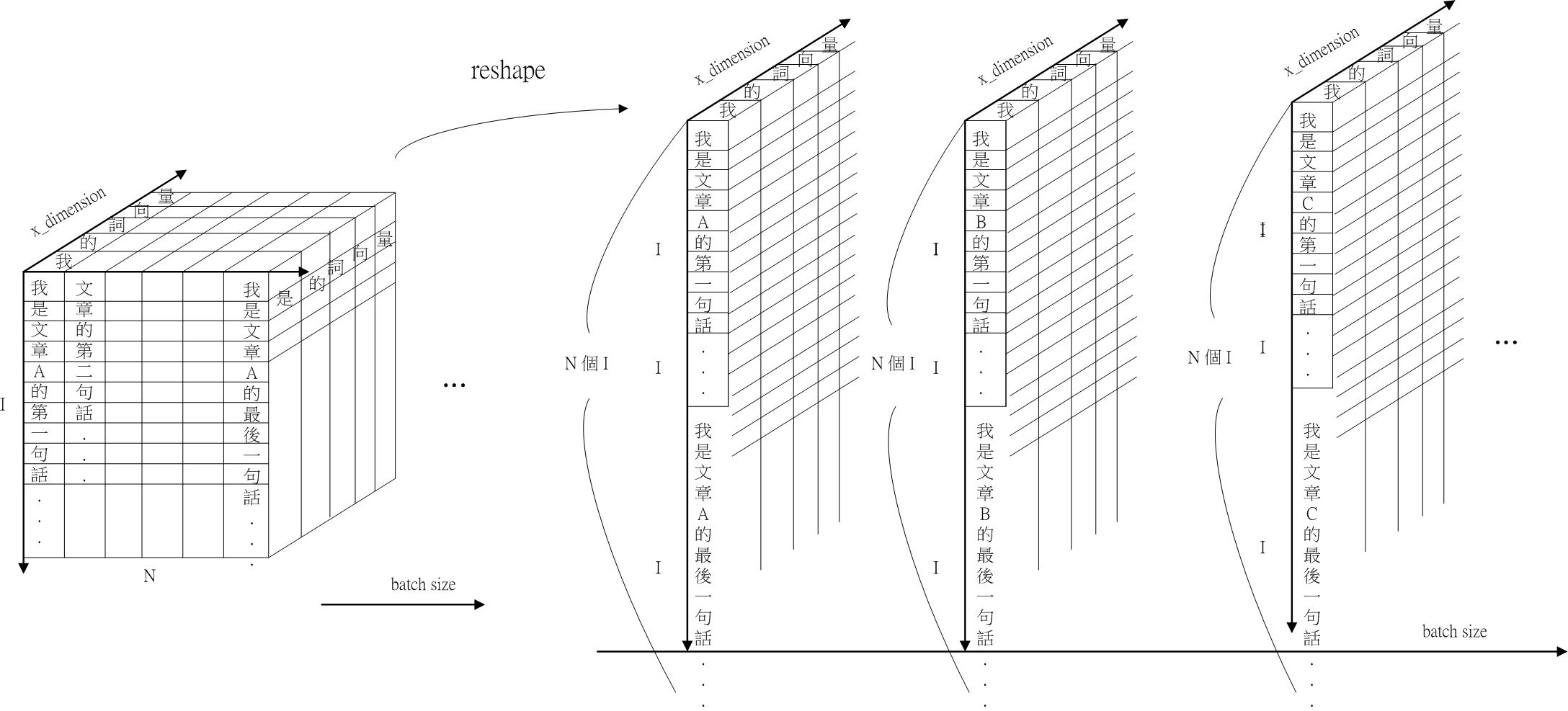 Fig.5 schematic of normal p reshape。
Fig.5 schematic of normal p reshape。
fig.5 呈現 normal_p 的示意圖。normal_p reshape 後,N 的 dimension 消失,I 的 dimension 增為
15 行 定義 (Query)
15 self.q = tf.placeholder(shape=(batch_size,max_len[1],x_dimension), dtype=tf.float32) ##(batch_size,q_sentence_length,x_dimension)
15 行將定義一個 tensor self.q,它指的是論文的 (query)
。
其中 max_len[1] () is number of word in a query sentence
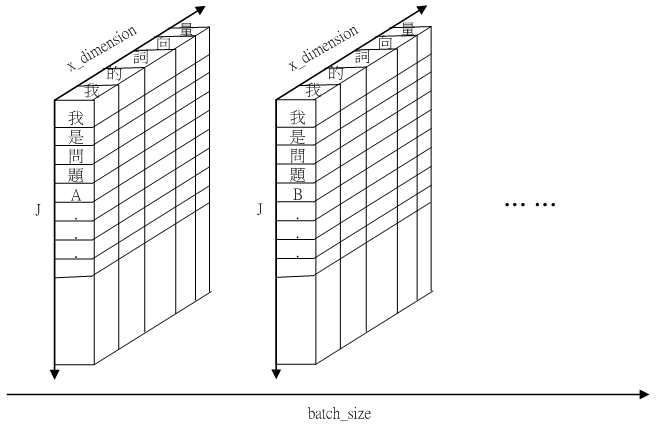
Fig.6 Schematic of self.q
Fig.6 呈現 self.q 的示意圖。self.q 有三個維度:batch size, word number in sentence ( ), x_dimension。
30 ## (batch_size,max_len[1],x_dimension)
31 normal_q = tf.reshape(tf.nn.l2_normalize(self.q,2),[batch_size,max_len[1],x_dimension])
