Acoustic-Domain Setence Segmentation
語音辨識前處理
在進行辨識之前,有兩個工作要進行
- 對文句進行標音。例如:中文標示注音、英文標示音標。
- 根據需求,產生辨識網路,進行搜尋。
文字標音
辨識網路
聲學模型(Acoustic Model)
一般語音辨識中,會以聲學模型來作為語音辨識的基本單位,因此要進行語音資料的訓練來求取聲學模型的參數時,就必須確認聲學模型的結構。以下介紹幾個常用的名詞
- 聲學模型(Acoustic Model) 使用於HMM的抽象單位,通常一個聲學模型包含數個狀態。音節或音素可以拿來作為一個聲學模型。
- 音節(Syllables) 完整發音的單位,以中文來說,一個字元對應一個音節;以英文來說,一個詞彙可以對應到數個音節,e.g. tomorrow有三個音節。
- 音素(Phoneme) 簡稱Phone,是發音的最小單位,例如『大』可以拆成ㄉ和ㄚ兩個音素。音素的拆解並非一成不變,例如滑母音,就會將一個注音拆成兩個音素。例如ㄞ、ㄟ、ㄠ、ㄡ等,這幾個母音在發音的過程,都會呈現連續變化。
- Monophone 以單一音素作為一個聲學模型,例如ㄇ。
- Biphone 以連續兩個音素作為聲學模型,通常是RCD(Right-context dependent),例如將ㄇ出現於ㄇㄚ和ㄇㄧ視為兩個不同的聲學模型。
- Triphone 以連續三個音素作為聲學模型,例如將ㄨ在ㄎㄨㄢ及ㄍㄨㄤ是為兩個不同的聲學模型。
以我們常用的語音辨識系統而言,是以biphone為聲學模型的單位,由音節(Syllable)到Mixture的階層架構,可以由Figure 1示意圖表示
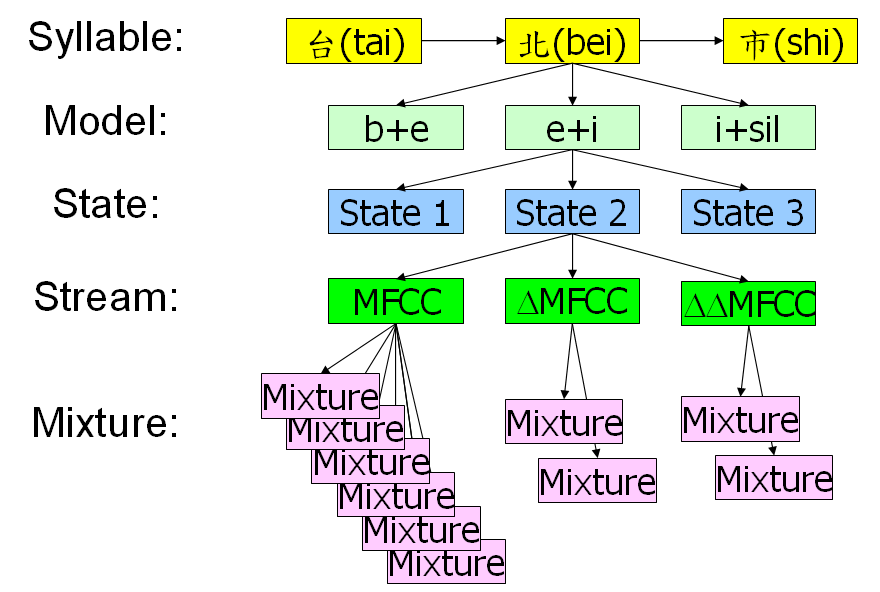 Figure 1 Hierarchy of Bi-phone Speech recognition System
Figure 1 Hierarchy of Bi-phone Speech recognition System
上圖中,每個音節會用兩兩連續的音素分開,例如:北(bei)變成三個b+e, e+i, i+sil的Model,sil是特殊的音素,代表結束。每個Model又可以分成3個state,每個state又分成3個stream,分別是MFCC、MFCC、MFCC。MFCC使用6個mixture來建模(重要的語音特徵),MFCC用2個mixture來建模,MFCC用2個mixture來建模。
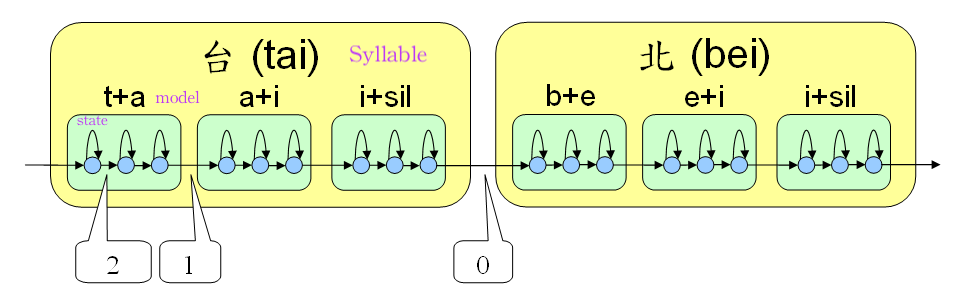 **Figure 2
**Figure 2
Figure 2顯示由辨識網路及HMM的觀點來看,系統的示意圖。其中用0,1,2標註三種不同的transition Type 0 (transition between syllable)、Type 1 (transition between model)、Type 2 (transition between state)。