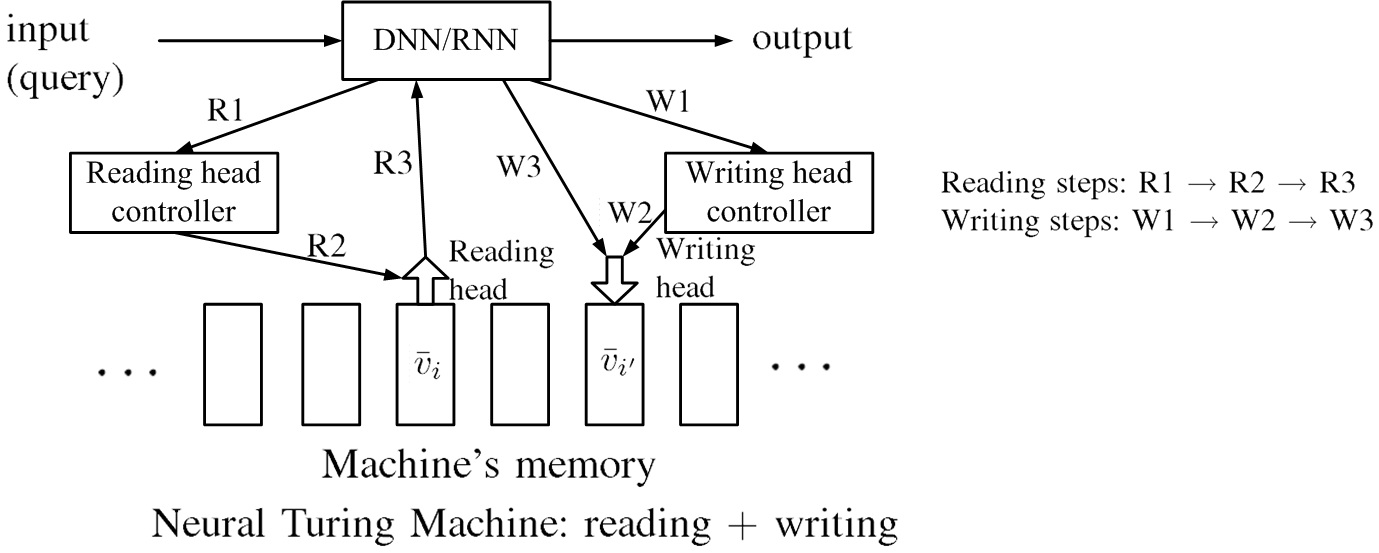
 圖十、Attention-based model示意圖。讀取資訊步驟為:R1. 發訊給reading head controller。R2. reading head controller決定reading head之位置。R3. 網絡讀取記憶體中的向量資訊進入網絡。寫入步驟為:W1. 發訊給writing head controller。W2. writing head controller決定writing head之位置。W3. 網絡寫入記憶體中的向量資訊。
圖十、Attention-based model示意圖。讀取資訊步驟為:R1. 發訊給reading head controller。R2. reading head controller決定reading head之位置。R3. 網絡讀取記憶體中的向量資訊進入網絡。寫入步驟為:W1. 發訊給writing head controller。W2. writing head controller決定writing head之位置。W3. 網絡寫入記憶體中的向量資訊。
圖十顯示Attention-based model示意圖。Attention-based model能夠根據輸入,自動決定記憶中所需的相關資訊,讀取至網絡,得到理想輸出,此能力是經過訓練後得到。讀取資訊步驟為:R1. 發訊給reading head controller。R2. reading head controller決定reading head之位置。R3. 