31 行將 self.q 的第三個維度 (維度從 0 計算,2 則是第三個維度),x_dimension 維度做 L2 正規化,再 reshape 後存入 normal_q。
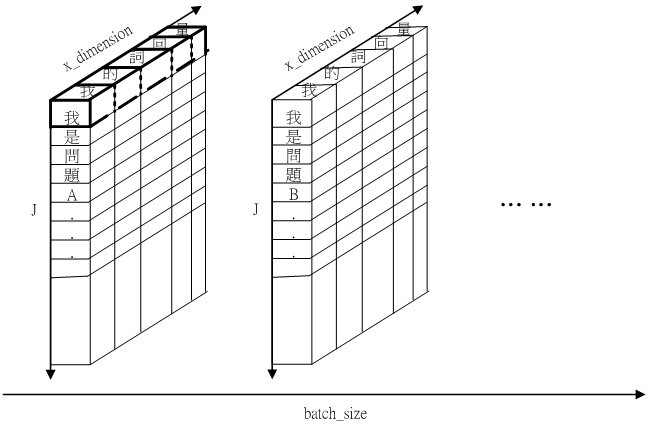
Fig.7 self.q 以 x_dimension 維度計算 L2 norm 的示意圖
Fig.7 呈現self.q 以 x_dimension 維度計算 L2 norm 的示意圖,圖中將
"我"的詞向量(word vector)做L2 norm。
16 行 定義 choices
16 self.ans = tf.placeholder(shape=(batch_size*choice,max_len[2],x_dimension), dtype=tf.float32) ##(batch_size*5,ans_sentence_length,x_dimension)
16 行將定義一個 tensor self.ans, ,它就是 (choice)。
其中,choice 在 main.py 程式中第16行被設定是 5 (number of choices);
max_len[2] 是 (number of word in a choice)。
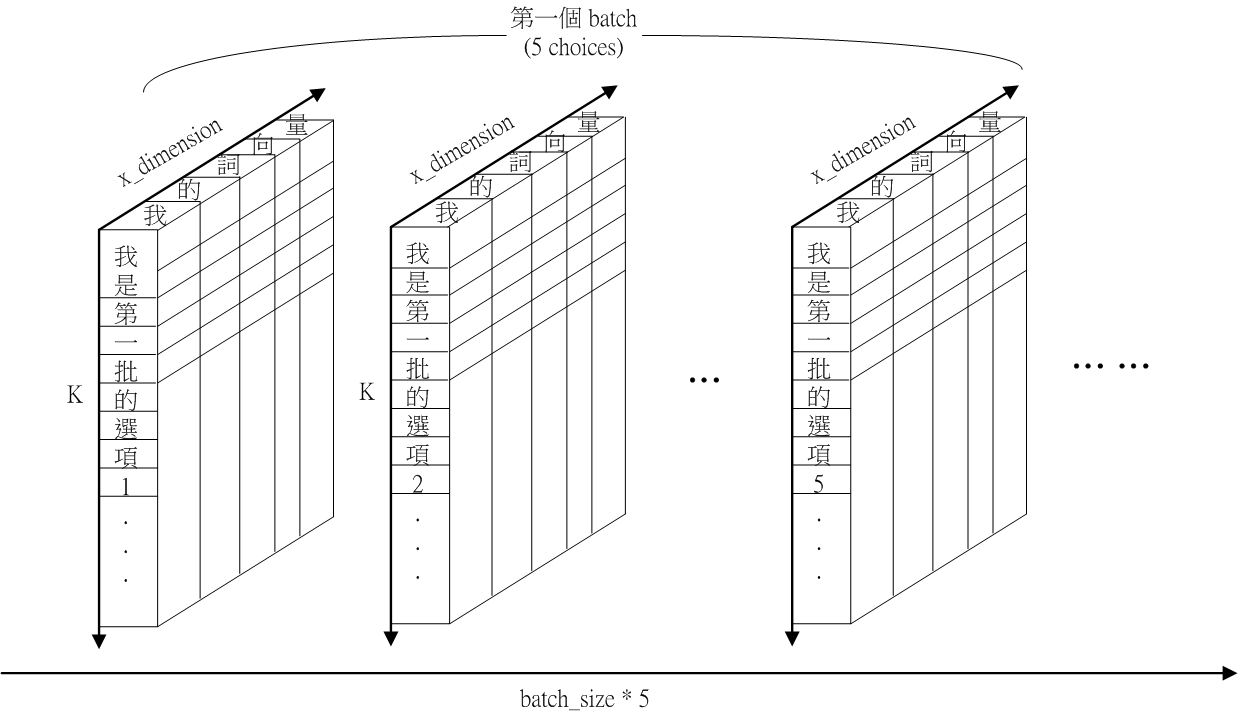
Fig.8 Schematic of self.ans
Fig.8 呈現 self.ans 的示意圖。self.ans 有三個維度:batch size x 5, word number in sentence ( ), x_dimension。
