QACNN Algorithm
MM 0605/2018
In question answering task, a reading paragraph Praw, a query Qraw and several answer choices Craw are given.
The target of the model is to choose a correct answer from multiple choices based on information of Praw and Qraw.

Fig.1 Overview on QACNN model. y¯ denotes the probability of choices A, B, C and D.
Fig.1 shows the pipeline overview of QACNN.
The embedding layer is used to transform Praw, Qraw, Craw into word embedding P, Q, C.
The compare layer generates paragraph-query similarity map PQ and paragraph-choice similarity map PC.
The QACNN consists of two staged-CNN architecture.
The first stage projects word level feature into sentence-level, and the second stage projects sentence-level feature into paragraph-level.
The output of first stage are paragraph's sentence features based on the query r¯¯PQ and choice r¯¯PC
r¯¯PQ=[r¯1PQ,⋯,r¯nPQ,⋯,r¯NPQ] and r¯¯PC=[r¯1PC,⋯,r¯nPC,⋯,r¯NPC].
n is the index for sentence, and N is the total number of sentence in paragraph.
The output of second stage is answer feature r¯.
Each choice has its corresponding answer feature.
Every choice answer feature, r¯A, r¯B, r¯C, r¯D, are inputs to prediction layer, and the output denotes the probability of choices A, B, C and D, respectively.
y¯=[pA,pB,pC,pD].
Similarity Mapping layer
Similarity mapping layer is composed of two part : embedding layer and compare layer.
Given a paragraph Praw (with N sentences), a query Qraw, and a choice Craw, the embedding layer transforms every words in Praw, Qraw and Craw into word embedding :
P={p¯ni}i=1,n=1I,N : N is the total number of sentence in paragraph, and I is the total number of words in each sentence.
Q={q¯j}j=1J : Query is considered as one sentence.
C={c¯k}k=1K : choice is considered as one sentence.
The sentences in all the paragraphs have the same length by padding.
J is the total number of words in query sentence. K is the total number of words in choice sentence.
p¯ni, q¯j and c¯k are word embeddings.
Word embedding can be obtained by any type of embedding technique, such as RNN, sequence-to-sequence model, Word2Vec, etc.
The pre-trained Glo Ve word vectors is adopted as the embedding without further modification [3].
The compare layer compares each paragraph sentence Pn to Q and C at word level separately.
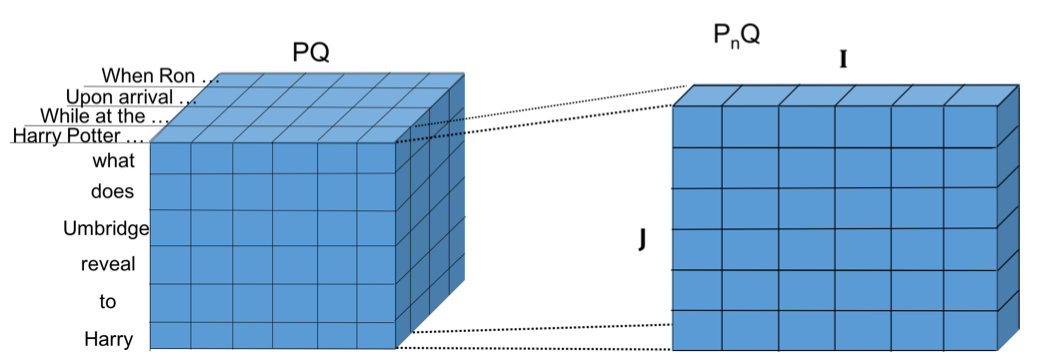
Fig.2 Similarity map between paragraph P and query Q. I denotes the length of each sentence Pn, J denotes the length of query Q.