網絡讀取記憶體中的向量資訊進入網絡。網絡讀取資訊時,可以依序從不同記憶體讀取資訊。寫入步驟為:W1. 發訊給writing head controller。W2. writing head controller決定writing head之位置。W3. 網絡寫入記憶體中的向量資訊。同時具備讀寫功能的attention-based model稱為Neural Turing Machine。
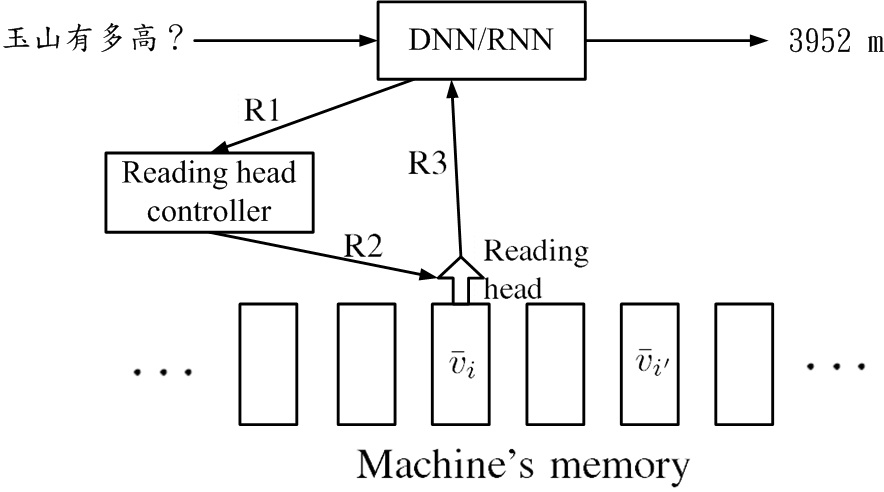 圖十一、attention-based model範例。輸入問題「玉山有多高?」機器讀取資訊後,輸出「3952m」。
圖十一、attention-based model範例。輸入問題「玉山有多高?」機器讀取資訊後,輸出「3952m」。
圖十一顯示attention-based model範例。輸入問題「玉山有多高?」機器讀取資訊後,輸出「3952m」。機器讀取資訊可以是iterative,它可以先讀出v¯i再讀出v¯i′,把這些資訊收集起來,最後給出答案。
托福聽力測驗
 圖十二、托福聽力測驗題目之示意圖。
圖十二、托福聽力測驗題目之示意圖。
圖十二顯示托福聽力測驗題目之示意圖。
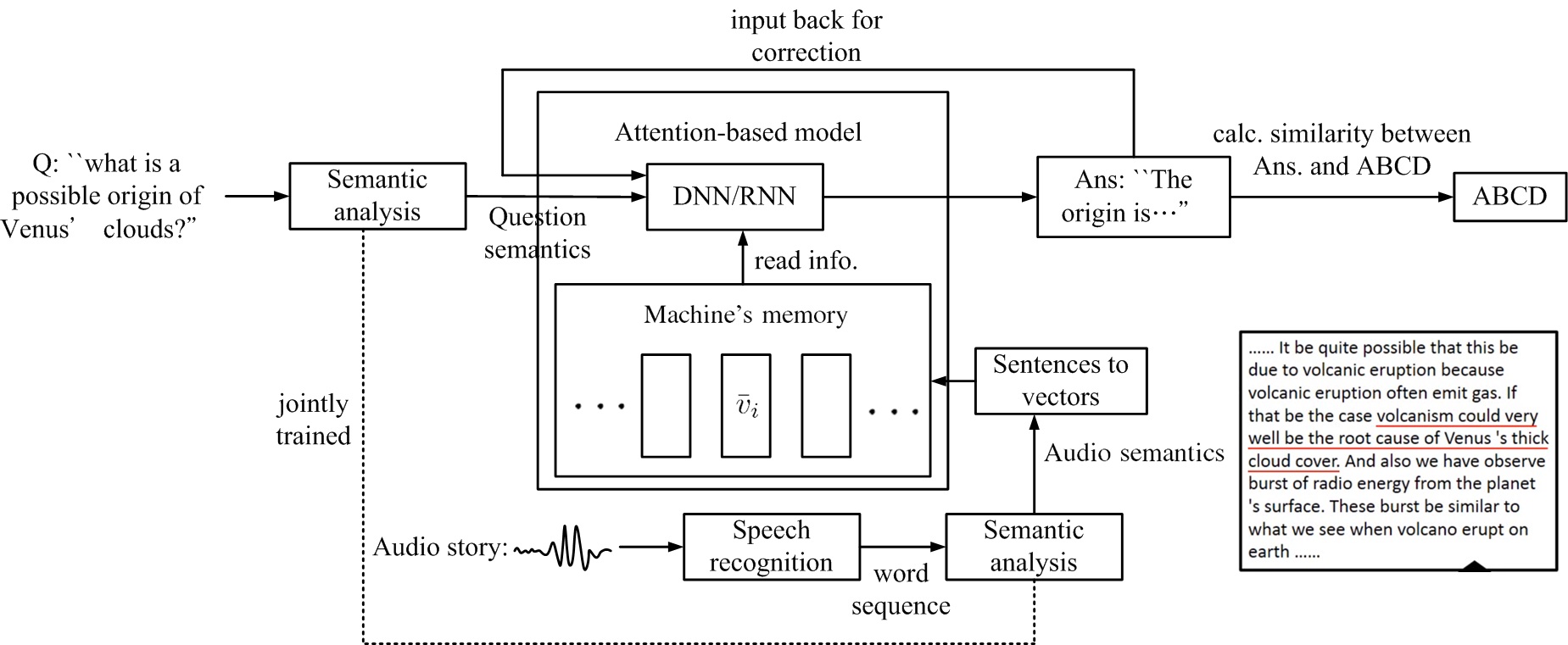 圖十三、托福聽力測驗之注意力模型架構。
圖十三、托福聽力測驗之注意力模型架構。