33 normal_ans = tf.nn.l2_normalize(self.ans,2)
33 行將 self.ans 的第三個維度 (維度從 0 計算,2 是第三個維度),x_dimension 維度做 L2 正規化,再 reshape 後存入 normal_ans。
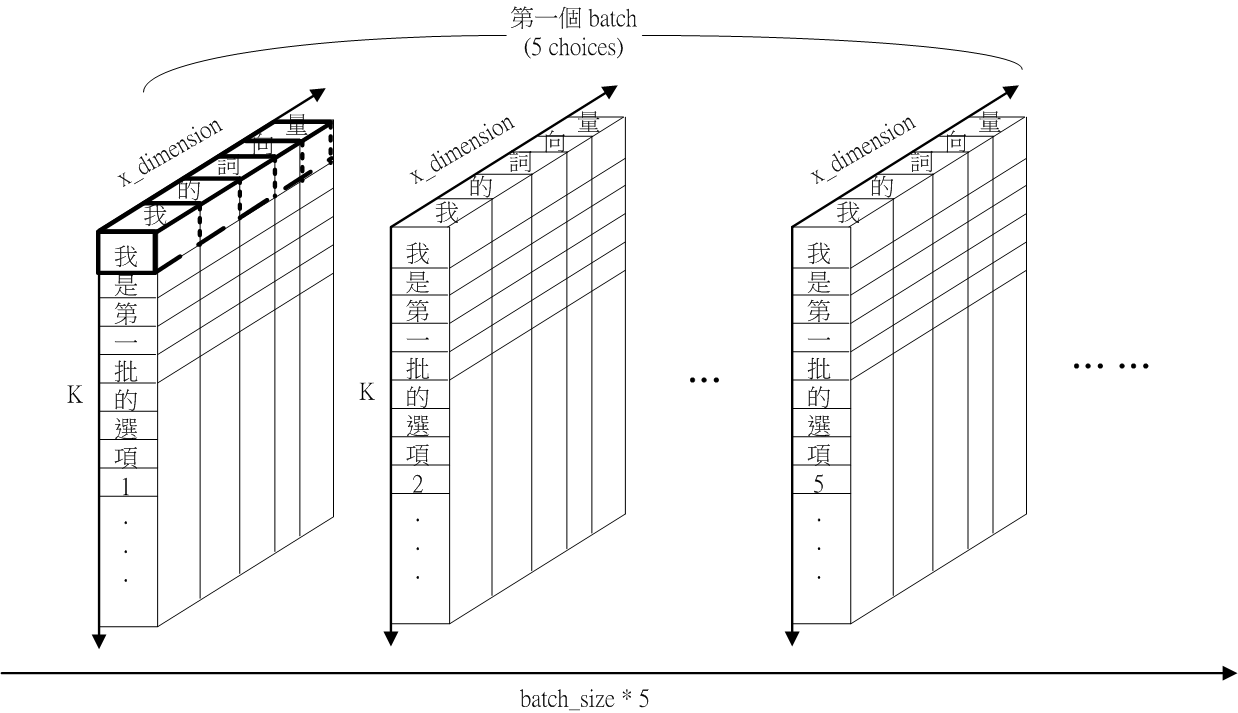
Fig.9 self.ans 以 x_dimension 維度計算 L2 norm 的示意圖
Fig.9 呈現self.ans 以 x_dimension 維度做 L2 正規化。
34 ## (batch_size,choice*max_len[2],x_dimension)
35 normal_ans = tf.reshape(normal_ans,[batch_size,choice*max_len[2],x_dimension])
35 行將 normal_ans,, reshape 成
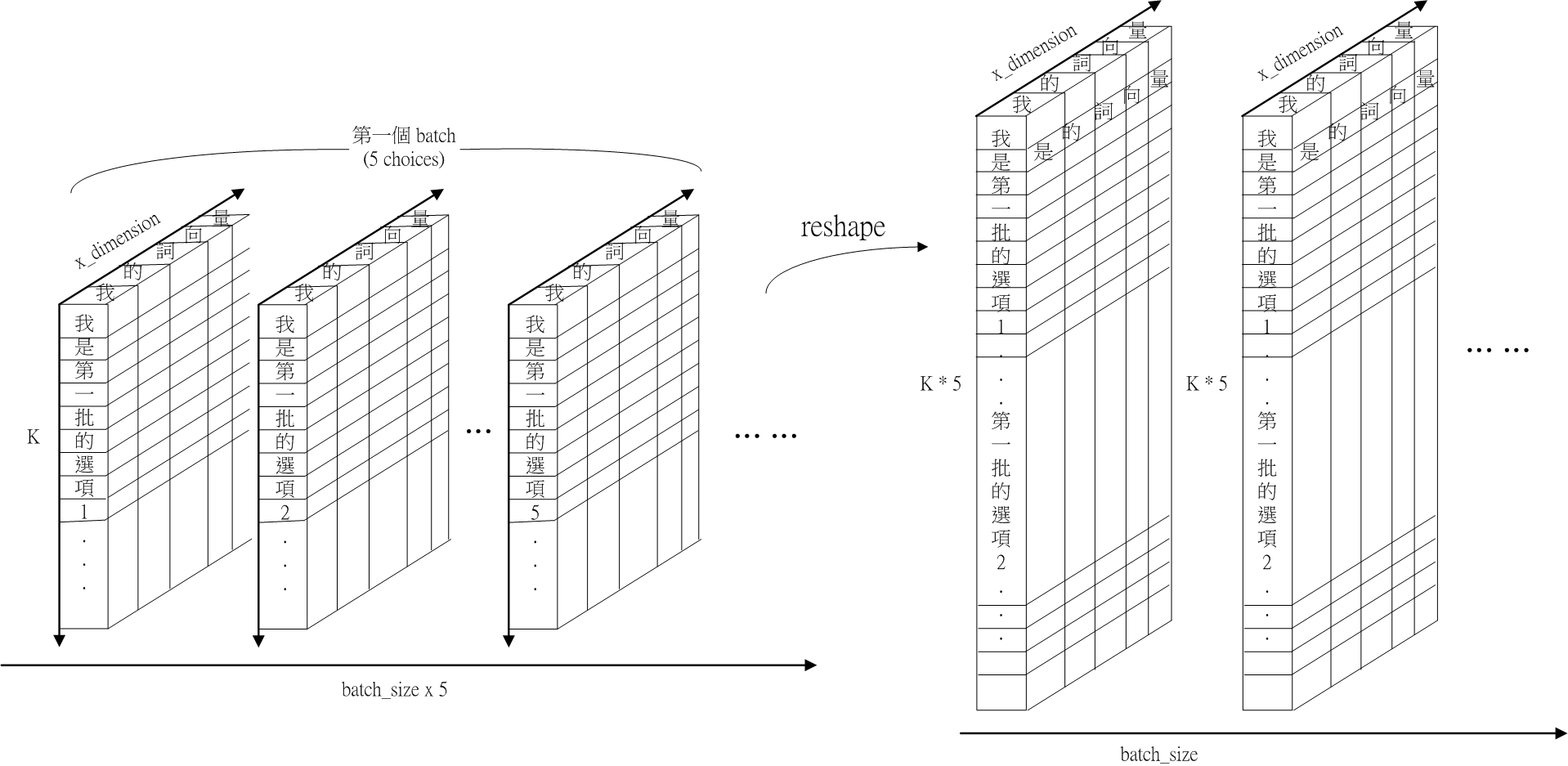
Fig.10 schematic of normal_ans after reshape。
fig.10 呈現 normal_ans 的示意圖。
17行 定義 label data
17 self.y_hat = tf.placeholder(shape=(batch_size,choice), dtype=tf.float32) ##(batch_size,5)
17 行將定義一個 tensor self.y_hat, ,它就是 (label data)。
choice = 5 (number of choices);
18行 定義 dropout rate
18 self.dropoutRate = tf.placeholder(tf.float32)
18 行將定義一個 tensor self.dropoutRate
tf.float32 指 self.dropoutRate 是一個浮點數
19~23行 assign parameters
19 self.filter_size = cnn_filterSize
20 self.filter_size2 = cnn_filterSize2
21 self.filter_num = cnn_filterNum
22 self.filter_num2 = cnn_filterNum2
23 choose_sentence_num = max_plot_len
19 行的 cnn_filterSize 是 width of kernel in CNN1 ().
cnn_filterSize 將在 /main.py 被 assign [1, 3, 5]。
20 行的 cnn_filterSize2 是 width of kernel in CNN2 ().
cnn_filterSize2 將在 /main.py 被 assign [1, 3, 5]。
21 行的 cnn_filterNum 是 number of kernel in CNN1 ().
cnn_filterNum 將在 /main.py 被 assign 128。
22 行的 cnn_filterNum2 是 number of kernel in CNN2 ().