Fig.2 shows the similarity between paragraph P and query Q. I denotes the length of each sentence Pn. J denotes the length of query Q. PnQ={cos(p¯ni,q¯j)}i=1,j=1I,J
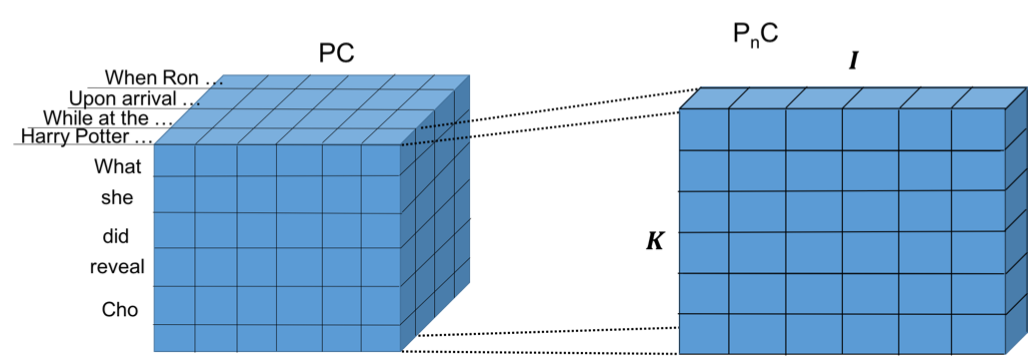 Fig.3 Similarity map between paragraph P and choice C. K denotes the length of choice C.
Fig.3 Similarity map between paragraph P and choice C. K denotes the length of choice C.
Fig.3 shows the similarity between paragraph P and choice C. K denotes the total number of words in choice sentence C.
Each word in sentences of paragraph is compared to each word in query and choice.
PnC={cos(p¯ni,c¯k)}i=1,k=1I,K
Two similarity map, paragraph-query (PQ) and paragraph-choice (PC) similarity map are created as
PQ=[P1Q,P2Q,⋯,PNQ]∈RN×J×I
PC=[P1C,P2C,⋯,PNC]∈RN×K×I
QACNN Layer
QACNN contains a two-staged CNN combined with query-based attention mechanism.
An attention convolutional matching layer is used to integrate two similarity maps.
QACNN layer is used to learn the location relationship pattern.
Each stage comprises two major part: attention map and output representation.
Attention Map of First stage
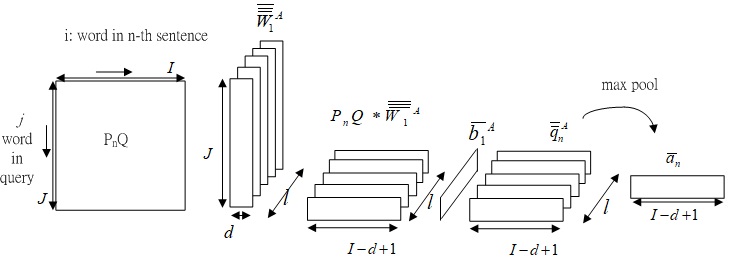
Fig.4-0 First stage CNN attention part, from PnQ to word-level attention map a¯n.
Fig. 4-0 shows the derivation of word-level attention map a¯n from PnQ.
PnQ∈RJ×I is n-th sentence slice PnQ∈RJ×Iin PQ , and CNN is applied on PnQ with convolution kernel W¯¯¯1A∈RJ×l×d . d and l represent width of kernel and number of kernel, respectively.
The superscript A denotes attention map, and the subscript 1 denotes the first stage CNN.
The generated feature q¯¯nA∈Rl×(I−d+1) is expressed as
q¯¯nA=sigmoid(W¯¯1A∗PnQ+b¯1A)
where b¯1A∈Rl is the bias.
With W¯¯1A would learn the query syntactic structure and give weight to each paragraph's location. Sigmoid function is chosen as activation function in this stage.
Max pooling is performed to q¯¯nA perpendicularly to find the largest weight between different kernels in the same location, using max pool kernel shaped l, and then generate word-level attention map a¯n∈RI−d+1 for each sentence.
a¯n=max pool(q¯¯nA), note q¯¯nA∈Rl×(I−d+1) and a¯n∈RI−d+1.