圖十三顯示托福聽力測驗之注意力模型架構。機器聽語音描述(Audio story),做語音辨識轉成字串,再經語意分析得語音語意,再轉成向量,存入記憶體,供attention-based model取用。機器讀進測驗問題(Q:"what is a possible origin of Venus' clouds?")後,進行語意分析,得問題語意,輸入至attention-based model 的中央處理器(DNN/RNN),中央處理器根據記憶體中之資訊,作出回答(Ans: "The origin is ..."),此答案可再輸入回中央處理器,修正答案。最後再計算答案與ABCD選項間的相似度,選出最相似的選項。整體架構,是一個神經網絡,問題語意(Question semantics)與語音語意(Audio semantics)是聯合訓練(jointly trained),而語音辨識(speech recognition)是另一獨立神經網絡。
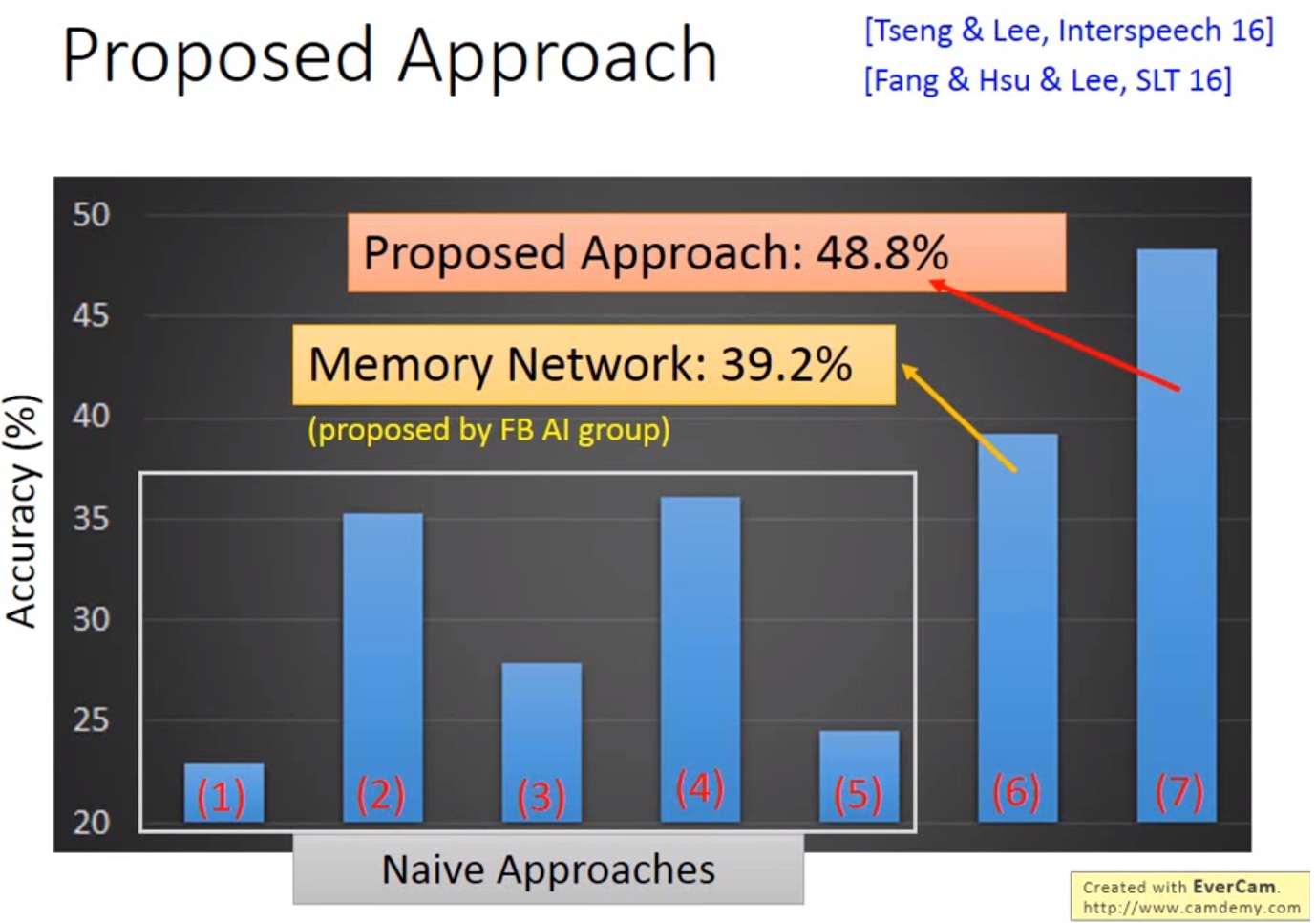 圖十四、托福聽力測驗之不同方法結果比較。
圖十四、托福聽力測驗之不同方法結果比較。
圖十四顯示托福聽力測驗之不同方法結果比較。方法(1)-(5)是naive,即不管文章內容,直接看問題選答案。隨意猜的結果是25%。方法(2)--找最短的答案-- 或是 方法(4)--比對一選項和另外三個選項語義相似度,若某選項與其它三選項的語義相似度最高,則選它--,這兩種方法可以到達35%。方法(4)與直覺是相反的,是官方故意如此設計。Memory Network 可以達到39.2%。proposed approach:可以到達48.8%。
[0]
H. Y. Lee, ML lecture #21-2, RNN part II
, at