cnn_filterNum2 將在 /main.py 被 assign 128。
23 行的 max_plot_len 是 number of sentence in paragraph
將在 /main.py 被 assign 101。
#initialize parameter# 第二部分,Compare layer

Fig.11 Compare Layer in QACNN model
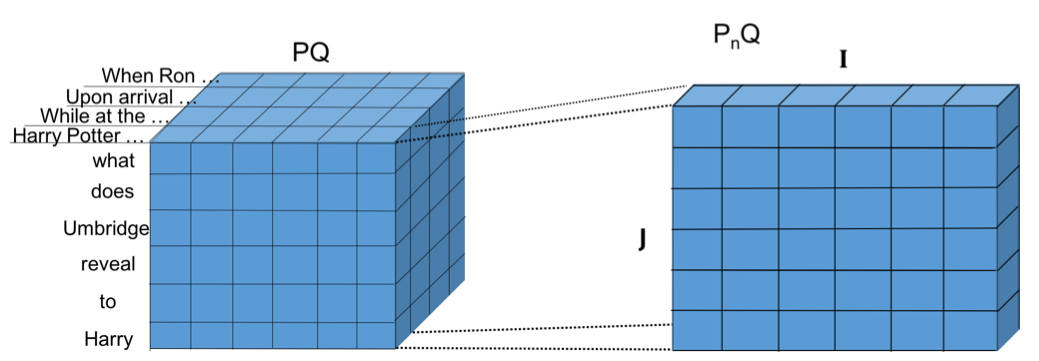 Fig.12 Compare layer map between paragraph and query . denotes the length of each sentence , denotes the length of query .
Fig.12 Compare layer map between paragraph and query . denotes the length of each sentence , denotes the length of query .
Fig.12 shows the similarity between paragraph and query . denotes the length of each sentence . denotes the length of query .
__init__() 函數中, # initialize parameters # 第二部分為以下 38~48 行 :
38 PQAttention = tf.matmul(normal_p,tf.transpose(normal_q,[0,2,1])) ##(batch,max_plot_len*max_len[0],max_len[1])
39 PAnsAttention = tf.matmul(normal_p,tf.transpose(normal_ans,[0,2,1])) ##(batch,max_plot_len*max_len[0],choice*max_len[2])
40 PAnsAttention = tf.reshape(PAnsAttention,[batch_size,max_plot_len*max_len[0],choice,max_len[2]]) ##(batch,max_plot_len*max_len[0],choice,max_len[2])
41 PAAttention,PBAttention,PCAttention,PDAttention,PEAttention = tf.unstack(PAnsAttention,axis = 2) ##[batch,max_plot_len*max_len[0],max_len[2]]
42
43 PQAttention = tf.unstack(tf.reshape(PQAttention,[batch_size,max_plot_len,max_len[0],max_len[1],1]),axis = 1) ##[batch,max_len[0],max_len[1],1]
44 PAAttention = tf.unstack(tf.reshape(PAAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
45 PBAttention = tf.unstack(tf.reshape(PBAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
46 PCAttention = tf.unstack(tf.reshape(PCAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
47 PDAttention = tf.unstack(tf.reshape(PDAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
48 PEAttention = tf.unstack(tf.reshape(PEAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
第38行、43行將計算 paragraph-query similarity map (PQAttention)
 fig.13 計算 paragraph-query similarity map (PQAttention) 的流程
fig.13 計算 paragraph-query similarity map (PQAttention) 的流程
fig.13 將執行PQ的計算
其中 PQAttention 是再加上 batch size 維度的
38行 矩陣轉置 (transpose ) 與矩陣相乘 (matmul)
38 PQAttention = tf.matmul(normal_p,tf.transpose(normal_q,[0,2,1])) ##(batch,max_plot_len*max_len[0],max_len[1])
第 38 行的概念是
其中 tf.transpose(normal_q, [0,2,1]),將 normal_q 的維度由 轉成。
![]()
Fig.14 normal_q transposation, tf.transpose(normal_q, [0,2,1])
Fig.14 shows normal_q transpose the axis 1 () and axis 2 (x_dimension).