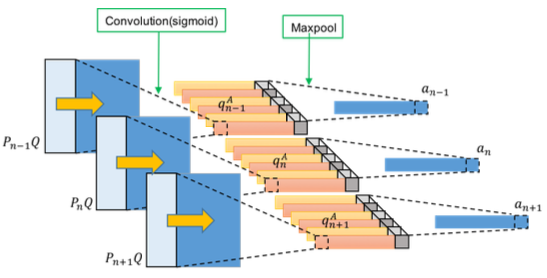
Fig.4 First stage CNN attention part. Each paragraph sentences are used to generate its corresponding word-level attention map a¯n, n=1,2,⋯,N.
Fig.4 shows the architecture of the attention map in first stage CNN, and all sentences in paragraph are used.
Output Representation of First Stage
The paragraph's sentence features based on the query (r¯¯PQ) and the choice (r¯¯PC) are derived at first stage.
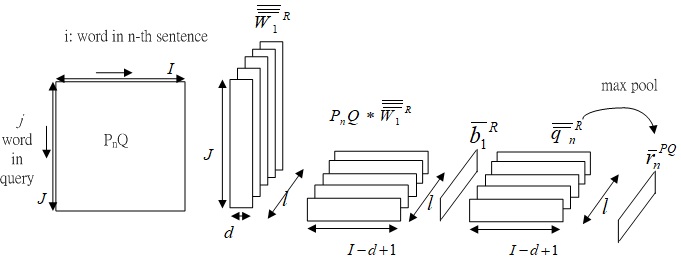
Fig.5-0 Derivation of paragraph feature based on query, r¯nPQ.
Fig.5-0 shows the derivation of paragraph feature based on query, r¯nPQ.
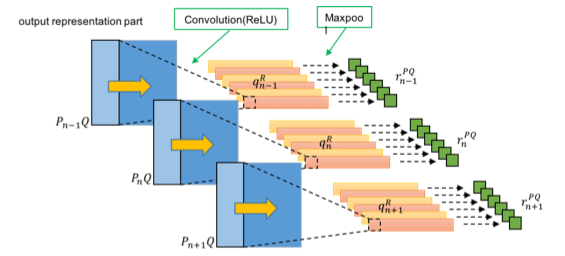
Fig.5 All paragraph's sentence feature based on query, r¯¯PQ=[r¯1PQ,⋯,r¯nPQ,⋯,r¯NPQ].
Fig.5 shows all paragraph's sentence feature based on query, r¯¯PQ=[r¯1PQ,⋯,r¯nPQ,⋯,r¯NPQ].
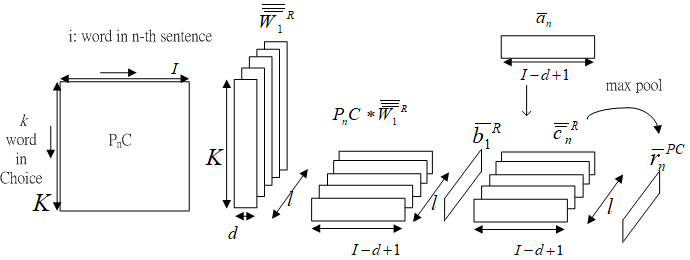
Fig.6-0 Derivation of paragraph's sentence feature based on choice, r¯nPC.
Fig.6-0 shows the derivation of paragraph's sentence feature based on choice, r¯nPC.
.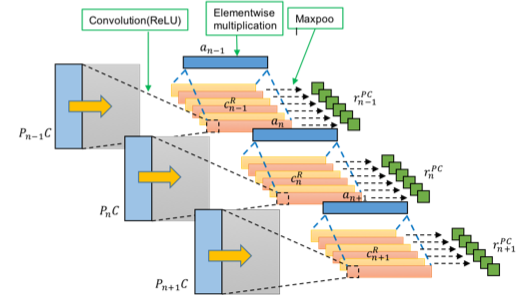
Fig.6 All paragraph's sentence feature based on choice, r¯¯PC=[r¯1PC,⋯,r¯nPC,⋯,r¯NPC].