normal_q 的維度轉置後變成 ;
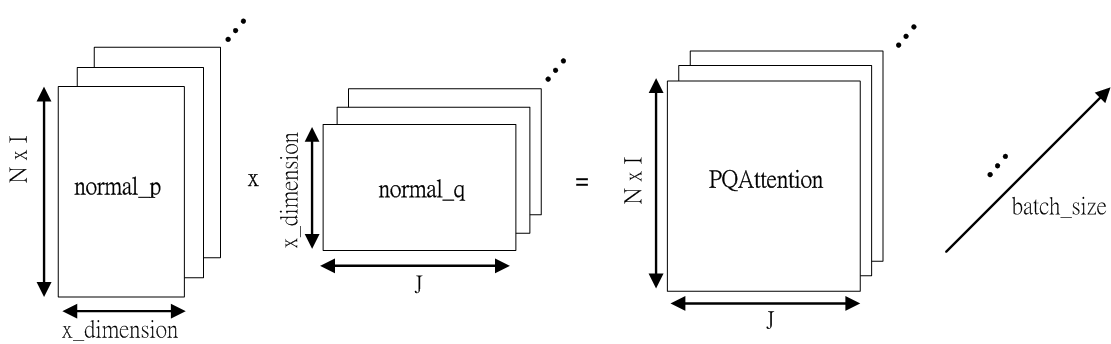 Fig.15 normal_p 與 normal_q 矩陣相乘示意圖
Fig.15 normal_p 與 normal_q 矩陣相乘示意圖
normal_p 的維度為 ;
normal_q 的維度為 ;
PQAttention 為 normal_p 與 normal_q 兩矩陣相乘,維度為
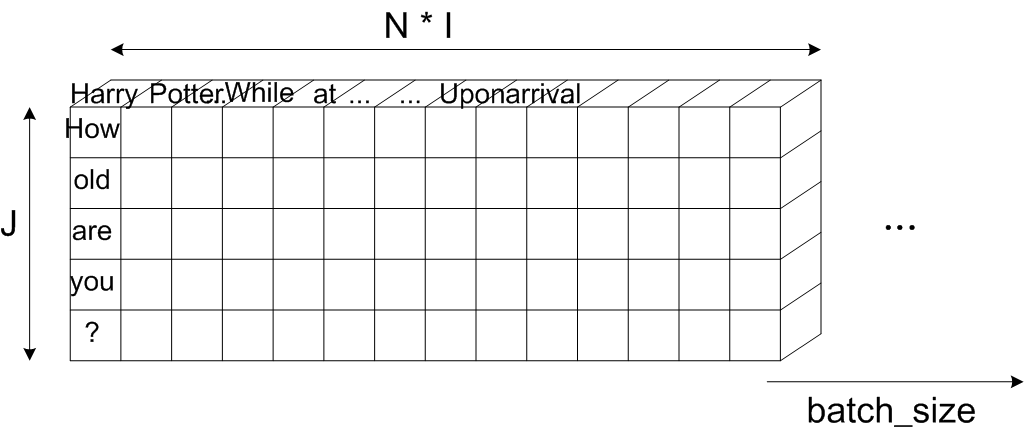
Fig.16 Schematic of PQAttention (multiplied by normal_p and normal_q)
Fig.16 shows the PQAttention after matmul by normal_p and normal_q. The shape of PQAttention is
圖中的第一個column與第一個raw的元素是Harry與how兩個字詞的內積。
圖中的第二個column與第一個raw的元素是Potter與how兩個字詞的內積。
圖中的第一個column與第二個raw的元素是Harry與old兩個字詞的內積。
43行 將PQAttention reshape 與 unstack
43 PQAttention = tf.unstack(tf.reshape(PQAttention,[batch_size,max_plot_len,max_len[0],max_len[1],1]),axis = 1) ##[batch,max_len[0],max_len[1],1]
第 43 行,將 PQAttention reshape 再 unstack。
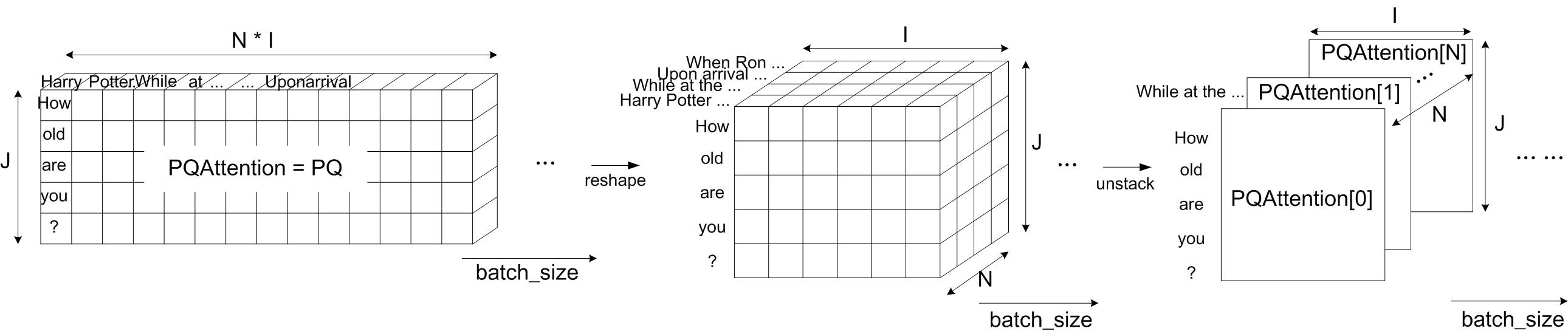
Fig.17 PQAttention shape transformation
Fig.17 呈現將 PQAttention reshape 與 unstack 的示意圖。
PQAttention reshape 後,維度由 變為 ,
PQAttention unstack 將 PQAttention 內部拆成 N 個矩陣,PQAttention[0] to PQAttention[N-1]。
PQAttention[0] 的維度為
39~40行 PAnsAttention computation
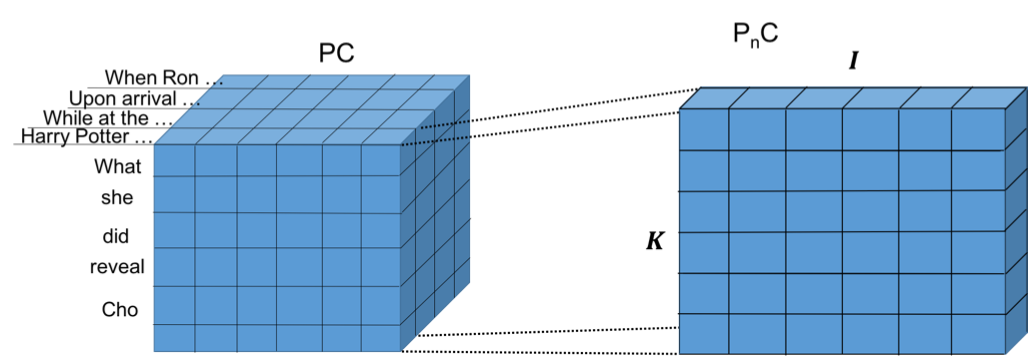
Fig.18 Similarity map between paragraph and choice . denotes the length of choice .
Fig.18 shows the similarity between paragraph and choice .
Each word in sentences of paragraph is compared to each word in query and choice.
The paragraph-choice (PC) similarity map are created as
39 PAnsAttention = tf.matmul(normal_p,tf.transpose(normal_ans,[0,2,1])) ## batch,max_plot_len*max_len[0],choice*max_len[2])
39 行將 normal_p 與轉置過後的 normal_ans 相乘,得到 PAnsAttension
normal_p 的維度為 ;
normal_ans 的維度為 ;經過轉置後維度是
normal_p 乘上 normal_ans 的維度是
,存為 PAnsAttention
40 PAnsAttention = tf.reshape(PAnsAttention,[batch_size,max_plot_len*max_len[0],choice,max_len[2]]) ##(batch,max_plot_len*max_len[0],choice,max_len[2])
40 行將 PAnsAttention 從三維 reshape 成四維
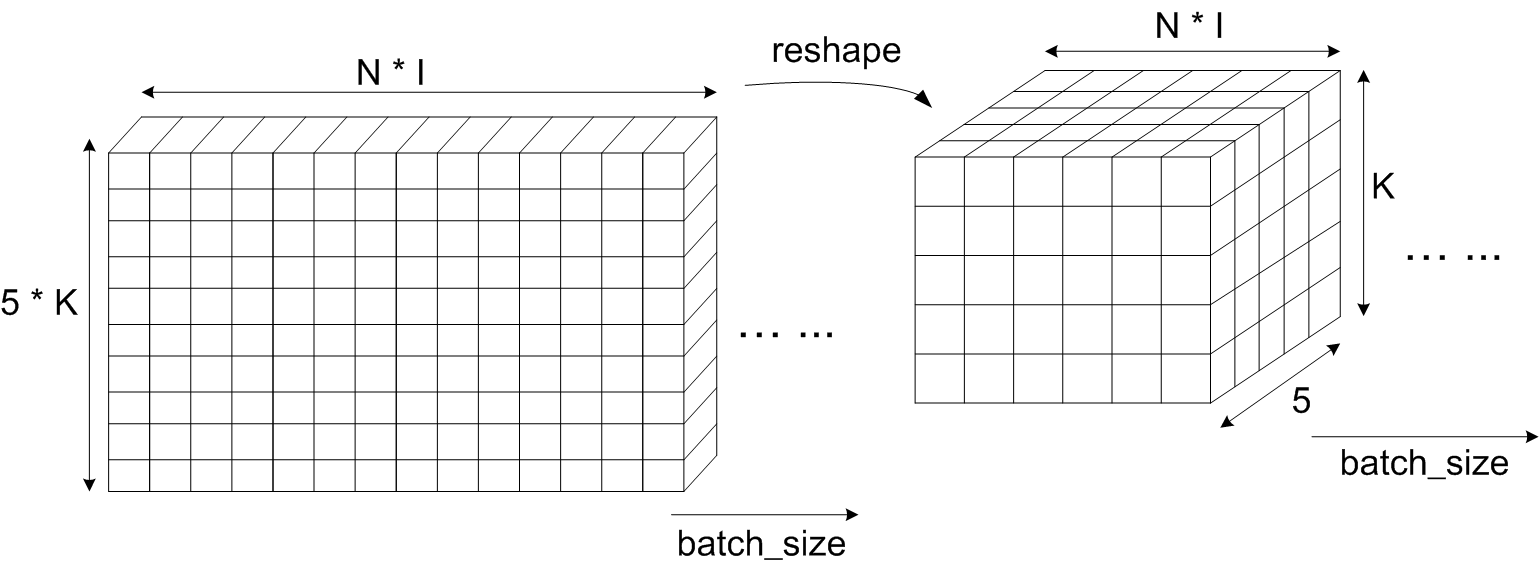 Fig.19 PAnsAttention shape transformation
Fig.19 PAnsAttention shape transformation
Fig.19 shows the PAnsAttention shape transformation from to
41~44行 PAAttention, PBAttention, ..., PEAttention computation
41 PAAttention,PBAttention,PCAttention,PDAttention,PEAttention = tf.unstack(PAnsAttention,axis = 2) ##[batch,max_plot_len*max_len[0],max_len[2]]
44 PAAttention = tf.unstack(tf.reshape(PAAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
41行將 PAnsAttention 以 choice 維度 unstack 為 PAAttention, PBAttention, PCAttention, PDAttention, PEAttention