Fig.6 shows all paragraph's sentence feature based on choice, r¯¯PC=[r¯1PC,⋯,r¯nPC,⋯,r¯NPC].
r¯¯PQ and r¯¯PC are two output representation part of first-stage CNN architecture.
Kernels W¯¯¯1R∈Rl×K×d and bias b¯1R∈Rl are applied to PnQ to acquire query-based sentence features.
q¯¯nR=ReLU(W¯¯¯1R⊗PnQ+b¯1R)∈Rl×(I−d+1)
Identical kernels W¯¯¯1R∈Rl×K×d and bias b¯1R∈Rl are applied to PnC to aggregate pattern of location relationship and acquire choice-based sentence features. The superscript R denotes output representation
c¯¯nR=ReLU(W¯¯¯1R⊗PnC+b¯1R)=⎣⎡(c¯n,1R)t⋮(c¯n,ℓR)t⎦⎤∈Rl×(I−d+1)
c¯¯nR is multiplied by the word-level attention map a¯n∈RI−d+1 through the first dimension.
c¯¯nR=⎣⎡(c¯n,1R)t⊙a¯n⋮(c¯n,ℓR)t⊙a¯n⎦⎤,
The max pool operations are applied on q¯¯nR∈Rl×(I−d+1) and c¯¯nR∈Rl×(I−d+1) horizontally with kernel shape (I−d+1) to get the query-based sentence features r¯nPQ∈Rl and choice-based sentence features r¯nPC∈Rl.
r¯nPQ=max pool(q¯¯nR)
r¯nPC=max pool(c¯¯nR)
Attention map of second stage
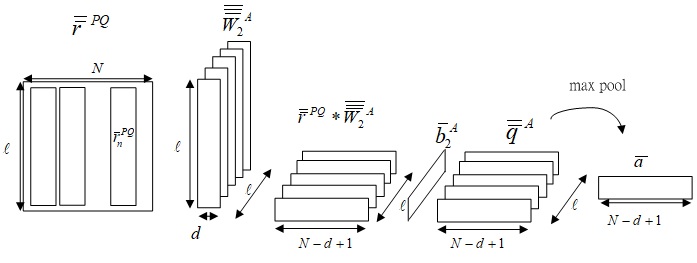
Fig.7-0 Derivation of sentence-level attention map a¯ from r¯¯PQ.
Fig.7-0 shows the derivation of sentence-level attention map a¯ from query-based sentence features r¯¯PQ.
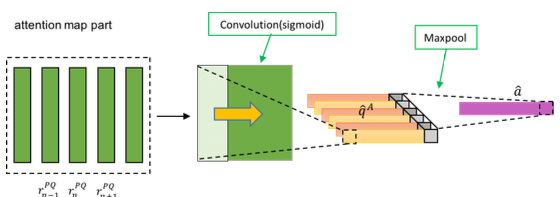
Fig.7 Derivation of sentence-level attention map a¯ from r¯¯PQ.
Fig.7 shows the derivation of sentence-level attention map a¯ from query-based sentence features r¯¯PQ.
r¯¯PQ=[r¯1PQ,r¯2PQ,⋯,r¯NPQ] is the input of second stage CNN, and will be further refined by CNN with kernel W¯¯¯2A∈Rl×d×l and generates intermediate features q¯¯A∈Rl×N−d+1.
q¯¯A=sigmoid(W¯¯¯2A∗r¯¯PQ+b¯2A)
The max pool operation is applied on q¯¯A with kernel shaped l, and the sentence-level attention map a¯∈RN−d+1 is obtained.
a¯=max pool(q¯¯A)
Output Representation of Second Stage
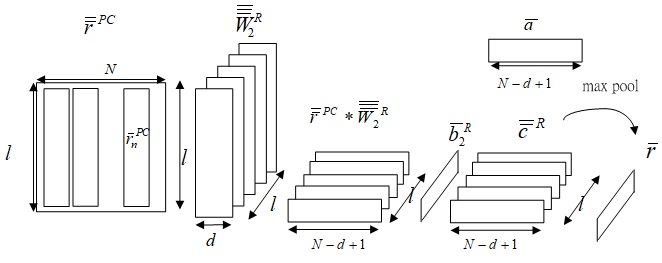
Fig.8-0 Derivation of answer feature r¯ from r¯¯PC.