44行將 PAAttention reshape 後再 unstack。
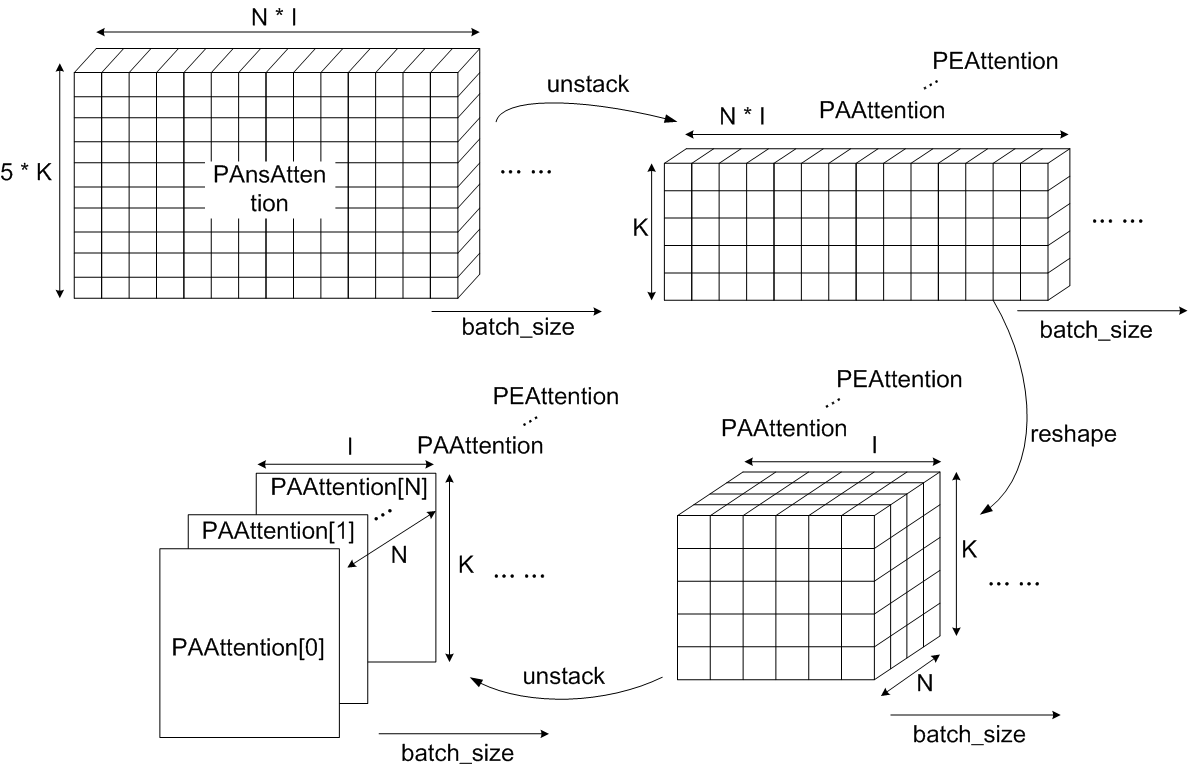 Fig.20 PAAttention...PEAttention shape transformation (note. 將N的維度獨立出來)
Fig.20 PAAttention...PEAttention shape transformation (note. 將N的維度獨立出來)
Fig.20 為 PAnsAttention 經過 41、44行成 PAAttention 的轉換圖。
41 行將 PAnsAttention 以 axis=2 的維度 (choice) unstack,得到 5 個矩陣 (choice=5),各別存入 PAAttention, PBAttention, PCAttention, PDAttention, PEAttention,維度各別是
44 行將 PAAttention 的維度 reshape 為 ,再將 axis=1 的維度 (N) unstack,產生 個維度為 的矩陣
45 PBAttention = tf.unstack(tf.reshape(PBAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
46 PCAttention = tf.unstack(tf.reshape(PCAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
47 PDAttention = tf.unstack(tf.reshape(PDAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
48 PEAttention = tf.unstack(tf.reshape(PEAttention,[batch_size,max_plot_len,max_len[0],max_len[2],1]),axis = 1) ##[batch,max_len[0],max_len[2],1]
同理,第 45~48 行的 PBAttention ... PEAttention 維度為 的矩陣。
Reference
[1] tf.nn.l2_normalize https://www.tensorflow.org/api_docs/python/tf/nn/l2_normalize
[2] tf.nn.l2_normalize的使用 https://blog.csdn.net/abiggg/article/details/79368982
[3] tf.reshape https://www.tensorflow.org/api_docs/python/tf/reshape