Fig. 8-0 shows the derivation of answer feature r¯ from r¯¯PC.
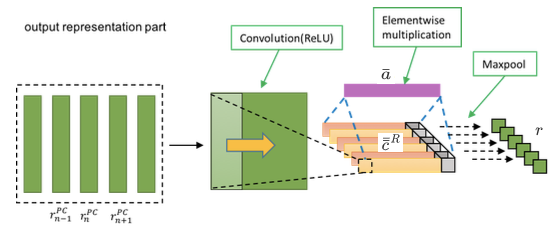
Fig.8 Derivation of answer feature r¯ from choice-based sentence feature r¯¯PC .
Fig.8 shows the output representation part of the second stage.
The output representation part of the second stage has two input: sentence-level attention map a¯ and sentence-level features r¯¯PC=[r¯1PC,r¯2PC,r¯NPC].
The c¯¯R and answer feature r¯ is obtained as
r¯={max(ctR⊙a)}t=1l
where
c¯¯R=ReLU(W¯¯¯2R∗r¯¯PC+b¯2R)
and W¯¯¯2R∈Rl×l×d, b¯2R∈Rl, and c¯¯R∈Rl×(N−d+1). The output representation of certain choice r¯∈Rl is the final output of QACNN Layer.
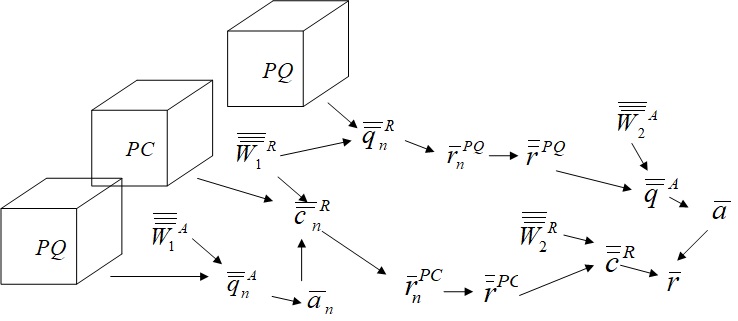
Fig.9 Overall data flow of QACNN.
Prediction Layer
Prediction layer is the final part of QACNN. r¯A∈Rl is used to represent the final output representation of the A-th choice.
r¯A,r¯B,r¯C,r¯D is passed to two-fully-connected layer and compute probability for each choice using softmax
R¯¯=[r¯A,r¯B,r¯C,r¯D].
The output vector is the probability of each choices
y¯=⎣⎢⎢⎡pApB⋮pE⎦⎥⎥⎤=softmax(W¯¯o(tanh(W¯¯pR¯¯+b¯p))+bo).
where W¯¯p∈Rl×l, b¯p∈Rl, W¯¯o∈Rl×Mc and bo∈RMc.
Two fully-connected layer are applied.
W¯¯P and W¯¯o are the weight matrix of first and second fully-connected layer, respectively.
b¯p and b¯o are the bias of first and second fully-connected layer, respectively.
Mc is the number of choices.
Hyperbolic function can be expressed as
tanhx=ex+e−xex−e−x.
[0]
Query-based Attention CNN for Text Similarity Map
Tzu-Chien Liu, Yu-Hsueh Wu, Hung-Yi Lee, 2017.
[1]
M.Tapaswi, Y.Zhu, R. Stiefelhagen,
"Movieqa: Understanding stories in movies through question-answering," IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2]
oS. Wang and J. Jiang, " A compare-aggregate model for matching text sequences," 1611.01747, 2016.
[3]
J. Pennington, R. Socher, and C. Manning, "Glove: Global vectors for word representation," in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp.1532-1543.